
LOCATING KNOWLEDGE THROUGH AUTOMATED
ORGANIZATIONAL CARTOGRAPHY [AUTOCART]
Mounir Kehal, Sandrine Crener, Patrice Sargenti
CSITDS Research Group
International University of Monaco
Monte Carlo, Principality of Monaco
Keywords: Knowledge Management, Knowledge Maps, Neural Networks, Organizational Cartography, Semantic
Relevance, Unsupervised learning, Kohonen Networks, Self-Organizing Maps (SOMs).
Abstract: The Post-Globalization aeon has placed businesses everywhere in new and different competitive situations
where knowledgeable, effective and efficient behaviour has come to provide the competitive and
comparative edge. Enterprises have turned to explicit- and even conceptualising on tacit- Knowledge
Management to elaborate a systematic approach to develop and sustain the Intellectual Capital needed to
succeed. To be able to do that, you have to be able to visualize your organization as consisting of nothing
but knowledge and knowledge flows, whilst being presented in a graphical and visual framework, referred
to as automated organizational cartography. Hence, creating the ability of further actively classifying
existing organizational content evolving from and within data feeds, in an algorithmic manner, hence
potentially giving insightful schemes and dynamics by which organizational know-how is visualised. It is
discussed and elaborated on most recent and applicable definitions and classifications of knowledge
management, representing a wide range of views from mechanistic (systematic, data driven) to a more
socially (psychologically, cognitive/metadata driven) orientated. More elaborate continuum models, for
knowledge acquisition and reasoning purposes, are being used for effectively representing the domain of
information that an end user may contain in their decision making process for utilization of available
organizational intellectual resources.
1 INTRODUCTION
Approaches to manage knowledge have been largely
based on various combinations of business practices,
management strategies, and subject related research.
Examples of these approaches are innumerable and
include organizational learning, the learning
organization, total quality management (TQM),
business process re-engineering (BPR), quality
circles (QCs), and so on. Of more recent times,
especially in the last decade or so, Knowledge
Management (KM) has started to emerge as
multidisciplinary area of interest in academia and
business worlds. We cover and provide a framework
of how knowledge may be modelled; thus specified,
for the development of information systems
supporting attempts to manage knowledge.
2 KNOWLEDGE MANAGEMENT
LITERATURE SYNOPSIS
While definitions of any subject matter can be
helpful in regard to clarifying the scope and depth of
the subject under consideration, they can also be
notoriously difficult to articulate. Some authors in
the field have tried to provide a significant and
diverse range of definitions for knowledge.
Hedlund, for example, used ‘knowledge’ and
‘information’ interchangeably and although he
acknowledged that they should be distinguished, his
use amounts to treating them as identical (Hedlund,
1994). Nonaka and his colleagues describe
knowledge as ‘a meaningful set of information that
constitutes a justified true belief and/or an embodied
technical skill (Nonaka et al, 1996). We may
consider Knowledge Management as a framework
providing the ability to utilize the available
knowledge resources effectively, and in a timely
351
Kehal M., Crener S. and Sargenti P. (2006).
LOCATING KNOWLEDGE THROUGH AUTOMATED ORGANIZATIONAL CARTOGRAPHY [AUTOCART].
In Proceedings of the Eighth International Conference on Enterprise Information Systems - AIDSS, pages 351-355
DOI: 10.5220/0002467903510355
Copyright
c
SciTePress

manner, for organizational benefit and advantage.
Essentially, it may be evident in organizational
processes, the combination of data and information
sources, the processing capacity of IT solutions,
people, and the creation and innovative sharing of
knowledge throughout the organization. Such
framework would inevitably lead to a true managing
of knowledge, on a contextual basis that maximizes
the utilization behind available know-how, -why, -
what, -when, -where, -who.
2.1 Knowledge Category Models
Such types of model categorize knowledge into
discrete elements. For instance, Nonaka’s model is
an attempt at giving a high level conceptual
representation of KM and essentially considers KM
as knowledge creation process. Figure 1 shows
Nonaka’s knowledge management model reflecting
knowledge conversion and dissemination modes.
To
Tacit Explicit
Tacit
From
Explicit
Figure 1: Nonaka and Takeuchi’s Knowledge
Management model (Nonaka et al, 1995).
As can be observed from the figure above,
knowledge would be composed of two constituents,
Tacit and Explicit. Tacit Knowledge is defined as
non-verbalized, intuitive, and unarticulated. Explicit
or articulated knowledge is specified as being
formally structured in writing or some pre-defined
form. Nonaka’s model assumes tacit knowledge can
be transferred through a process of socialization into
tacit knowledge and that tacit knowledge can
become explicit knowledge through a process of
externalisation. The model also assumes that explicit
knowledge can be transferred into tacit knowledge
through a process of internalisation, and that explicit
knowledge can be transferred to explicit knowledge
through a process of combination. In relation to the
knowledge conversion model transcribed in Figure
1, we believe that knowledge creation undergoes a
nested set of computerized processes [explicit] and
accompanying practices [tacit], allowing as well for
its interlinkages and cross levelling to diverse
specialist areas of expertise and to those it would
tend to restrain, as knowledge would be considered
as highest level available for awareness on the
object of concern. Hence, aim is rather to acquire
automatically, represent visually, and reason
collectively on textual content contained. Thus, a
computationally mediated tool is conceptualised
upon subsequently, being referred to as
AUTOCART, AUTomated Organizational
CARTography, supporting knowledge evolution
studies, knowledge sharing and corresponding flow
representation.
3 ORGANIZATIONAL
CARTOGRAPHY AND
KNOWLEDGE MAPPING
According to Oxford English Dictionary,
Cartography is the drawing of charts or maps. Our
aim is to generate cartograms representing stored
content attained from specialist data feeds. Figure 4
represents, the characteristics by which ‘information
in context’, knowledge, is dealt in the process of its
acquisition. From internal to external sources, and
from being data that is interpreted, to one that
models certainty with intent to validate its semantics
by knowledge workers.
Certainty
Lo Med Hi
Hi Hi
Internal Med Med External
Lo Lo
Lo Med Hi
Interpretation
Figure 4: Knowledge Acquisition Spectrum
.
Hence from Figure 4, Certainty, Internal,
Interpretation and External are all knowledge
instances attained by means of capturing tacit and
explicit knowledge, with possibly varying values,
states and roles, from knowledge workers, and the
levels of processing achieved by a mediated
computation. Figure 5, below reflects the nature
anticipated by such processing in a framework that
models parameters of consideration from which
knowledge may be viewed, or rather represents and
Socialization Externalisation
Internalisation Combination
ICEIS 2006 - ARTIFICIAL INTELLIGENCE AND DECISION SUPPORT SYSTEMS
352

embeds itself in the form of an [intangible object]
action, thinking, [tangible object] archetype, human.
Action
Lo Med Hi
Hi Hi
Archetype Med Med Human
Lo Lo
Lo Med Hi
Thinking
Figure 5: Knowledge Conversion Spectrum
.
4 SYSTEMATIC VIEW OF
AUTOCART
The knowledge spectrum models covered above
would provide us with a framework for the
development of AUTOCART, represented at a finer
degree of abstraction in Figure 6 AUTOCART
Meta level model, by use of dependency
relationships and associations among processes
and/or instances of objects. The Relationships and
associations are stereotyped as <<refine>>, in
accordance with the UML (Unified Modelling
Language) notation (Booch et al, 1999).
Figure 6: AUTOCART, Meta Level model.
These dispositions of knowledge comprise parts of
the Knowledge Constituents, which embody the
‘raw’ material of the organisation in question.
Therefore, a generalisation relationship is used to
depict the more specific kinds of knowledge
elements in relation to the ‘whole’. Knowledge
Constituents undergo some form of filtering, based
on criteria derived from the document specification
model and partly determined by the textual content.
These functional processes are modelled in the next
model, Figure 7, which focuses on functional
requirements at a lower level of processing. In like
manner, each knowledge element, texts in this case,
is assigned its textual category, primarily
determined by its textual contents opted for in a pre
defined algorithmic manner, using principles of
Kohonen Nets, for instance; and directions towards
an automated learning environment through
Certainty
Explicit and
Tacit
Internal
External
Inter
p
retation
Filter
/ Textual content
Knowledge
Constituents
Text Categories
/ Document specification
m
ode
l
s
Knowledge
Nodes
Human Innovation
Archetype Action
undergo
assign to
form
<<Refine>>
/ or generate
LOCATING KNOWLEDGE THROUGH AUTOMATED ORGANIZATIONAL CARTOGRAPHY [AUTOCART]
353
induction and hence possible alterations in terms of
activation and threshold functions deterministic
weights, leading to toggling between unsupervised
and system-supervised learning for a networked
representation of data. To establish the textual
category is vital in classifying textual content and,
among with characteristics such as links, directly
added from the filtering process, forming the basis
of a knowledge node, being interlinked using a
generalisation relationship, following the notation of
UML (Booch et al, 1999).
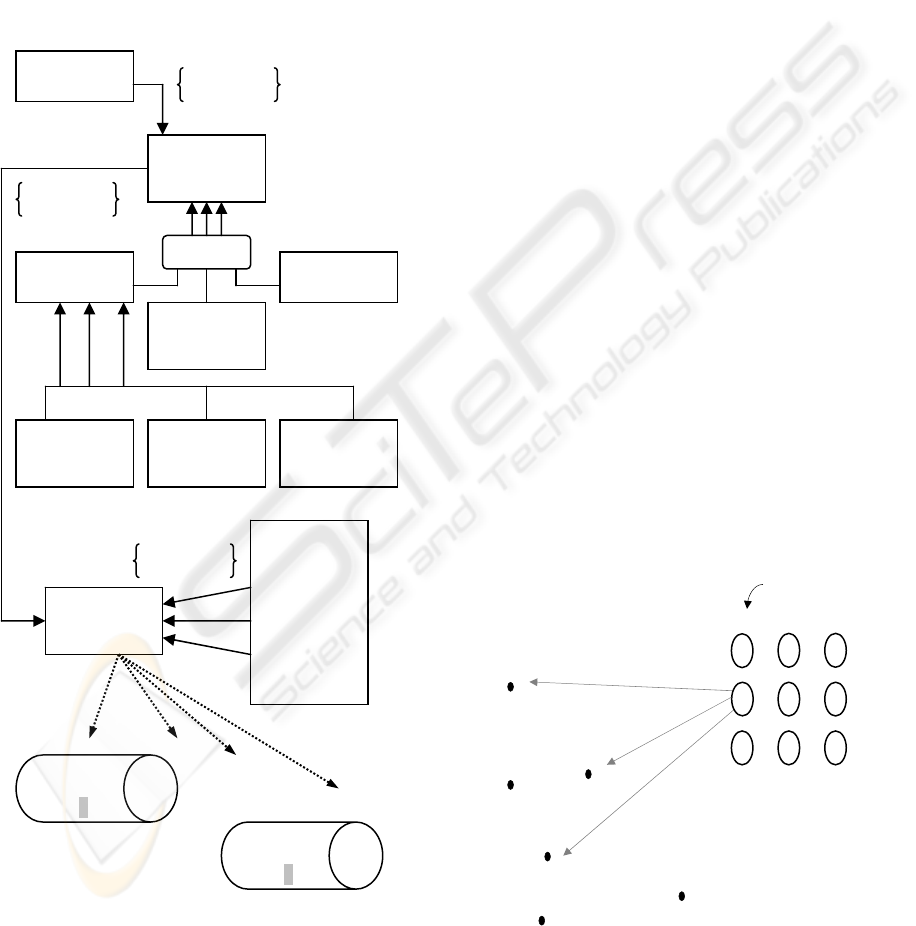
Figure 7: AUTOCART, process level.
At process level, Data Elements within Knowledge
Constituents are to be filtered and then accordingly
classified. The overall aim is to surface the latent
semantic structure of the Knowledge Constituents.
The filtering process is primarily based on a
document specification model – incorporated in
Figure 6 – which is an aggregate of textual
components. These can be identified as being the
actual text of the document, annotation apparent in
the document and the links present. The latter can
be further specialised into association Links –
pointing to and from related documents – and
classification Links, including domain, project and
user specific links, and other relationship links as a
build-up of the data semantics is incurred based on
semantics of content. Once text components have
been determined, each text is assigned a Text
Category, driven by the cohesive relation between
the document specification model and the textual
content. In case the category is not readily known, a
Category Generator is invoked, whereby assigns a
category in an algorithmic manner. Effectively, the
process of textual categorisation and filtering results
in assigning some kind of index to each textual input
– in the form of data entries per document – in an
attempt to reveal the latent semantic structure
underlying the organisational knowledge elements.
AUTOCART at process level model, portrayed in
Figure 7, provides an architectural view of the
anticipated processing for generation of Knowledge
Nodes, mainly through links – obtained from the
filtering process – and latent data semantics as
determined by specification and categorization of
the input data, from designated data streams.
Figure 8: iMap (intermediate state diagram), illustration
through Kohonen Nets.
11
22 23
13
33
21
32 31
12
t.c. 1
t.c. 2
t.c. 5
t.c. 3
t.c. 6
t.c. 4
Knowledge
nodes
Textual Data
Feeds
Textual
Content
Hyperlinks
Textual
Content
Annotation
Association
Links
Classification
Links
Relationship
Links
Data
Semantics
- What
- Who
- Where
- When
- Why
- How
Text Category
refine to
contains
Knowledg
e node
1
relate to
Knowledg
e node
n
assign to
ICEIS 2006 - ARTIFICIAL INTELLIGENCE AND DECISION SUPPORT SYSTEMS
354

Figure 8 demonstrates the modelling of knowledge
nodes generation, after textual content (t.c. = 1…n)
have been categorized, following method given by
Kohonen Nets, for instance (Kohonen, 1990). The
categories of text produced by AUTOCART, in a
way illustrated in Figure 8, forms the core of the
knowledge nodes, accompanied by reference
information such as extracted documented
experience within the organisation, related
communities of practice and referenced expertise.
This enhanced structure serves our purpose, which
is not only the administration of electronically
available information, but also a viable
representation of the intellectual environment
aiming to make information actionable and relevant
within contexts of expertise coverage. Put simply,
we aim to combine all valuable reference
information in a framework to which everyone can
relate to, effectively leveraging the organisational
intellectual assets. These knowledge nodes shall be
of little value unless presented in an illustrative
form. Therefore, it was chosen to generate
cartograms to reflect knowledge instances
comprising such nodes. Our approach is to be
heavily based on the concept of self-organising
maps (SOM). Predefined text categories, either
domain or project or user specific, play the role of
input vectors while knowledge nodes correspond to
neurons. The main concept behind this analogy is to
place the winner topologically in the text categories
space, according to its relevance for containment of
the surrounding text categories. Figure 8 is
representative of the intermediate step of this
approach.
5 CONCLUSIONS AND
OUTLOOK
It is believed that automated organizational
cartography and knowledge modeling with a
computationally assisted model, inline with
considerations for its evolution studies, particularly
focusing on utilizing inputs and outputs of the
processes in strategic decision-making. Would
inevitably lead to a creation of an environment by
which organizational intelligence and innovation
spirals. Technology is symbiotic with what it is
conducive of, how are such data feeds provoked to
process content, would permeate for its utilization.
Consequently inferencing based on what the
semantics of knowledge withhold.
REFERENCES
Boisot, M. (1987) Information and organizations: The
Manager as Anthropologist, Fontana/Collins, London.
Booch, G. Rumbaugh, J. Jacobson, I. (1999) “The Unified
Modelling Language User Guide”, Boston: Addison
Wesley.
Hedlund, G. (1994) “A model of knowledge management
and the N-form corporation”, Strategic Management
Journal, 15, 73-90
Kohonen, T. "The Self-Organizing Map" Proceedings of
the IEEE, Volume 78, Number 9. September 1990. pp.
1464-1480.
McLoughlin, H. Thorpe, R. (1993) “Action learning – a
paradigm in emergence: the problems facing a
challenge to traditional management education and
development”, British Journal of Management.
Nonaka, I. Takeuchi, K. (1995) The Knowledge Creating
Company: How Japanese Companies create the
Dynamics of Innovation, Oxford University Press,
Oxford.
Nonaka, I. Umemoto, K. Senoo, D. (1996) “From
information processing to knowledge creation: a
paradigm shift in business management”, Technology
in Society, 18(2) 203-18.
LOCATING KNOWLEDGE THROUGH AUTOMATED ORGANIZATIONAL CARTOGRAPHY [AUTOCART]
355
