
Auxiliary Data Selection in Percolative Learning Method for
Improving Neural Network Performance
Masayuki Kobayashi
a
, Shinichi Shirakawa
b
and Tomoharu Nagao
c
Faculty of Environment and Information Sciences, Yokohama National University,
79-7 Tokiwadai Hodogaya-ku Yokohama, Japan
Keywords:
Neural Network, Feature Selection, Auxiliary Data.
Abstract:
Neural networks have been evolved significantly at the cost of requiring many input data. However, collecting
useful data is expensive for many practical uses, which can be barrier for practical use in real-world appli-
cations. In this work, we propose a framework for improving the model performance, in which the model
leverages the auxiliary data that is only available during the training. We demonstrate how to (i) train the
neural network to perform as though auxiliary data are used during the testing, and (ii) automatically select the
auxiliary data during training to encourages the model to generalize well and avoid overfitting to the auxiliary
data. We evaluate our method on several datasets, and compare the performance with baseline model. Despite
the simplicity of our method, our method makes it possible to get good generalization performance in most
cases.
1 INTRODUCTION
Neural networks have advanced significantly and
been used in various of tasks. This is owing to techni-
cal and architectural innovations as well as the avail-
ability of data that allows applying them in many
practical problems. Many of these approaches, es-
pecially those that perform well, require enormous
amounts of input data. However, these requirements
not only can be a barrier to the adoption in applica-
tion, but also come at cost of obtaining useful data.
This is best illustrated by soft sensing applications
where many of useful inputs are available only in
the laboratory environment. With limited inputs, the
complicated relationships between the inputs and out-
puts might be difficult to learn, thus this leads to over-
fitting and low generalization.
In this paper, we propose a new framework for
training neural networks to solve the above issues.
The key strategy is to leverage the auxiliary data that
is only available during the training; that is, better
and generalized feature representations might be ob-
tained. The idea is encouraged by previous work on
percolative learning
*
(Yanagimoto and Nagao, 2017;
a
https://orcid.org/0000-0002-5882-8359
b
https://orcid.org/0000-0002-4659-6108
c
https://orcid.org/0000-0002-2841-9538
*
This algorithm is patent pending in Japan.
Takaishi et al., 2018), which established that the
model can be trained as though both the main and
aux data are provided during the testing. With non-
efficient aux data, the model can be easily overfitted.
We therefore propose to automatically select the effi-
cient aux data for training. To this end, we introduce
real-valued gate parameters and optimize them over
the training set. This approach encourages to train
models that generalize well rather than models that
overfit to aux data.
We applied our method to several classification
datasets, and empirically showed that our approaches
achieved better performance than baseline models in
most cases. The innovations and contributions of this
paper are summarized as follows:
• Our method achieves good generalization perfor-
mance, but also alleviates the need for inputs by
leveraging the aux data during the training.
• Despite the simplicity of our method, our method
demonstrates the advantage over the baseline.
2 RELATED WORKS
Our method leverages the additional inputs to im-
prove the neural network performance. In this sec-
tion, we briefly review the two directions of the most
Kobayashi, M., Shirakawa, S. and Nagao, T.
Auxiliary Data Selection in Percolative Learning Method for Improving Neural Network Performance.
DOI: 10.5220/0010825700003116
In Proceedings of the 14th International Conference on Agents and Artificial Intelligence (ICAART 2022) - Volume 3, pages 381-387
ISBN: 978-989-758-547-0; ISSN: 2184-433X
Copyright
c
2022 by SCITEPRESS – Science and Technology Publications, Lda. All rights reserved
381
Aux
data
Main
data
Aux
network
Main
network
Integrated
network
Predictions
… …
…
…
…
…
…
…
𝑥
!
𝑥
"
𝑥
#
…
𝑥
$%&
!
𝑥
$%&
"
𝑥
$%&
#
…
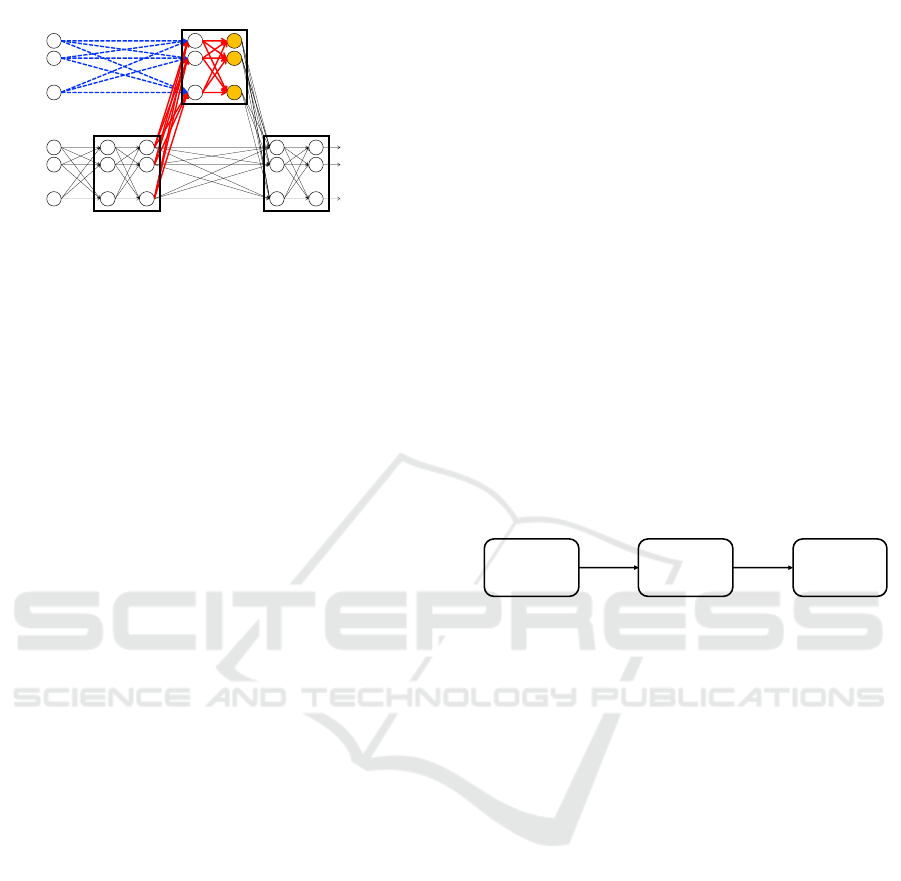
Figure 1: Overview of the percolative learning. The model
comprises three sub-networks, all of which are convolu-
tional / fully connected neural networks.
related work: multimodal learning and percolative
learning.
Multimodal learning has shown good perfor-
mance and been studied in the field of deep learning.
These methods leverage the additional inputs, how-
ever, the inputs from both modalities must be avail-
able even in the testing phase. To make the best of
multimodal data, researcher have studied to efficiently
learn a shared feature representation across modali-
ties.
Ngiam et al. (Ngiam et al., 2011) trained the
encoder-decoder model to reconstruct the inputs from
both modalities. This allows the model to extract a
shared feature representation across different modali-
ties. Although this method has assumption that the in-
put modalities are desired to have strong correlations,
this method performs well using the input from one
modality. A weakly shared deep transfer networks
(DTNs) are proposed in (Shu et al., 2015) to generate
both domain-specific features and the shared features
across domains. Although this method showed the
potential of multimodal learning, there is still room
for flexibility.
Percolative learning (Yanagimoto and Nagao,
2017) can be viewed as multimodal learning, but is
more straightforward to solve above issues. Consider
the situation where all the inputs are available dur-
ing the training but some of the inputs can be used
only for testing, this method allows the model to per-
form well as though all inputs are provided during the
testing. The key strategy is to use both the main and
aux data and efficiently learn shared feature represen-
tations between these data. Percolative learning has
proven their effectiveness on various tasks. Yanag-
imoto and Nagao have tested this method on image
classification tasks using the MNIST dataset (LeCun
et al., 1998). Takaishi et al. (Takaishi et al., 2018)
have extended this method and applied it to time-
series prediction tasks. Our method is inspired by the
recent success of percolative learning, and we exploit
the potential of leveraging the aux data.
3 OUR METHOD
Our method makes use of the aux data that is avail-
able only during the training. The training process we
use in this work is based on the Percolative Learn-
ing framework proposed by (Yanagimoto and Nagao,
2017), in which the model is trained to perform as
though aux data are provided even during the testing
phase. The main contribution of this work is the train-
ing process, such that the model is trained to general-
ize well to tasks. The inspiration is that feature en-
gineering uses domain knowledge of data to achieve
good performance. Our percolative learning also re-
lies on domain knowledge to consider which aux data
should be used for percolating; otherwise, the model
can be easily overfitted to the aux data. These ob-
servations suggest that it might be possible to get im-
provement by selecting the aux data for training; see
Fig. 2 for its overview.
Train main
network
Select the
aux data
Percolating
Figure 2: The overall pipeline of our method.
In our method, the aux data is automatically se-
lected so as to get improvements in terms of the final
generalization performance. To this end, we present
two ways to implement aux data selection, simple
gradient based method and natural gradient based
method. Both approaches allow the model to jointly
optimize the network weights and the aux data selec-
tion using the gradient descent.
In this section, we describe our training frame-
work. We first explain the details of percolative learn-
ing, and then describe the network architecture that
we use in our method. Lastly, we will explain the
training process in detail.
3.1 Background
We briefly explain the percolative learning framework
that we proposed in (Yanagimoto and Nagao, 2017).
In this method, we train the model using two types
of data: main and aux data. The main data is stan-
dard data for training neural networks, whereas the
aux data is additional data that supports the model
training process, but only available during the training
phase. The basic architecture of this method is shown
in Fig. 1. As can be seen in Fig. 1, the network com-
prises three sub-networks: an aux network, a main
ICAART 2022 - 14th International Conference on Agents and Artificial Intelligence
382
… …
…
…
…
…
…
…
1
0
1
𝑥
!
𝑥
"
𝑥
#
…
Aux
data
Main
data
Aux
network
Main
network
Integrated
network
Predictions
𝑥
$%&
!
𝑥
$%&
"
𝑥
$%&
#
…
Figure 3: Overview of our method. We introduce real-
valued parameters to determine which aux data to use for
percolating.
network, and an integrated network, all of which are
convolutional / fully connected neural networks and
end-end trainable. The aux and integrated networks
take two feature maps and concatenate them in the
channel dimension to use some beneficial aux data
for training. To efficiently train our model, we de-
compose the training process of this method into two
phases: pre-training and percolating.
Pre-training Phase: We use both the main and aux
data and optimize the weights of the whole networks,
and in turn the shared feature representations, called
percolative features, are obtained the main and aux
data.
Percolative Phase: We train the network to per-
form well while reducing the magnitude of the aux
data. Specifically, we introduce a parameter α(0 ≤
α ≤ 1.0), and gradually reduce the magnitude of the
aux data by element-wise multiplication αx
aux
. The
initial value of α is 1.0 and slowly decayed to zero.
We then update the weights of only aux network in or-
der not to change the percolative features. After this
phase is completed, the aux data is no longer avail-
able, but the network is considered to be able to rep-
resent the same percolative features as those obtained
during the pre-training phase. To this end, we use the
following training loss L
perc
to update the weights of
aux network:
L
perc
=
1
|T |
∑
|T |
j=1
k f
perc
(x
main
j
,αx
aux
j
) − F
perc
(x
main
j
,x
aux
j
)k
2
2
where we denote the network’s percolative features by
f
perc
(·); F
perc
(·) is the percolative features obtained in
the pre-training phase; x
main
is the main data; x
aux
is
the aux data; T is the training set.
3.2 Network Architecture
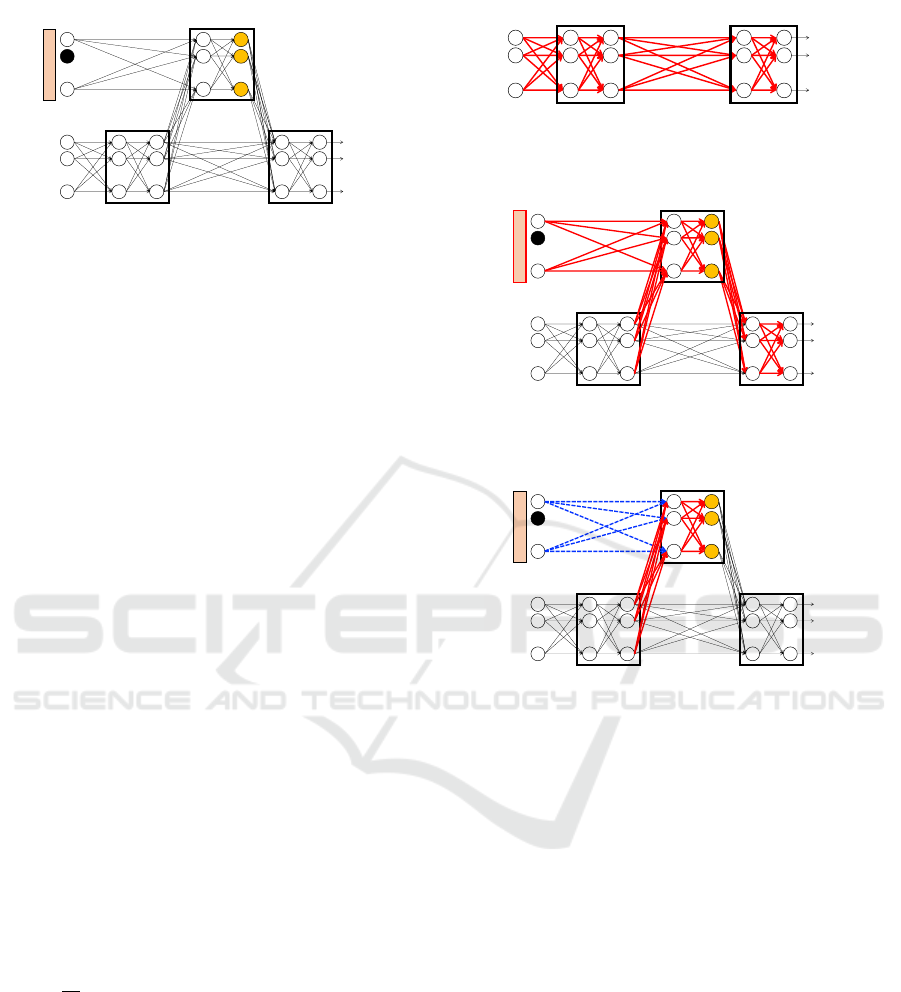
The network architecture of our method is shown in
Fig. 3. Although the network architecture is one of
the most important aspects that affect the performance
𝑥
!
𝑥
"
𝑥
#
…
…
…
…
…
…
Main
data
Main
network
Integrated
network
Predictions
(a) Pre-training phase
1
0
1
𝑥
!
𝑥
"
𝑥
#
Aux
data
Main
data
Aux
network
Main
network
Integrated
network
Predictions
… …
…
…
…
…
…
…
…
𝑥
$%&
!
𝑥
$%&
"
𝑥
$%&
#
…
(b) Selection phase
1
0
1
𝑥
!
𝑥
"
𝑥
#
Aux
data
Aux
network
Main
network
Integrated
network
Predictions
… …
…
…
…
…
…
…
…
Main
data
𝑥
$%&
!
𝑥
$%&
"
𝑥
$%&
#
…
(c) Percolating phase
Figure 4: The training process is divided into three phases:
(a) Pre-training, (b) Selection and (c) Percolating.
of our percolative learning (Takaishi et al., 2018), we
used a standard network architecture; the network ar-
chitecture comprising three sub-networks.
3.3 Training Process
In our method, we divide the training process into
three phases: pre-training, selection and percolating.
In each phase of training, different parts of network
are involved for training.
3.3.1 Pre-training
In the pre-training phase, we use only the main data
as input and train the network; see Fig. 4a. As with
the standard neural network training, we update the
model weight parameters by a stochastic gradient de-
scent method through back-propagation.
Auxiliary Data Selection in Percolative Learning Method for Improving Neural Network Performance
383

3.3.2 Selection
In the selection phase, we fix the weights of the
main network and optimize the weights of aux net-
work. Meanwhile, the decision of which aux data
to use is jointly optimized. To this end, we intro-
duce real-valued gate parameters {θ
i
} which force
N-dimensional aux data to be active at training; see
Fig. 4b. Therefore, the goal of the selection phase is
to learn two learnable parameters by minimizing the
training loss L(W, θ) which is determined by both the
network weights W and the gate parameters θ.
Beside the performance, the correlation between
the main and aux data is important objective; oth-
erwise the model can be overfitted to the aux data
(i.e. the model might select the aux data to produce
the percolative features that are difficult to represent
during the percolating phase). To avoid this, we in-
troduce a simple penalty term to capture correlation
across main and aux data. Specifically, given main
and aux data x
main
, x
aux
, our loss function penalizes
the difference between the network’s percolative fea-
tures f
perc
with / without percolation procedure. As
such, we have the expected correlations between the
main and aux data as:
`
corr
=
1
|T |
∑
|T |
j=1
k f
perc
(x
main
j
,ρ(x
aux
j
, p
perc
)) − f
perc
(x
main
j
,x
aux
j
)k
2
2
where we denote our modified percolation procedure
and the percolating probability by ρ(·) and p
perc
. In
the procedure ρ(·), the aux data x
aux
is stochastically
dropped out with a probability p
perc
that is linearly
increased during the selection phase. We empirically
found that these penalizes help to improve general-
ization and avoid overfitting. Thus, the total loss L
sel
used for aux data selection can be written as:
L
sel
= `
CE
(x
main
,x
aux
) + `
corr
(x
main
,x
aux
)
where `
CE
is cross entropy between the model predic-
tions and the training labels.
Unlike the network weight parameters, the gate
parameters θ cannot be updated by using the standard
gradient descent. Therefore, we approximate the gra-
dients, with respect to the gate parameters θ, to di-
rectly optimize its corresponding parameters. In this
work, we present two implementations of aux data
selection, although we think that other optimization
techniques could also be employed. The first method,
simple gradient based method, approximately esti-
mates the gradients with respect to its gate parame-
ters. The second one, natural gradient based method,
formulates the optimization task in a probabilistic
manner. After the selection phase is completed, we
deterministically select the aux data based on θ (i.e.
argmax
p
p(g|θ)).
Simple Gradient based Method: In this approach,
we determine which aux data to use stochastically. As
with the optimization in (Courbariaux et al., 2015),
we constraint the parameters to either 0 or 1 to deter-
mine whether or not to use aux data for percolative
learning. To be specific, the gate parameters {θ
i
} are
transformed to binarized weights {g
i
} stochastically:
g
i
=
1 with probability p
i
= σ(θ
i
),
0 with probability 1 − p
i
.
where we denote σ as the hard sigmoid function:
σ(x) = clip(x,0, 1)
Although we think other functions could also be em-
ployed, for simplicity we use this simple hard sigmoid
function. Since the gradients ∂L/∂θ
i
cannot be calcu-
lated through backpropagation, we simply update the
gate parameters θ using ∂L/∂g
i
instead of ∂L/∂θ
i
. To
this end, we compute the “masked aux data” and use
them as inputs to aux network to ensure the binarized
weights g are involved in the computational graph:
x
0
aux
= gx
aux
The gradients ∂L/∂g
i
can be computed using the
backpropagation, thus we can analogously learn the
gate parameters θ.
Natural Gradient based Method: As with the opti-
mization method proposed in (Shirakawa et al., 2018;
Saito et al., 2018), we consider the gate parameter g
that determines which aux data to use for percolat-
ing. The gate parameter g is sampled from the proba-
bilistic distribution p(g|θ) which is parameterized by
a distribution parameter θ ∈ Θ. Under the Bernoulli
distribution p(g|θ) =
∏
N
i=1
θ
g
i
i
(1 − θ
i
)
1−g
i
, we mini-
mize the following loss function:
G(W,θ) =
Z
L(W,g)p(g|θ) dg
We optimize both the W and θ by computing the gra-
dient and the natural gradient with respect to W and
θ, respectively.
∇
W
G(W,θ) =
Z
∇
W
L(W,g)p(g|θ) dg
˜
∇
θ
G(W,θ) =
Z
L(W,g)
˜
∇
θ
ln p(g|θ) dg
where
˜
∇ is natural gradient (Amari, 1998) which can
be computed by the product of the inverse of Fisher
information matrix and the gradient F(θ)
−1
∇
θ
. We
follow (Shirakawa et al., 2018) and approximate these
gradient by using Monte-Carlo methods with λ sam-
ples from p(g|θ). Specifically, we use the analytical
natural gradients of the log-likelihood
˜
∇
θ
ln p(g|θ) =
g − θ, thus the total gradients as:
G(W,θ) =
∑
g
L(W,g)(g − θ)
ICAART 2022 - 14th International Conference on Agents and Artificial Intelligence
384

Here, we employ the Monte-Carlo method to approx-
imate the gradient using λ samples from p(g|θ). As
a result, two parameters W and θ are updated as fol-
lows:
∇
W
G(W,θ) ≈
1
λ
λ
∑
i=1
∇
W
L(W,g
i
)
˜
∇
θ
G(W,θ) ≈
1
λ
λ
∑
i=1
u
i
(g
i
− θ)
where u is the ranking-based utility proposed in (Shi-
rakawa et al., 2018); top [1/4] of the samples are
u
i
= 1, bottom [1/4] of the samples are u
i
= −1, and
u
i
= 0 otherwise.
3.3.3 Percolating
As with the standard percolative learning (Yanagi-
moto and Nagao, 2017), we update the weights of
only aux network in order not to change the percola-
tive features; see Fig. 4c. However, we discovered a
modified version of percolative learning works well
in our framework. Our modified version is different
from the original one in the following ways.
Firstly, we modified the percolation process. In
the original percolative learning, the aux data are
decayed by element-wise multiplication during the
training. In our modified approach, the aux data x
aux
is stochastically dropped out with a percolating prob-
ability p
perc
that is linearly increased during the train-
ing.
Secondly, we use the mean absolute error (MAE)
between the output of the main network and the per-
colative features instead of the mean squared error
(MSE). This is because MAE is less sensitive to out-
liers and might lead to better feature extraction.
Lastly, we introduce a consistency cost between
the two percolative features. This allows the model
to give consistent predictions around the percolative
feature points. Following (Tarvainen and Valpola,
2017), we use mean squared error (MSE) as the
consistency cost during the percolating phase.
Thus, the total loss function L
perc
can be written as:
L
perc
=
1
|T |
|T |
∑
j=1
| f
perc
(x
main
j
,ρ(x
aux
j
, p
perc
)) − F
perc
(x
main
j
,x
aux
j
)|
+
1
|T |
|T |
∑
j=1
k f (x
main
j
,0)− F(x
main
j
,x
aux
j
)k
2
2
where we denote the percolative features and the
network predictions by f
perc
(·) and f (·); F
perc
(·) and
F(·) are the percolative features and the network
predictions obtained in the selection phase.
4 EXPERIMENTS AND RESULTS
4.1 Dataset
In this experiment, we applied out method on several
classification datasets, which can be obtained from
UCI Machine Learning Repository (Dua and Graff,
2017) and Kaggle
†
. We split each dataset into 80%
of training set and 20% testing set. In all dataset, the
randomly sampled 20% of inputs are used as main in-
puts and the remaining inputs are used as aux inputs
to validate effectiveness of our method.
Breast Cancer Wisconsin Dataset: Breast cancer
Wisconsin Dataset is one of the classic binary classi-
fication dataset. It contains 569 data, in which each
data has features computed from a digitized image of
a fine needle aspirate (FNA) of a breast mass.
Heart Disease UCI Dataset: Heart Disease UCI
Dataset is also a classic binary classification dataset.
It contains 303 data, in which each data contains 14
attributes of heart disease patients.
4.2 Training Settings
In the pre-training, we used SGD with Nesterov mo-
mentum (Sutskever et al., 2013) of 0.9, mini-batch
size of 32, weight decay of 1.0 × 10
−4
, and initial
learning rate of 0.1. In the selection and the perco-
lating phase, the Adam optimizer (Kingma and Ba,
2015) with learning rate α = 0.001, and momentum
β
1
= 0.9, β
2
= 0.999. In all phases, the network was
trained for 200 epochs, in which the learning rate was
reduced by a factor of 10 at 1/2 and 3/4 of the to-
tal training epochs. We updated the gate parame-
ters using the Adam optimizer with learning rate of
1.0 × 10
−4
for the simple gradient based method, and
used the sample size λ = 2, learning rate η = 1/N,
and the initial theta value θ
init
= 0.5 for the natural
gradient based method. Throughout our experiments,
we use a small neural network illustrated in Fig. 2
with a hidden size of 8 units. Then we compare the
performance of the baseline neural network with our
model to demonstrate the potential of our model. This
baseline model with same architecture has the same
number weight parameters and expressiveness as our
model. For a fair comparison, baseline model was
trained for 600 epochs (pre-training: 200 epochs +
selection: 200 epochs + percolating: 200 epochs), in
which the learning rate was reduced by a factor of 10
at 1/2 and 3/4 of the total training epochs.
†
https://www.kaggle.com/
Auxiliary Data Selection in Percolative Learning Method for Improving Neural Network Performance
385

Table 1: Results on the Breast Cancer Wisconsin Dataset and Heart Disease UCI Dataset.
(a) Breast Cancer Wisconsin Dataset
Model
Classification Performance (%)
1 2 3 4 5 6 7 8 9 10 Average
Baseline Model 90.90 93.01 89.51 95.80 93.01 93.71 87.41 93.01 95.80 95.11 92.73
Simple Gradient Based Method 95.11 93.71 93.01 95.11 96.50 95.11 92.31 94.41 95.80 96.50 94.76
Natural Gradient Based Method 95.80 93.71 93.71 95.80 96.50 95.80 91.61 94.41 95.80 96.50 94.96
(b) Heart Disease UCI Dataset
Model
Classification Performance (%)
1 2 3 4 5 6 7 8 9 10 Average
Baseline Model 68.42 71.05 57.90 48.68 71.05 80.26 64.47 71.05 64.47 64.47 66.18
Simple Gradient Based Method 68.42 72.37 59.21 48.68 72.37 80.26 64.47 82.90 61.84 65.79 67.63
Natural Gradient Based Method 67.11 72.37 59.21 53.95 72.37 80.26 64.47 77.63 63.15 65.79 67.63
4.3 Results
A summary of the accuracy is provided in Table 1.
We ran our method ten times with different random
seeds (i.e., different input splits) and reported the clas-
sification performances. We also reported the mean
classification accuracy over all splits. As can be seen
from this table, our method outperformed the baseline
model in most cases. It is observed overall that our
method demonstrated the advantage over the baseline
by 2.0% on both datasets.
We additionally conducted Wilcoxon signed rank
test to analyze the efficiency of our approach. The
p-values for simple gradient based method and the
baseline model on the breast cancer Wisconsin dataset
and heart disease UCI dataset were 0.0078 and 0.28,
respectively, and the ones for natural gradient based
method and the baseline model were 0.0078 and
0.055. As the p-values were less than 0.05 in most
cases, our percolative approach can improve the per-
formance over the baseline models. It should be also
noted that our method can achieve good performance,
despite the fact that we use no regularizations such
as Dropout (Srivastava et al., 2014). This suggests
that it is possible that further performance gain could
be achieved by leveraging these techniques in our
method.
5 CONCLUSION
In this paper, we propose a new framework for train-
ing neural network via a percolate process, in which
the model is trained by leveraging the aux data that
is only available only training. Our method also au-
tomatically selects suitable aux data for percolating.
This encourages the models to obtain generalized per-
colative features during the training. We evaluated
our method on several datasets, and demonstrated that
our model outperforms the baseline model. How-
ever, our method employed simple neural network
built upon standard components to achieve this per-
formance. This implies that our method can be made
more effective. Another direction of future research is
to apply our method to practical datasets such as time-
series prediction, thereby extending the capabilities of
our method.
ACKNOWLEDGEMENTS
This paper is based on results obtained from a project
commissioned by the New Energy and Industrial
Technology Development Organization (NEDO).
REFERENCES
Amari, S. (1998). Natural gradient works efficiently in
learning. Neural Computation, 10(2):251–276.
Courbariaux, M., Bengio, Y., and David, J.-P. (2015). Bina-
ryconnect: Training deep neural networks with binary
weights during propagations. In Advances in Neural
Information Processing Systems 28, volume 28.
Dua, D. and Graff, C. (2017). UCI machine learning repos-
itory.
Kingma, D. and Ba, J. (2015). Adam: A method for
stochastic optimization. In Proceedings of the In-
ternational Conference on Learning Representaions,
pages 2452–2459.
LeCun, Y., Bottou, L., Bengio, Y., and Haffner, P. (1998).
Gradient-based learning applied to document recogni-
tion. Proceedings of the IEEE, 86(11):2278–2324.
Ngiam, J., Khosla, A., Kim, M., Nam, J., Lee, H., and Ng,
A. Y. (2011). Multimodal deep learning. In Proc. the
ICAART 2022 - 14th International Conference on Agents and Artificial Intelligence
386

28th International Conference on Machine Learning
(ICML ’11), pages 689–696.
Saito, S., Shirakawa, S., and Akimoto, Y. (2018). Embed-
ded feature selection using probabilistic model-based
optimization. In Proceedings of the Genetic and Evo-
lutionary Computation Conference Companion (Stu-
dent workshop at GECCO 2018), pages 1922–1925.
Shirakawa, S., Iwata, Y., and Akimoto, Y. (2018). Dy-
namic optimization of neural network structures us-
ing probabilistic modeling. In Proceedings of the
Thirty-Second AAAI Conference on Artificial Intelli-
gence, pages 4074–4082.
Shu, X., Qi, G.-J., Tang, J., and Wang, J. (2015). Weakly-
shared deep transfer networks for heterogeneous-
domain knowledge propagation. In Proc. the
23rd ACM International Conference on Multimedia
(ACMMM1’15), pages 35–44.
Srivastava, N., Hinton, G., Krizhevsky, A., Sutskever, I.,
and Salakhutdinov, R. (2014). Dropout: A simple way
to prevent neural networks from overfitting. Journal
of Machine Learning Research, 15(56):1929–1958.
Sutskever, I., Martens, J., Dahl, G., and Hinton, G. (2013).
On the importance of initialization and momentum
in deep learning. In Proceedings of the 30th Inter-
national Conference on International Conference on
Machine Learning, pages 1139–1147.
Takaishi, K., Kobayashi, M., Yanagimoto, M., and Nagao,
T. (2018). Percolative learning: Time-series predic-
tions from future tendencies. In Proceedings of IEEE
International Conference on Systems, Man, and Cy-
bernetics.
Tarvainen, A. and Valpola, H. (2017). Mean teachers are
better role models: Weight-averaged consistency tar-
gets improve semi-supervised deep learning results. In
Advances in Neural Information Processing Systems,
pages 1195–1204.
Yanagimoto, M. and Nagao, T. (2017). Neural networks
percolating information available only in training. In
Proc. Mathematical Modeling and Problem Solving,
pages 1–6.
Auxiliary Data Selection in Percolative Learning Method for Improving Neural Network Performance
387
