
Multi-task Deep Reinforcement Learning for IoT Service Selection
Hiroki Matsuoka and Ahmed Moustafa
Nagoya Institute of Technology, Nagoya, Japan
Keywords:
Deep Reinforcement Learning, Service Selection.
Abstract:
Reinforcement learning has emerged as a powerful paradigm for sequential decision making. By using rein-
forcement learning, intelligent agents can learn to adapt to the dynamics of uncertain environments. In recent
years, several approaches using the RL decision-making paradigm have been proposed for IoT service se-
lection in smart city environments. However, most of these approaches rely only on one criterion to select
among the available services. These approaches fail in environments where services need to be selected based
on multiple decision-making criteria. The vision of this research is to apply multi-task deep reinforcement
learning, specifically (IMPALA architecture), to facilitate multi-criteria IoT service selection in smart city
environments. We will also conduct its experiments to evaluate and discuss its performance.
1 INTRODUCTION
The Internet has played an important role in people’s
daily lives. In recent years, the development of IT has
promoted the creation of smart cities, which aim to
improve the quality of life and the efficiency of city
operations and services by using IoT for energy and
life infrastructure management. IoT is a paradigm in
which real-world realities are connected to the Inter-
net (Singh, 2014), and services can be provided by
devices attached to them. With the development of
IoT technology, the number of devices and their ser-
vices deployed around the world is rapidly increas-
ing. Therefore, In a smart city environment, a large
number of IoT services are provided, and it is a chal-
lenge to select the most optimal IoT service (Xiong-
nan, 2014). In addition, the complexity and dynamics
of the network environment makes it more difficult to
select the optimal IoT service.
To solve the above challenges, we propose an ap-
proach using reinforcement learning in this research.
Reinforcement learning is a powerful paradigm for
sequential decision making. By using reinforce-
ment learning, intelligent agents are able to adapt
to dynamic environments. Therefore, several ap-
proaches have been proposed to use the decision-
making paradigm of reinforcement learning for IoT
service selection in smart city environments. How-
ever, many of these approaches select services from
among the available services according to a single
decision criterion. For example, quality of service
(QoS) is an important criterion in many of the service
selections; QoS includes a number of factors (e.g.,
convenience, response time, cost, etc.), which should
be considered separately because they are completely
different types of data. However, most of the previ-
ous studies have calculated the average value of each
of these QoS factors and used that value as the QoS
value. This poses the problem that it becomes difficult
to perform more optimal service selection.
Therefore, in this study, we use multi-task deep
reinforcement learning with IMPALA architecture to
facilitate multi-criteria IoT service selection in smart
city environments. By using this method, each ele-
ment of QoS can be considered separately and trained
for each element to consider more accurate QoS val-
ues, which will enable more optimal service selection.
The remainder of this paper is organized as fol-
lows: In Section 2, we describe the related works.
Section 3 describes the proposed approach, which
uses IMPALA, a multi-task deep reinforcement learn-
ing, to enable dynamic service selection with multiple
criteria. In Section 4, we present experimental eval-
uations and results to validate the approach proposed
in this paper. In Section 5, we conclude.
2 RELATED WORKS
In this section, we introduce several techniques re-
lated to dynamic service selection with multiple cri-
teria, including reinforcement learning and multi-task
deep reinforcement learning.
548
Matsuoka, H. and Moustafa, A.
Multi-task Deep Reinforcement Learning for IoT Service Selection.
DOI: 10.5220/0010857800003116
In Proceedings of the 14th International Conference on Agents and Artificial Intelligence (ICAART 2022) - Volume 3, pages 548-554
ISBN: 978-989-758-547-0; ISSN: 2184-433X
Copyright
c
2022 by SCITEPRESS – Science and Technology Publications, Lda. All rights reserved
2.1 Reinforcement Learning
In recent years, machine learning has become a
hotspot of research in the field of information technol-
ogy. Reinforcement learning has emerged as a pow-
erful paradigm for sequential decision making. With
reinforcement learning, intelligent agents can learn to
respond to the dynamic nature of uncertain environ-
ments. Several approaches have been proposed to use
the reinforcement learning decision-makingparadigm
for service selection, such as in smart city environ-
ments (Hongbing, 2020). Reinforcement learning is
also being used in the same way for ”service compo-
sition”. Here, service composition is mainly a study
of how to combine existing services to create a sys-
tem that can satisfy complex requirements, and there
are many studies that apply this to service selection.
(Wang, 2010), Markov decision process models and
reinforcement learning are used to perform adaptive
service composition. (Wang, 2016), for the problem
of efficiency of reinforcement learning, a hierarchical
reinforcement learning algorithm is used to improve
the efficiency of service composition. Also, in (Wang,
2014), (lei, 2016), and(Hongbing, 2019), multi-agent
techniques are applied to service composition. These
techniques improve the efficiency of service compo-
sition and the quality of service composition results.
However, most of these approaches select services
based on a single decision criterion from among the
available services, which leads to the loss of accu-
racy in a smart city environment where services need
to be selected based on multiple decision criteria. In
recent years, algorithms for multi-task learning have
also been studied (Volodymyr, 2016). Early work pro-
posed a multi-task deep reinforcement learning algo-
rithm that combines reinforcement learning with deep
learning (Volodymyr, 2013) and parallel computing.
One type of multi-task deep reinforcement learning is
the IMPALA architecture. IMPALA is described be-
low.
2.2 IMPALA
One of the algorithms for multi-task deep reinforce-
ment learning is the IMPALA architecture, which is
also used in this research. In this section, we briefly
describe IMPALA, a distributed reinforcement learn-
ing technique that allows learning to be performed
on thousands of machines without compromising the
learning stability or efficiency (Lasse, 2018). IM-
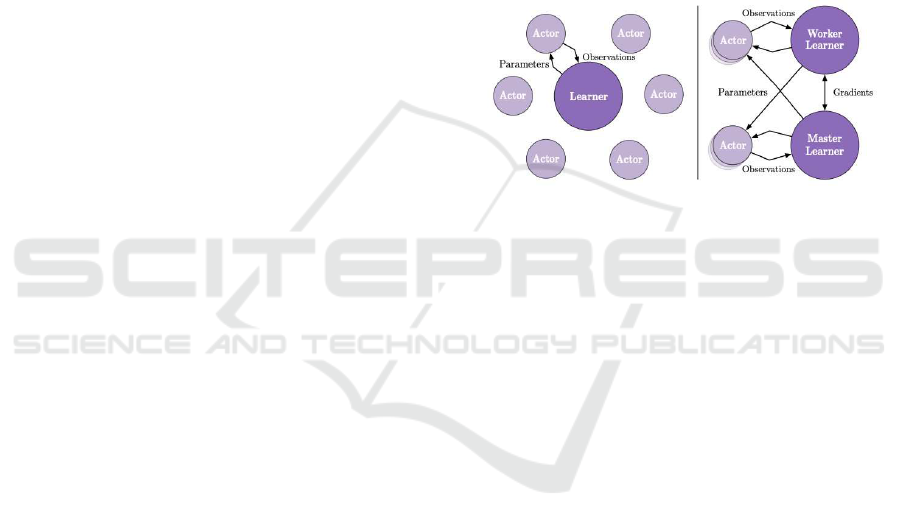
PALA uses the Actor-Critic setting to learn the mea-
sures π and the number of values V
π
. As shown in
Figure1, it consists of multiple processes (Actors) that
only collect data and one or more processes (Learn-
ers) that learn with off-policy.
An Actor collects data every n -steps. It first up-
dates its own policy µ to Learner’s policy π and col-
lects data for n -steps. Then, it sends the collected
empirical data (states, actions, rewards), the distribu-
tion of the measures µ(a
t
|x
t
), and the initial state of
the LSTM to the Learner. The Learner, on the other
hand, learns iteratively using the data sent by multi-
ple Actors. However, in this configuration, a problem
arises that the measure µ at the time of data collec-
tion does not necessarily match the measure π being
learned. Therefore, by using an algorithm called V-
trace, we can compensate for this misalignment of the
measures and obtain a high throughput without losing
sample efficiency.
Figure 1: Left: Single Learner. Each actor generates trajec-
tories and sends them via a queue to the learner. Before
starting the next trajectory, actor retrieves the latest pol-
icy parameters from learner. Right: Multiple Synchronous
Learners. Policy parameters are distributed across multiple
learners that work synchronously.
2.3 V-trace
We will briefly describe V-trace here. Off-policy
learning is important in decoupled distributed actor-
learner architectures because there is a lag between
the time an actor generates an action and the time a
learner estimates the gradient. To solve these prob-
lems, we introduce an algorithm called V-trace.
In the following, we consider finding a measure π
that maximizes the expected discounted reward sum
(value function)V
π
(x) := E
π
[
∑
t≥0
ϒ
t
r
t
] in an infinite-
time MDP. Here, γ ∈ [0, 1) is the discount factor and
the measure is a stochastic measure at ∼ π(·|xt). In
the following, we consider learning the value function
V
π
of the learning measure π using the data collected
by the behavioral measure µ.
2.3.1 V-trace Operator
The n-step V-trace operator R
n
is defined as follows:
R
n
V(x
s
) := V(x
s
) + E
µ
[
s+n−1
∑
t=s
ϒ
t−s
(C
s
···c
t−1
)δ
t
V]
(1)
Multi-task Deep Reinforcement Learning for IoT Service Selection
549

where δ
t
V := ρ
t
(r
t
+ ϒV(x
t+1
) −V(x
t
)) is the TD er-
ror weighted by Importance Sampling (IS). Let ρ
i
=
min(
¯
ρ,
π(a
i
|x
i
)
µ(a
i
|x
i
)
) and c
i
= min( ¯c,
π(a
i
|x
i
)
µ(a
i
|x
i
)
) represent the
weight coefficients of the clipped IS, and the clipping
threshold satisfies ρ
−
≥ c
−
.
Here, for the on-policy (µ = π) case, we have
(2)
R
n
V(x
s
) = V(x
s
) + E
µ
[
s+n−1
∑
t=s
ϒ
t−s
(τ
t
+ ϒV(x
t+1
) − V(X
t
))]
R
n
V(x
s
) = E
µ
[
s+n−1
∑
t=s
ϒ
t−s
τ
t
+ ϒ
n
V(x
s+n
)] (3)
and the V-trace in the on-policy case corresponds to
the n-step Bellman operator in online learning.
In V-trace, the two different IS weight thresholds
¯
ρ and ¯c play different roles. First, the threshold
¯
ρ for
the weight factor ρ
i
can be thought of as defining the
only immovable point of the V-trace operator. In the
tabular case, where there is no error in function ap-
proximation, the V-trace operator has as its only im-
movable point the value function V
π
¯
ρ
of the measure
π
¯
ρ
, which is expressed by the following equation.
π
¯
ρ
(a|x) :=
min(
¯
ρµ(a|x), π(a|x))
∑
b
min(
¯
ρµ(b|x), π(b|x))
(4)
Thus, when
¯
ρ is infinite, the V-trace operator has the
value function V
π
of the measure π as its only im-
movable point; when
¯
ρ < ∞, it has the value func-
tion of the measure between π and µ as its immovable
point. Therefore, we suppress the variance by clip-
ping at
¯
ρ. Therefore, the larger
¯
ρ is, the larger the
variance in learning the off-policy (while the bias is
small), and the smaller
¯
ρ is, the smaller the variance
(and the larger the bias) becomes. In addition, unlike
c
i
, ρ
i
is not multiplied by the time series, so it does
not show divergent behavior depending on the time
series.
Next, the threshold ¯c of the weighting factor c
i
can be thought of as controlling the speed of conver-
gence of the V-trace operator. The multiplication of
the weighting factors (c
s
··· c
t−1
) gives the TD error
at time t δ
t
V = ρ
t
(r
t
+ ϒV(x
t+1
) −V(x
t
)). Since c
i
involves a multiplication operation in the time series,
it is prone to divergence, and it is important to clip
the weight coefficient c
i
to suppress variance. Since
the size of ¯c does not affect the immovable point of
the V-trace operator (the point at which learning con-
verges), it is desirable to set it to a value smaller than
¯
ρ in order to suppress variance.
In practice, the V-trace can be calculated recur-
sively as follows
(5)
R
n
V(x
s
) = V(x
t
) + E
µ
[δ
t
V
+ ϒc
t
(R
n
V(x
t+1
) − V(x
t+1
))]
2.3.2 V-trace Actor-critic
We approximate the value function Vθ as a function
of the parameter θ and the parameter πω. The empir-
ical data is assumed to have been collected with the
action measure µ.
To learn the value function, we use the TD error
in the V-trace operator as the loss function.
Lθ = (R
n
V(x
s
) −V
θ
(x
s
))
2
(6)
The gradient is easily computable and can be ex-
pressed by the following equation.
∇
θ
V
θ
= (R
n
V(x
s
) −V
θ
(x
s
))∇
θ
V
θ
(x
s
) (7)
Also, by the measure gradient theorem and IS, the
gradient of the measure π
¯
ρ
can be expressed by the
following equation.
E
a
s
µ
[
π
¯
ρ
(a
s
|x
s
)
µ(a
s
|x
s
)
∇
ω
logπ
¯
ρ
(a
s
|x
s
)(q
s
− b(x
s
))|x
s
] (8)
where q
s
= r
s
+γR
n
V(x
s+1
) represents the estimate of
the action value function Q
πω
(x
s
, a
s
) under the V-trace
operator, and b(x
s
) represents the state-dependent
baseline function for suppressing variance. When the
bias due to clipping is very small (
¯
ρ is sufficiently
large), the above gradient is considered to be a good
estimate of the measure gradient of π
ω
. Therefore, by
using V
θ
(x
s
) as the baseline function, we obtain the
following measure gradient.
∇
ω
L
ω
= ρ
s
∇
ω
logπ
ω
(a
s
|x
s
)(r
s
+γR
n
V(x
s+1
)−V
θ
(x
s
))
(9)
We can also add an entropy loss to prevent the mea-
sure π
ω
from converging to a local solution.
L
ent
= −
∑
a
π
ω
(a|x
s
)logπ
ω
(a|x
s
) (10)
In IMPALA, these three loss functions are used for
training.
3 PROPOSED APPROACH
In this research, we propose an approach to adapt IM-
PALA architecture, a multi-task deep reinforcement
learning method, to service selection based on multi-
ple criteria in smart city environments.
As mentioned earlier in the service selection pro-
cess, QoS (Quality of Service) is an important crite-
rion in service selection. Essentially, QoS includes a
number of factors (e.g., convenience, response time,
cost, etc.). Since these are completely different data
types, they should be considered separately. How-
ever, most of the previous studies calculate the aver-
age value of these QoS factors as follows and use that
value in their calculations.
ICAART 2022 - 14th International Conference on Agents and Artificial Intelligence
550
R =
∑
m
i
(w
i
∗ r
i
)
m
(11)
where R represents the reward value, m is the number
of QoS attributes to be considered, r
i
is the value of
the i-th QoS attribute, and w
i
is the weight of the i-th
attribute. The weights reflect the importance of the
different attributes.
It is impossible to calculate the correct value of
QoS with this method, and research using more ac-
curate values is necessary. In this study, we use IM-
PALA, a distributed reinforcement learning method.
This makes it possible to learn for each element of
QoS. By judging them in a combined manner, we can
consider more accurate QoS values, which will lead to
optimal service selection. In addition, the main sce-
narios for service selection are described below.
3.1 Main Scenarios for Service Selection
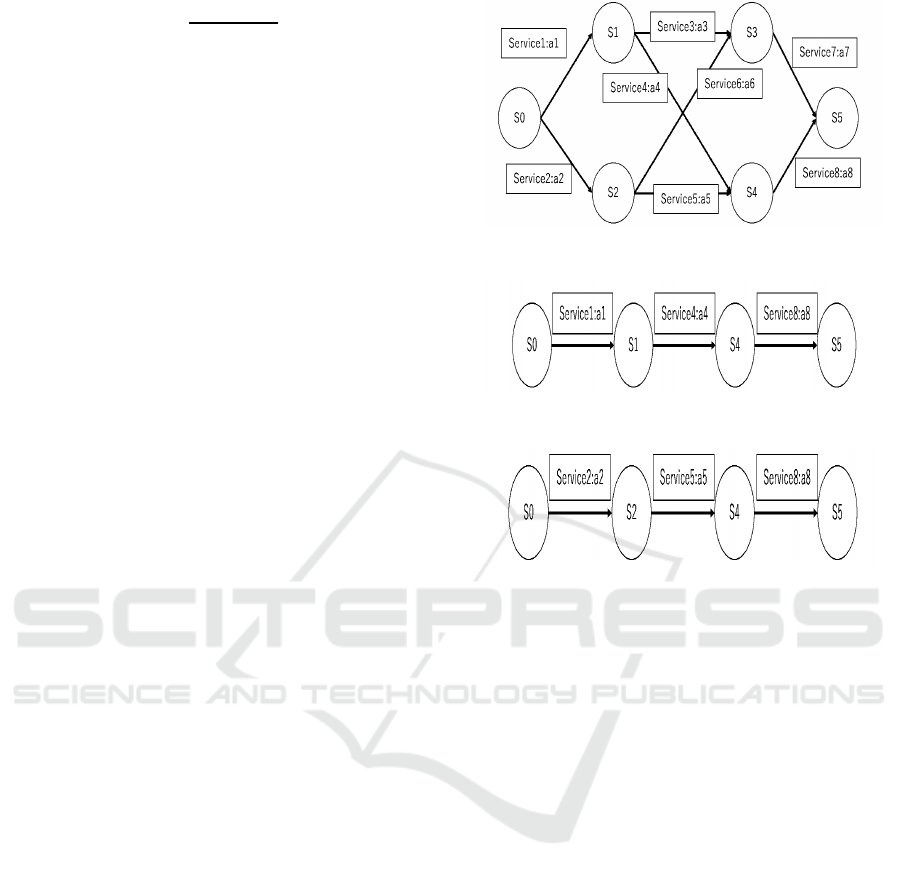
A typical service selection workflow is shown in Fig-
ure 2. For an abstract service, it is necessary to deter-
mine its concrete services and finally form a concrete
service selection workflow. For example, the results
of possible service configurationsbased on the service
selection workflow in Figure 2 are shown in Figure 3
and Figure 4. It can be clearly seen that as the number
of candidate services increases and the service com-
position workflow becomes more complex, the num-
ber of possible service composition results increases
dramatically.
By trying various patterns of service selection sce-
narios through repeated trial and error with reinforce-
ment learning, it is possible to learn the best pattern
of service selection among them.
4 EXPERIMENTS AND RESULTS
In this section, we describe the experiments we con-
ducted to demonstrate the usefulness of our proposed
method and their results.
4.1 Data Set to Be Used
In this study, we conductexperiments using IMPALA,
a distributed reinforcement learning method, to en-
able service selection based on multiple decision cri-
teria. The experiments focus on QoS, which is con-
sidered to be important in service selection. The data
set used in this research is the QWS data set (Al-
Masri, 2007). The QWS data set includes a set of
2,507 web services and their Quality of Web Service
(QWS) measurements that were conducted using our
Web Service Broker (WSB) framework. Each row
Figure 2: A simple service selection workflow.
Figure 3: A possible service selection result.
Figure 4: Another possible service selection result.
in this dataset represents a web service and its cor-
responding nine QWS measurements .
In this experiment, we will focus on three of the
nine data (response time, availability, and through-
put). By adapting the IMPALA architecture, which is
a distributed reinforcement learning, to each of these
three data, we will verify whether we can select the
best service considering the three values.
4.2 Service Selection Model
We propose a service selection model based on the
service selection workflow in the previous section.
The workflow of service selection can be regarded as
a Markov decision process. Based on the definition of
Markov decision process, we define the Markov de-
cision process model of service selection in dynamic
environment as follows:
Definition 1. The MDP defined in this study consists
of 6-tuples in total: MDP =< S
i
, S
0
, S
r
, A(), P, R >.
• S
i
is a finite set of states.
• S
0
is the initial state. The workflow of ser-
vice selection is executed from here.
• S
r
is the end state. When the end state is
reached, the workflow terminates.
• A(·) is a finite set of services. where A(s)
Multi-task Deep Reinforcement Learning for IoT Service Selection
551

represents the set of services that can be se-
lected in states s ∈ S.
• P is a probability distribution function.
When a service A is selected, it transitions
from the current state s to the subsequent
state s’. The probability of the transition is
denoted by P(s
′
|s, a).
• R is the immediate reward function. When
the current state is s and a service is in-
voked, the immediate reward R(s
′
|s, a,t) is
obtained. In service selection, the value of
the reward is generally determined by the
QoS attributes of the service.
The workflow of service selection can be con-
structed based on the definition of the Markov deci-
sion process. A simple service selection workflow,
as shown in Figure 2, can be described in MDP.
The state set is S = S
0
, S
1
, S
2
, S
3
, S
4
, S
5
. The initial
state is S
0
and the end state is S
5
. The services that
can be selected in different states are A(S
0
) = a
1
, a
2
,
A(S
1
) = a
3
, a
4
, etc. Essentially, there are multiple ser-
vices that can be selected in each state S. The transi-
tion probabilities include P(S
1
|S
0
, a
1
) = 1. The re-
ward value is calculated by the QoS obtained when
selecting a service.
Once the workflow is determined, the service se-
lection starts from the initial state and transitions to a
new state by selecting a specific service for each state.
Then, when the end state is reached, the service selec-
tion workflow is complete. This workflow consisting
of multiple selected services is the result of service
selection. The optimal service selection result is ca-
pable of maximizing the total reward.
In service selection using IMPALA, when select-
ing a service in state S, each agent selects one service
for each element of QoS, and the total value of each
reward value is the total reward value obtained when
the service is selected. In this way, it is possible to
select a service with higher accuracy than the con-
ventional QoS value for service selection, and also to
increase the efficiency of service selection.
4.3 Reward Function in Service
Selection
Reinforcement learning algorithms are suitable for
service selection problems because they use a Markov
decision process model to output the optimal action
selection. In order to use a reinforcement learning al-
gorithm, we need to set up a reward function suitable
for the task.
In service selection, satisfaction in choosing a ser-
vice is often judged by its QoS. Therefore, the re-
ward function is defined by the QoS attributes of the
service. Since the QoS attributes may have differ-
ent ranges of values, the attributes must first be nor-
malized and mapped to [0,1]. Considering that some
QoS attributes are positively correlated (e.g. through-
put) and some are negativelycorrelated (e.g. response
time), we define the following two equations.
r =
QoS− min
max−min
(12)
r =
max−QoS
max−min
(13)
Equation (12) is used for the normalization of pos-
itively correlated QoS attributes, and Equation (13)
is used for the normalization of negatively correlated
QoS attributes. Let r denote the resulting normalized
value of this attribute, QoS denotes the QoS value of
the attribute after selecting the service, and max and
min denote the maximum and minimum QoS values
of the attribute. In this study, we assume that multiple
QoS values are considered individually by IMPALA.
Therefore, in a state S, r is calculated for the number
of QoS elements. For example, if three QoS elements
(throughput, response time, and availability) are to be
considered, then three r’s will be calculated.So the
QoS value of a state is the sum of those r’s as the
total reward value. The formula to be used for this is
defined as follows.
R =
m
∑
i=1
w
i
∗ r
i
(14)
Here, r represents the total reward value, m is the
number of QoS attributes to be considered, r
i
is the
normalized value of the i-th QoS attribute, and w
i
is
the weight of the i-th attribute. The weights reflect the
importance of the different attributes. Typically, they
are set to
∑
m
i=1
w
i
= 1 according to the user’s prefer-
ence for different attributes.
4.4 Details of the Experiment
In this section, we describe the experiments con-
ducted in this study. In this experiment, we create
a Markov decision process as shown in Figure 2 and
conduct the experiment. Figure 5 shows the flow of
the Markov decision process created in this experi-
ment.
Here, m is the number of times to select a service,
and we set m = 50. The number of services that can
be selected when transitioning from state S to state S
′
is five. When a service is selected, the next group of
services is determined deterministically.
In each state, we will select a service, and the
reward for doing so will be calculated using Equa-
tion (12) and Equation (13). In this experiment, we
ICAART 2022 - 14th International Conference on Agents and Artificial Intelligence
552
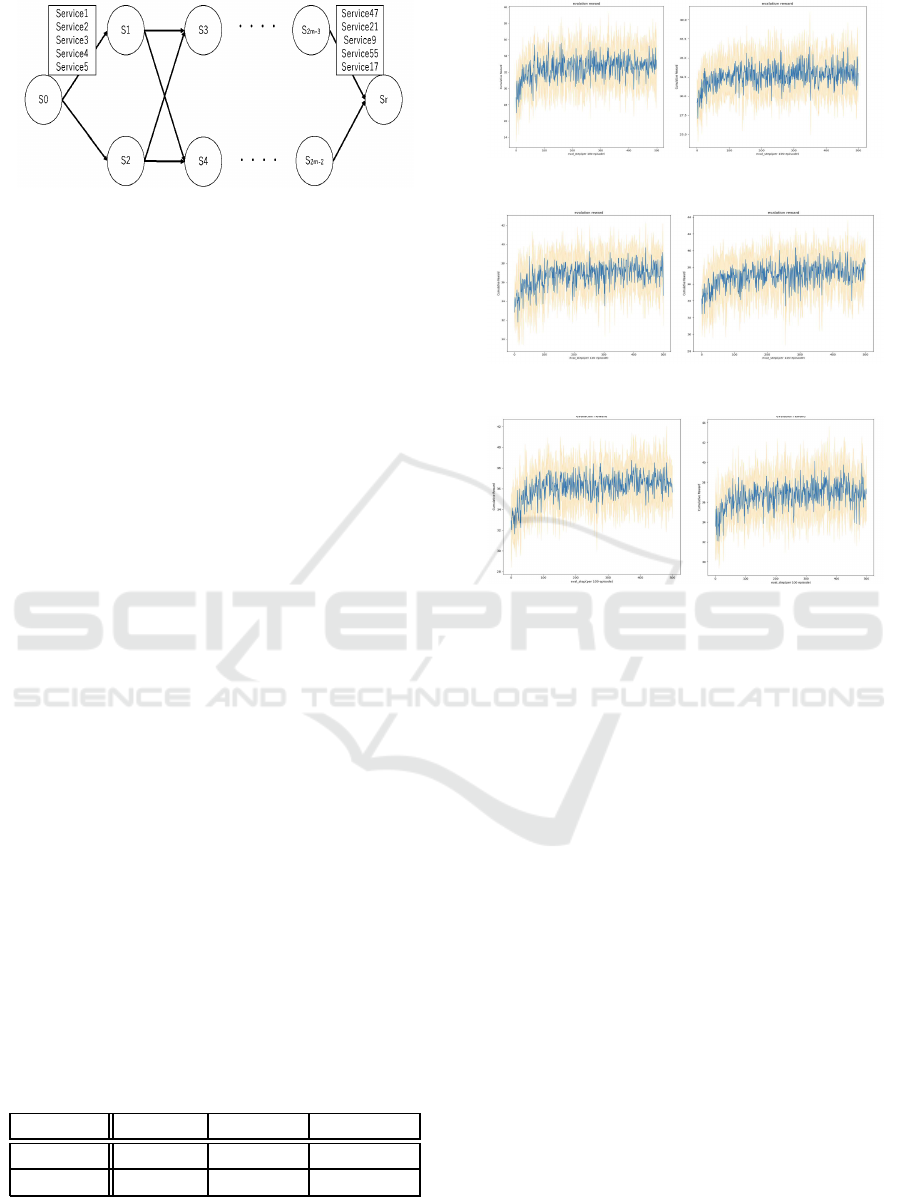
Figure 5: Experoent’s MDP model.
learn to multi-task for the three QoS factors (through-
put, reliability, and availability). The sum of the re-
ward values calculated for each state will be the fi-
nal cumulative reward, and the system will learn to
maximize it. As for the experiments conducted, we
will conduct comparison experiments between our
method and a single-task service selection method us-
ing DQN. Here, DQN can only learn to single-task for
each QoS element. We thought it would be possible
to demonstrate the usefulness of our method by com-
paring the results of learning each QoS by DQN with
the results of multi-task learning by IMPALA.
4.5 Experiment’s Results
In this section, we present the results of the exper-
iment and a discussion of the results. The results
obtained from the experiments are shown in the Fig-
ure 6, 7, and 8. On the left is a graph of the results
of single-task learning using DQN for each element
of QoS. The right graph shows the results of multi-
task learning using IMPALA for each element of QoS.
In order to determine whether the service selected at
each step is the optimal service selection, the maxi-
mum cumulative reward for each step was obtained,
and the accuracy of the optimal service selection was
calculated by dividing the obtained cumulativereward
by the maximum cumulative reward. The results are
shown in the Table 1. As a result, it can be confirmed
that for all elements of QoS, multi-task learning using
our method is more effective in selecting the optimal
service than single-task learning using DQN. In ad-
dition, the graph shows that the cumulative reward is
higher with each episode, indicating that the learn-
ing is well done. In summary, the usefulness of our
method was sufficiently demonstrated.
Table 1: Comparison of service selection accuracy.
Method available reliability throughput
DQN 79.1295 71.6792 80.1672
IMPALA 81.3412 74.7325 83.0479
As a discussion, we believe that our method was
able to maintain a high level of accuracy even during
Figure 6: Results of experiments about Reliability.
Figure 7: Results of experiments about Available.
Figure 8: Results of experiments about Throughput.
multi-task learning because it uses techniques such as
V-trace that are not available in DQN. In addition,
learning to multi-task has made it possible to learn
for multiple elements of QoS, which has made it pos-
sible to select services more flexibly according to user
needs. However, although it is now possible to select
one criterion from multiple elements of QoS to meet
the user’s needs, it would be desirable to be able to
select services considering multiple criteria from mul-
tiple elements of QoS in consideration of real-world
applications. For example, it would be desirable to
select a service with high throughput and reliability.
In the future, we would like to make this system ap-
plicable to the real world.
5 CONCLUSION AND FUTURE
CHALLENGES
With the development of IoT technology, the num-
ber of devices and their services deployed around the
world is rapidly increasing, and it is important to se-
lect the best service that meets the user’s needs from
among them. In order to select the most appropri-
ate service, many researches have been conducted in-
corporating the paradigm of reinforcement learning.
Multi-task Deep Reinforcement Learning for IoT Service Selection
553

However, in conventional research on service selec-
tion, the QoS values to be considered for service se-
lection are calculated by convertingeither a single cri-
terion or multiple criteria into a single criterion. In
this study, we believe that using distributed reinforce-
ment learning (IMPALA), each element of QoS can
be learned separately, enabling service selection that
is more accurate and tailored to the user’s needs. To
demonstrate the usefulness of our method, we con-
ducted an experiment to compare the method of learn-
ing to a single task by DQN with the method of learn-
ing to multiple tasks by our method. As a result of
the experiment, it was confirmed that for all the ele-
ments of QoS, the best service was selected by learn-
ing to multi-task with our method rather than learn-
ing to single-task with DQN. Therefore, our method
is more accurate and can select services that meet the
individual needs of users.
This made it possible to select services more flex-
ibly according to users’ needs. However, although it
is now possible to select one criterion from multiple
QoS factors to suit the user’s needs, it would be desir-
able to be able to select services considering multiple
criteria from multiple QoS factors when considering
real-world applications. For example, it would be de-
sirable to select a service with high throughput and
reliability. In the future, we would like to make this
system applicable to the real world. Specifically, we
believe that by adapting multi-objective genetic algo-
rithms, we will be able to optimize for multiple crite-
ria.
ACKNOWLEDGEMENT
This work has been supported by Grant-in-Aid for
Scientific Research [KAKENHI Young Researcher]
Grant No. 20K19931.
REFERENCES
Xiongnan Jin, Sejin Chun, Jooik Jung, and Kyong-Ho
Lee. IoT Service Selection based on Physical Ser-
vice Model and Absolute Dominance Relationship.
2014 IEEE 7th International Conference on Service-
Oriented Computing and Applications.
Singh, D., Tripathi, G., and Jara, A. J. A survey of Internet-
of-Things: Future vision, architecture, challenges and
services. in Proc. of the IEEE World Forum on Inter-
net of Things (WF-IoT), pp. 287-292, IEEE, 2014.
Hongbing Wang , Jiajie Li , Qi Yu , Tianjing Hong , Jia Yan
, Wei Zhao. Integrating recurrent neural networks and
reinforcement learning for dynamic service composi-
tion. Future Generation Computer Systems Volume
107, June 2020, Pages 551-563.
H. Wang, X. Zhou, X. Zhou, W. Liu, W. Li, A. Bouguettaya.
Adaptive Service composition based on reinforce-
ment learning. International Conference on Service-
Oriented Computing, Springer, 2010, pp. 92–107.
H. Wang, G. Huang, Q. Yu. Automatic hierarchical re-
inforcement learning for efficient large-scale service
composition. 2016 IEEE International Conference on
Web Services, ICWS, 2016, pp. 57–64.
H. Wang, X. Chen, Q. Wu, Q. Yu, Z. Zheng,
A.Bouguettaya. Integrating on-policy reinforcement
learning with multi-agent techniques for adaptive
service composition. Service-Oriented Computing,
Springer, 2014, pp. 154–168.
Y. Lei, P.S. Yu. Multi-agent reinforcement learning for
service composition. 2016 IEEE International Con-
ference on Services Computing, SCC, 2016, pp.
790–793.
P. Kendrick, T. Baker, Z. Maamar, A. Hussain, R. Buyya, D.
Al-Jumeily. An efficient multi-cloud service compo-
sition using a distributed multiagent- based, memory-
driven approach. IEEE Trans. Sustain. Comput.
(2019) 1–13.
Volodymyr Mnih,Adri`a Puigdom`enech Badia, Mehdi Mirza
, Alex Graves, Tim Harley, Timothy P. Lillicrap,
David Silver, Koray Kavukcuoglu Asynchronous
Methods for Deep Reinforcement Learning. Proceed-
ings of The 33rd International Conference on Machine
Learning, PMLR 48:1928-1937, 2016.
Volodymyr Mnih, Koray Kavukcuoglu, David Silver, Alex
Graves, Ioannis Antonoglou, Daan Wierstra, Martin
Riedmiller. Playing Atari with Deep Reinforcement
Learning. NIPS Deep Learning Workshop 2013
Lasse Espeholt, Hubert Soyer, Remi Munos, Karen Si-
monyan, Volodymir Mnih, Tom Ward, Yotam Doron,
Vlad Firoiu, Tim Harley, Iain Dunning, Shane Legg,
Koray Kavukcuoglu. IMPALA: Scalable Distributed
Deep-RL with Importance Weighted Actor-Learner
Architectures. Proceedings of the International Con-
ference on Machine Learning (ICML) 2018.
Al-Masri, E., and Mahmoud Q. H. Investigating web ser-
vices on the world wide web. 17th international con-
ference on World Wide Web (WWW ’08), pp.795-
804.
ICAART 2022 - 14th International Conference on Agents and Artificial Intelligence
554
