
Comparing the Detection of XSS Vulnerabilities in Node.js and a
Multi-tier JavaScript-based Language via Deep Learning
H
´
elo
¨
ıse Maurel
1
, Santiago Vidal
2 a
and Tamara Rezk
1 b
1
INRIA, INDES Project, Sophia Antipolis, France
2
ISISTAN-CONICET, Tandil, Argentina
Keywords:
Web Security, Deep Learning, Web Attacks, Cross-site Scripting.
Abstract:
Cross-site Scripting (XSS) is one of the most common and impactful software vulnerabilities (ranked second
in the CWE ’s top 25 in 2021). Several approaches have focused on automatically detecting software vulnera-
bilities through machine learning models. To build a model, it is necessary to have a dataset of vulnerable and
non-vulnerable examples and to represent the source code in a computer understandable way. In this work,
we explore the impact of predicting XSS using representations based on single-tier and multi-tier languages.
We built 144 models trained on Javascript-based multitier code - i.e. which includes server code and HTML,
Javascript and CSS as client code - and 144 models trained on single-tier code, which include sever code and
client-side code as text. Despite the lower precision, our results show a better recall with multitier languages
than a single-tier language, implying an insignificant impact on XSS detectors based on deep learning.
1 INTRODUCTION
Web injection vulnerabilities on the client side, a.k.a.
cross-site scripting or XSS, are pervasive and have
been on top-ranked vulnerability lists for over 10
years. XSS vulnerabilities are caused by a flow of
information, coming from untrusted input, to a sensi-
tive sink. This flow of information usually follows a
path from the client to the sever and back to (possi-
bly other) clients. In order to prevent XSS vulner-
abilities it is enough to place sanitizers, which are
adapted to the context of the sink. However, plac-
ing sanitizers is tricky and error-prone which justifies
the large existing body of woks studying the problem
of XSS detection and prevention as for example (Luo
et al., 2011; Som
´
e et al., 2016; Doup
´
e et al., 2010;
Schoepe et al., 2016; Melicher et al., 2018; Livshits
and Chong, 2013; Lekies et al., 2017; Balzarotti et al.,
; Gundy and Chen, 2009; Staicu et al., 2018). In
particular, previous works have also studied how well
deep learning techniques can help detect this kind of
vulnerabilities (Maurel et al., 2021; Melicher et al.,
2021; Fang et al., 2018; Chen et al., 2019; Mokbal
et al., 2019; Abaimov and Bianchi, 2019; Shar and
Tan, 2013). Our focus here is on static detection of
a
https://orcid.org/0000-0003-2440-3034
b
https://orcid.org/0000-0003-3744-0248
XSS vulnerabilities when the flows from sources to
sinks flow via the server (known as XSS of the first
and second type or reflected and stored XSS) and
source code from the server is available. In recent
years several techniques for code representations for
deep learning have arised (Alon et al., 2019; Shar and
Tan, 2013; Li et al., 2018a; Li et al., 2018b; Russell
et al., 2018). We are interested here in code represen-
tation techniques based on programming languages
processing or PLP (Alon et al., 2019) and the influ-
ence of more expressive abstract syntax trees in order
to detect XSS in web applications.
Traditionally, web applications execute in several
tiers including the client tier and the server tier. To
implement these tiers, developers need different lan-
guages - e.g. Javascript for the web client and PHP or
Node.js for the web server.
Multi-tier programming (Serrano et al., 2006),
(Cooper et al., 2006) is a programming paradigm for
distributed software that has arised in 2006 in order to
simplify the programming task and use a single lan-
guage to program all the tiers. This language homog-
enization offers several advantages concerning devel-
opment, maintenance, scalability, and analysis of web
applications (Weisenburger et al., 2020).
Previous work (Maurel et al., 2021) obtained sig-
nificant results to identify XSS using deep learning
comparing different code representation techniques
Maurel, H., Vidal, S. and Rezk, T.
Comparing the Detection of XSS Vulnerabilities in Node.js and a Multi-tier JavaScript-based Language via Deep Learning.
DOI: 10.5220/0010980800003120
In Proceedings of the 8th International Conference on Information Systems Security and Privacy (ICISSP 2022), pages 189-201
ISBN: 978-989-758-553-1; ISSN: 2184-4356
Copyright
c
2022 by SCITEPRESS – Science and Technology Publications, Lda. All rights reserved
189

based on NLP and PLP for PHP and Node.js and
observed a difference in impact by including client-
side content in the form of text or code in the learn-
ing process of NLP techniques. However, because
of the need of building AST representations in the
pre-processing step and the absence of an appropri-
ate parser to build models for including the HTML,
JavaScript and CSS as code for PHP and Node.js, they
could not evaluate the PLP approach that they used.
In this work, we fill this gap by studying the impact
of including client-side code as text or code (using
the more expressive multitier ASTs) in learning such
vulnerabilities detectors by comparing Node.js and
the multitier language Hop.js (Serrano, 2006; Serrano
and Prunet, 2016) using the PLP approach.
Contributions. In summary, our contributions are:
• We build a new generator for Hop.js, a multi-
tier language based on JavaScript and datasets for
Hop.js classified as XSS secure or insecure (Sec-
tion 3).
• We propose a new XSS static analyzer for Hop.js
based on deep learning and the PLP code repre-
sentation technique (Section 4).
• We evaluate models in two different datasets
one including HTML/JavaScript/CSS as code in
Hop.js and one including it as text in Node.js, us-
ing PLP as code representation for deep mode lan-
guages. Finally, we compare our results (Section
5).
2 Hop.js AND Node.js
LANGUAGES
For our experiments we have chosen two languages
to program web applications which are based on
JavaScript: Hop.js (Serrano and Prunet, 2016) and
Node.js (Node.js, 2021). Hop.js (Serrano and Prunet,
2016) is a multitier language
3
based on the JavaScript
language and it is the successor of one of the two first
multitier languages that existed HOP (Serrano, 2006).
Figure 1 shows a “hello world” multi-tier web ap-
plication in Hop.js with the special HopScript service
declaration statement. HopScript services, as shown
in line 1, are distinguished from regular Javascript
functions by using the service keyword. In this way,
the server function in line 1 is a Javascript remotely
callable function via HTTP protocol.
Figure 2 shows the same “hello world” applica-
tion but written in Node.js for the server-side. As it is
3
http://hop.inria.fr
1 ' use h o pscr i pt';
2 serv ic e s e rv er () {
3 re t u r n < ht ml >
4 <b o d y >
5 <h1 > He ll o Wo r ld < / h1>
6 </ b o dy >
7 </ h t ml > ;
8 }
Figure 1: Hop.js sample - HTML markup included in the
Javascript syntax as code.
1 let ht tp = re qu ir e ( 'ht t p' );
2 let s e r v e r = h t tp . cr e at e S e r v e r (
3 fu nc ti o n ( r eq , res ) {
4 re s. w r i te ( " <h tm l> < b o dy > < h1 > H e l l o Wo rl d ! < / h1> < /
bo d y> < / htm l> " );
5 re s. en d ( ) ;
6 }) ;
7 se r ve r . l is t e n ( 8 08 0) ;
Figure 2: Node.js sample - HTML markup included as.
shown, Node.js describe the client-side code in plain-
text inside quotes. In contrast, in Figure 1, Hop.js
embeds client-side expression using Hop.js functions
that look similar to HTML markup containers.
If we represent the AST of the previous examples,
we can notice that, for Hop.js (Figure 3b), the client-
side structures can be extracted and parsed by using
its AST. On the contrary, for Node.js (Figure 3a),
these structures are only represented as a string value
and therefore cannot be parsed. Thus, the Hop.js AST
is more expressive than the one on Node.js. It is es-
sential when an analysis needs to extract information
from the AST. For example, if a classifier algorithm
wants to be a model for XSS prediction, an AST built
for Hop.js will likely include more information to ex-
tract than an AST built from Node.js.
3 Hop.js DATABASE FOR XSS
In this work, we compare the effect of detecting
XSS vulnerabilities in a multi-tier language based
JavaScript language and Node.js with deep learning
models. With that goal in mind, we represent the
source code using ASTs. AST structures are widely
used in the pre-processing stages of programming lan-
guages to analyze code at different granularity such as
declaration level (Shar and Tan, 2013), function level
(Lin et al., 2018), the intra-procedural level (Li and
Zhou, 2005) and the file level (Wang et al., 2016; Dam
et al., 2017).
To build deep learning models that detects XSS,
having a large ground-truth database of secure and in-
secure source code is one of the major obstacles. Only
a few works have constructed real-world datasets for
evaluation. However, these datasets are generally
small, providing insufficiently labelled vulnerability
ICISSP 2022 - 8th International Conference on Information Systems Security and Privacy
190
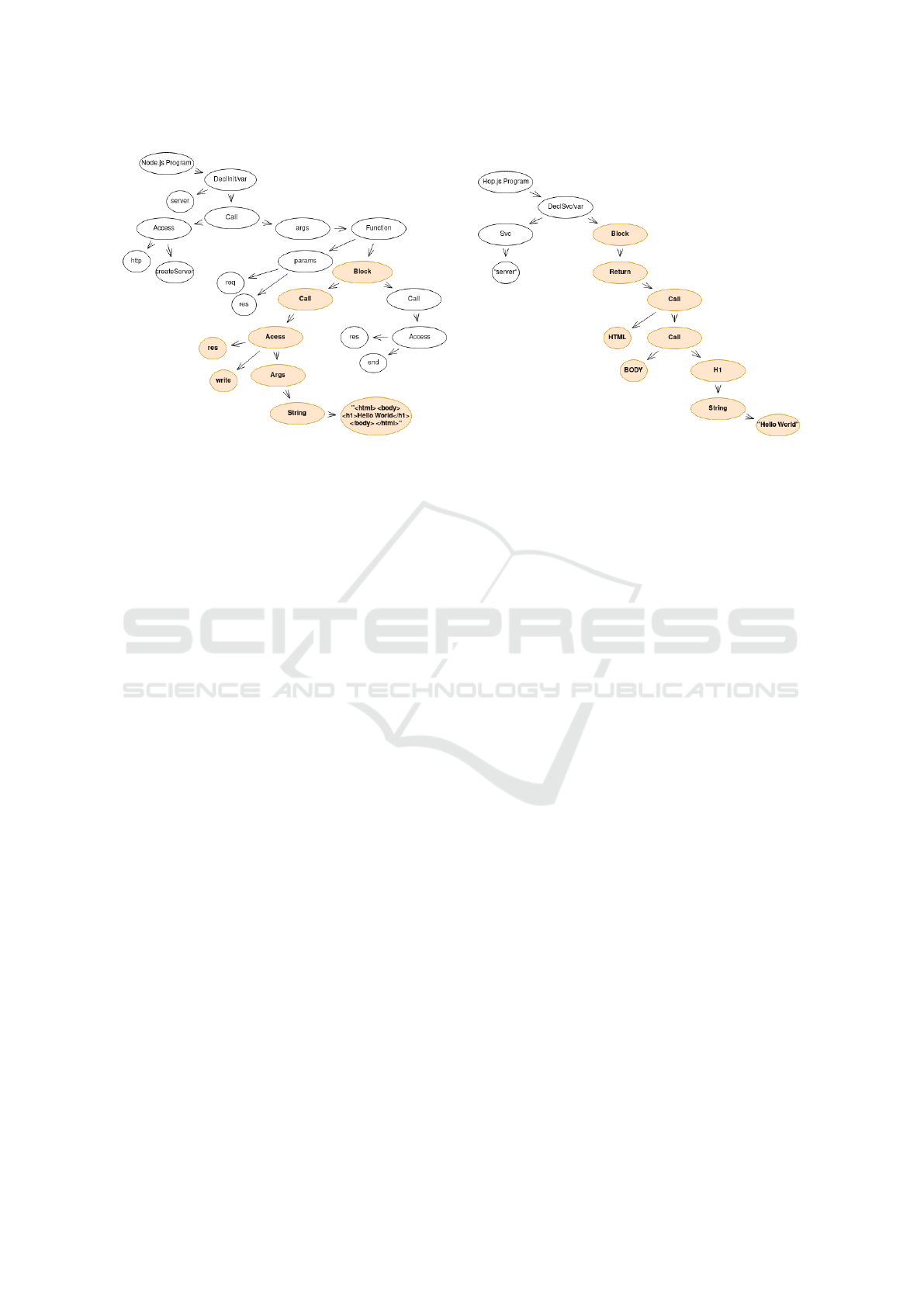
(a) A part of Node.js’s AST - backend-side language.
(b) A part of Hop.js’s AST - backend-side and client-side lan-
guage.
Figure 3: Comparison of single-tier programming and multi-tier programming by the informations obtained in analyzing the
code in Figure 2 and 1.
data (Lin et al., 2019; Lin et al., 2018), offering syn-
thetic samples that cannot be compiled (Choi et al.,
2017; Sestili et al., 2018) or are not publicly avail-
able.
Another challenge related to creating a large
ground truth database is the need to label every sam-
ple of the real-world’s datasets. As it stands, this is
tedious work done by hand for most research work
(Shar and Tan, 2013; Lin et al., 2018; Li and Zhou,
2005; Li et al., 2018b).
Additionally, we need comparable web applica-
tions to assess the influence of semantic knowledge
transcribed via AST for stand-alone multi-tier and
single-tier web applications. For all of these reasons,
in this work, we build a synthetic database that could
be used as a benchmark dataset. For comparing this
dataset with Node.js, we use the Node.js generator
created by previous work (Maurel et al., 2021).
Because supervised deep learning requires to la-
bel, in our case, as secure or insecure each sample of
the database, our generator is based on the OWASP
XSS cheatsheet series project (OWASP, 2021). This
project proposes a positive model of rules using out-
put encoding or filtering to prevent XSS attacks. We
present the implementation of the OWASP rules in
Hop.js in Section 3.2.
3.1 Hop.js Generator
We implement a synthetic generator in Hop.js.js mix-
ing server-side and client-side sources for XSS vul-
nerabilities. We generated 34,400 standalone Web ap-
plications (33 LOC on average).
Two main components constitute this generator.
First, the generation of the samples itself. The Hop.js
generator combines 16 user inputs, 84 incorrect and
proper sanitisations, and 25 construction templates
that follow OWASP rules (OWASP, 2021). The sec-
ond component is a classification system of samples.
This system classifies samples as secure or insecure.
The generator aggregates four code snippets to
produce a single sample. First, the start of a sam-
ple begins and ends respectively - depending on the
available build templates - with start and end build
fragments. Second, the generator chooses one possi-
ble Hop.js user input fragment and insert it between
the beginning and the end of the construction frag-
ments. Third, the generator gives - to the sample - a
proper, improper or no sanitisation to try to prevent
XSS or not. This type of sanitization follows the in-
put fragment. Finally, the classifier labels the sample
as secure or insecure depending on the sanitization
chosen by the generator and the HTML context of the
sink.
A sample is considered insecured for XSS when
there is a flow between a source and a sink, without
use of an appropriate sanitizer. A source is the entry-
point of user inputs where a malicious user can even-
tually inject a payload. Listing 1 shows a part of a
generator input where the value of the userData pa-
rameter can be a malicious payload injection point.
Comparing the Detection of XSS Vulnerabilities in Node.js and a Multi-tier JavaScript-based Language via Deep Learning
191

1 l et u r l Va r= r eq ui r e (' url ') ;
2 l et u nt r us t e d Va r = u rl V a r .p a r s e ( this .p a th , tr u e ) .
qu e r y . u s er D at a ;
Listing 1: Read the userData field from the server URL
query parameter when an HTTP GET request method is
called.
A sink renders the linked source on the web appli-
cation and can potentially execute its malicious con-
tent. Our generator uses 25 different sinks and they
are part of the construction templates - see Section
3.2 for more details.
The Hop.js generator is able to generate samples
with sanitized flows, unsanitized flows, incorrectly
sanitized flows and malformed flows between sources
and sinks. In the case of an incorrectly sanitized
flow, the generator can define a proper sanitization but
without applying it to the flow.
The classification component is based on the en-
coding and filtering recommendations giving by the
OWASP rules (OWASP, 2021). Depending on the
context of the sink, the potential link between the
source and the sink, and the type of sanitization used
in a sample, the classifier can label the sample as se-
cure or insecure. In this way, we generate 18,624 se-
cure Hop.js samples and 15,776 unsecure Hop.js sam-
ples.
3.2 OWASP Rules Implementation in
Hop.js
The OWASP XSS cheatsheet series project (OWASP,
2021) proposes rules using output encoding or filter-
ing to prevent XSS attacks.
In this section, we introduce the implementation
in Hop.js of the first six OWASP rules - that are used
by our generator. The last two rules relate to javascript
URL avoidance and DOM-XSS prevention. Avoid-
ing javascript URLs does not help us generate unsafe
samples and DOM-XSS recently has its own OWASP
rules which will be an extension option for future
work.
The whole listings described in each part of this
section used two Hop.js notations - ${} and ∼{} -
and two variables defined in Figure 4 : head var
and body var. The head var variable contains all
the HTML code needed to describe the header of any
HTML web application. In the case of body var, this
variable contains all the client-side code describing all
the content and HTML structure of the web applica-
tion.
The ${} and ∼{} notations are applied to in-
dicate, at compilation-time, which part belongs to
server-side code and which part belongs to client-side
code.
1 let h e a dV ar = < h e a d>
2 <t i t l e> We b Ap p 's n am e< / ti t l e >
3 </ h ea d > ;
4 let b o d yV ar = < b o d y>
5 <h 1> Al l the c on te nt of th e W e b a p p li c a t io n < / h1 >
6 <p >. .. < / p>
7 </ b od y > ;
Figure 4: head var and body var definition used in the
whole listing examples.
3.2.1 Rule #0 - Never Insert Untrusted Data
Except in Allowed Locations
OWASP recommends that developers never put un-
trusted data directly into five HTML contexts. We
implement these contexts for our Hop.js dataset.
First, developers could insert an unreliable user
data value - contained in a variable untrustedVar -
in a HTML attribute name.
In the following code, the variable untrustedVar
is an attribute of a HTML <div> tag:
1 l et d i v V a r= '< di v ' + u n tr u s t ed V a r + '= " a " / >';
2 b o d y V a r. a pp e nd C hi l d ( div Va r ) ;
3 re t u r n < ht ml > ${ h e a d Va r } ${ b o d y V a r } < / h t m l >;
The following is an full percent-encoded URL ex-
ploit for the above vulnerable code:
1 %3 E %3 c % 7 3 % 6 3 % 7 2 %6 9 %7 0 %7 4 %3 e % 6 1% 6 c %6 5% 7 2% 7 4% 2 8% 3 1% 2 9 % 3 c
2 %2 f %7 3 %6 3 %7 2 %6 9 %7 0 %7 4 %3 e
3 // De co de d v er si on
4 >< s cr i p t >a l er t (1) < % 2 f s c r i p t >
Second, developers have the possibility to in-
sert an untrusted user data value - contained in a
untrustedVar variable - in a HTML comment.
In the following code, the untrustedVar vari-
able is inside an HTML <!-- tag. This unstrusted
comment will become part of the Web application’s
metadata. Since metadata is not displayed in HTML
<head> tag and the unstrusted data is inside a com-
ment, it will be hidden from the user.
1 co m m e nt Va r = '< ! --' + u n tr u s t ed V a r + ' - ->';
2 h e a d V a r. a pp e nd C hi l d ( co m m en t V a r ) ;
3 re t u r n < ht ml > ${ h e a d Va r } ${ b o d y V a r } < / h t m l >;
The following is an full percent-encoded URL ex-
ploit for the above vulnerable code:
1 %2 D %2 D%3 E % 3 c % 7 3 % 6 3 % 7 2 % 6 9 % 7 0 % 7 4 % 3 e % 6 1% 6 c %6 5 % 72 % 74 %2 8
2 %3 1% 29 %3 c %2 f % 7 3% 6 3% 7 2% 6 9% 7 0% 7 4% 3 e%3 C %21 %2 D %2 D
3 // De co de d v er si on
4 - - > <s c ri p t > a l e rt (1 ) < % 2 f s c r i pt > < ! - -
Third, developers have the option of using an un-
trusted user data value - contained in a untrustedVar
variable - inside a complex javascript function.
In the following piece of code, the untrustedVar
variable is called inside the body of the function
called foo. This method will be called from the
client-side when the <body> element has finished
loading into the browser.
1 l et s cr i p t V a r= <s cr ip t / >;
2 l et f un cV ar = 'f un c t i o n fo o () {';
3 fu nc Va r= fu nc Va r + u n t ru s t e dV a r + '}';
ICISSP 2022 - 8th International Conference on Information Systems Security and Privacy
192

4 s c r i p t V a r . a p p e n d C h i l d ( fu nc Va r ) ;
5 l et b od yV ar = < b od y o n l o a d = ˜{ fo o () } >
6 <h1 > He l lo W or ld ! </ h 1>
7 < / b od y> ;
8 re t u r n < ht ml > ${ h e a d Va r }
9 ${ s c ri pt V a r } ${ b o d y V a r }
10 < / h tm l> ;
The following is an exploit for the above vul-
nerable code (document.vulnerable contains the
boolean type true encoded with an esoteric program-
ming style):
1 d o c u m e n t . vu l ne r ab l e= ! ![ ] ; re t u r n a l e r t (
do c um e nt . v u l n e r a b l e ) ;
Fourth, developers have the option of using an un-
trusted user data value - contained in a untrustedVar
variable - inside <script> element.
In the following piece of code, the untrustedVar
variable is an expression of the HTML <script> tag
- which is inserted inside the HTML structure of the
web application. In this context, untrustedVar vari-
able could contain any malicious javascript script and
this script will be executed by the browser.
1 l et s cr ip t V a r = <s cr ip t / > ;
2 s c r i p t V a r . a p p e n d C h i l d ( u n t ru s t e dV a r ) ;
3 re t u r n < ht ml > ${ h e a d Va r }
4 ${ s c ri pt V a r } ${ b o d y V a r } </ htm l > ;
The following is an full percent-encoded URL ex-
ploit for the above vulnerable code:
1 %6 D %61 %6 C %6 9% 63 %6 F % 75 % 7 3 %3 1% 3 D %7 0% 72 %6 F %6 D % 7 0% 74 % 28 %2 2
2 % 7 0 %6 1 %7 3 %7 3 % 7 7 % 6 F % 7 2 % 6 4 %2 2 % 2 9% 3 B%6 D %61 %6 C %6 9% 63 %6 F %75
3 %7 3% 32 %3 D % 7 0 %7 2% 6 F % 6 D %7 0 %7 4 % 2 8% 2 2% 6 C % 6 F % 67 % 6 9 % 6 E %2 2 % 2 9
4 %3 B %63 %6 F%6 E %73 %6 F %6 C %65 %2 E%6 C % 6 F % 67 % 2 8 % 6 D %61 %6 C %6 9% 6 3
5 %6 F %7 5 % 7 3 % 3 1% 2 9 % 3 B %63 %6 F %6 E %73 %6 F%6 C %65 %2 E %6 C%6 F %6 7 %2 8
6 %6 D %61 %6 C %6 9% 63 %6 F % 75 % 73 % 3 2 %2 9 %3 B
7 // De co de d v er si on
8 m a l ic o us 1 = p r o m pt (" pa s s w o rd ") ;
9 m a l ic o us 2 = p r o m pt (" log i n " ) ; c o ns o l e .l og ( m al ic o u s 1 ) ;
10 co n s o le . l o g ( ma l i c o us 2 ) ;
Fifth, developers have the option of using an un-
trusted user data value - contained in a untrustedVar
variable - inside <style> style sheet informations.
In the following piece of code, the untrustedVar
variable is an expression of the CSS <style> tag
- which is inserted inside the HTML structure of
the web application. In this context, untrustedVar
variable could force the execution of any malicious
javascript script and this script will be executed by
the browser.
1 l et s ty le Va r = < st yl e / >;
2 s t y l e V a r . ap p en d Ch i ld ( u nt r us te d Va r ) ;
3 re t u r n < ht ml > ${ h e a d Va r } ${ st yl eV ar }
4 ${ b o d y V a r } < / ht m l > ;
The following is an full percent-encoded URL ex-
ploit for the above vulnerable code:
1 < / s t yl e >< s c r i p t > a g e = p ro mp t ('Ho w old are yo u ?', 1 0 1) ;
2 ale rt (` da t a us e r ${ age } `); < / scr ip t>
Finally, developers can use an untrusted user data
value - contained in a untrustedVar variable - to cre-
ate a custom HTML tag name.
In the following piece of code, the untrustedVar
variable is a tag name that can help structure the
content of the web application. In this context,
untrustedVar variable could force the execution of
any malicious javascript script and this script will be
executed by the browser.
1 l et t a g _ v ar = '<' + un t ru st e dV a r + 'hr e f= "/ bob " / >';
2 b o d y V a r. a pp e nd C hi l d ( ta g_ va r );
3 re t u r n < ht ml > ${ h e a d Va r } ${ b o d y V a r } < / h t m l >;
The following is an full percent-encoded URL exploit
for the above vulnerable code:
1 % 7 3 % 6 3 % 7 2 %6 9 %7 0 %7 4 %3 E % 20 %6 1% 6 C %6 5 % 7 2 % 7 4 % 2 8 2 % 29 % 3 C % 2 F
2 % 7 3 % 6 3 % 7 2 %6 9 %7 0 %7 4 %3 E
3 // De co de d v er si on
4 sc r i p t> a l e rt (2 ) </ scr ip t>
3.2.2 Rule #1 - HTML Encode before Inserting
Untrusted Data into HTML Element
Content
In this rule, OWASP recommends that developers en-
code HTML before inserting it into HTML content.
To illustrate this point, OWASP gives two use cases
and we implemented them with Hop.js.
First, developers can use an untrusted user value
- contained in a variable untrustedVar - inside the
content of the structural HTML tag such a <div>.
In the following code, the variable untrustedVar
is inserted inside the content of the HTML <div> tag:
1 l et d i v V ar = <div /> ;
2 d i v Va r .a p pe n dC h i l d ( un t r u st e d V ar );
3 b o d y V a r. a pp e nd C hi l d ( div Va r ) ;
4 re t u r n < ht ml > ${ h e a d Va r } ${ b o d y V a r } < / h t m l >;
The following is an exploit for the above vulnera-
ble code:
let u n t r us t ed V a r = " > <s c r i pt > a l e r t (\" XSS \") < / s c r i p t > ";
Last, developers can apply an untrusted user data
value - contained in a untrustedVar variable - inside
the structural body of HTML.
In the following piece of code, the untrustedVar
variable is inside the web application’s <body>
markup.
1 b o d y V a r. a pp e nd C hi l d ( un tr u s t ed V a r );
2 re t u r n < ht ml > ${ h e a d Va r } ${ b o d y V a r } < / h t m l >;
The following is an full percent-encoded URL ex-
ploit for the above vulnerable code:
1 %3 C %7 3 % 7 4% 79 % 6 C % 65 %2 0 % 6 F %6 E %6 C%6 F %6 1% 64 %3 D % 2 2 % 6 1 % 6 C % 65
2 % 7 2 %7 4 %2 8 1% 2 9% 2 2 % 3 E %6 D % 61 %6 C %6 9% 6 3 % 6 F % 75 %7 3% 3 C % 2 F %7 3
3 %7 4% 79 %6 C %6 5% 3 E
4 // De co de d v er si on
5 <s t y l e o nl oa d= " al er t (1 ) " >m a li ci o u s < / sty le >
3.2.3 Rule #2 - Attribute Encode before
Inserting Untrusted Data into HTML
Common Attributes
In this rule, OWASP recommends that developers en-
code unstrusted attribute values before inserting them
into HTML common attributes. To illustrate this
Comparing the Detection of XSS Vulnerabilities in Node.js and a Multi-tier JavaScript-based Language via Deep Learning
193

point, OWASP gives one use case. Derived from it,
we implemented three HTML contexts in Hop.js.
First, developers can use an untrusted user data
value - contained in a variable untrustedVar - to de-
fine an unquoted value of common attributes.
In the following piece of code, the variable
untrustedVar is the unquoted value of a <div> tag
attribute. Unquoted values can be interrupted by
many characters, unlike simple quote or double quote
values.
1 l et d i v V ar = '<di v i d=' + u n t r us t ed Va r + '>c o n te nt < /
div >';
2 b o d y V a r. a pp e nd C hi l d ( div Va r ) ;
3 re t u r n < ht ml > ${ h e a d Va r } ${ b o d y Va r } < / h t m l> ;
The following is an full encoding URL exploit for
the above vulnerable code:
1 %7 4% 77 %6 F % 78 % 73 % 7 3 %2 0 %6 F % 6 E %6 3 %6 C %6 9 % 6 3 % 6 B %3 D % 2 2 % 61 %6 C
2 % 6 5 % 7 2 % 7 4 % 2 8 1 % 2 9 % 2 2 % 3 E % 3 C % 7 3 % 6 3 % 7 2 % 6 9 %7 0 % 7 4 %3 E % 6 1% 6 C
3 % 6 5 % 72 % 74 % 2 8 % 2 2% 7 8% 7 3 % 7 3 % 2 2 %2 9 % 3 C %2 F %7 3 % 63 % 72 % 69 % 70 % 74
4 // De c o d i n g v e r s i o n
5 tw o x s s + on cl ic k= " al er t (1 ) " > < s cr i pt > a l er t (" x s s " ) < / scr ip t
Second, developers can use an untrusted user data
value - contained in a variable untrustedVar - to de-
fine an simple quote value of common attributes.
In the following piece of code, the variable
untrustedVar is included inside simple quote of a
<div> tag attribute. Simple quote ’ character can be
only interrupted by the corresponding simple quote ’.
1 l et d i v V ar = " < di v i d='" + un t r u st e d V ar + "'> co nt en t < /
div > " ;
2 b o d y V a r. a pp e nd C hi l d ( div Va r ) ;
3 re t u r n < ht ml > ${ h e a d Va r } ${ b o d y Va r } < / h t m l> ;
The following is an exploit for the above vulnera-
ble code:
let u n t r us t ed V a r = "' > <s c r i pt > a l e r t (\" XSS \") < / s cr i p t > ";
Last, developers can use an untrusted user data
value - contained in a variable untrustedVar - to de-
fine an double quote value of common attributes.
In the following piece of code, the variable
untrustedVar is included inside double quote of a
<div> tag attribute. Double quote " character can be
only interrupted by the corresponding double quote "
unlike unquoted.
1 l et d i v V ar = '<di v i d= "' + u nt r u s te d V a r +'" >co n t e nt < /
div >';
2 b o d y V a r. a pp e nd C hi l d ( div Va r ) ;
3 re t u r n < ht ml > ${ h e a dV ar } ${ bo dy Va r }
4 < / h tm l> ;
The following is an exploit for the above vulnera-
ble code:
let u n t r us t ed V a r = '" > <s c ri p t > al e r t (\" XSS \") < / s c r i p t > ';
3.2.4 Rule #3 - JavaScript Encode before
Inserting Untrusted Data into JavaScript
Data Values
OWASP advices developers to place untrusted data
only inside quoted data values in JavaScript code. To
illustrate this point, OWASP gives four use cases. and
we implemented them with Hop.js. Derived from
these use cases, we implemented seven HTML con-
texts in Hop.js.
First, developers can use an untrusted user data
value - contained in a variable untrustedVar - inside
simple quoted event handler values.
In the following piece of code, the variable
untrustedVar is inserted inside simple quoted of a
onmouseover event.
1 b o d y V a r. a pp e nd C hi l d ( " < di v on m o u se o v e r= \ " x='" +
un t r u st e d V ar + " '\ >" ) ;
2 re t u r n < ht ml > ${ h e a d Va r } ${ b o d y V a r } < / h t m l >;
The following is an full encoding URL exploit for
the above vulnerable code:
1 % 7 8 %7 3 %7 3 %2 7 % 2 2 % 3 E% 3 C % 7 3 % 6 3 % 7 2 %6 9 %7 0 %7 4 %3 E %6 D % 61 % 6 C %69
2 %6 3% 69 %6 F % 75 %7 31 % 3 D % 70 %7 2% 6 F % 6 D % 7 0% 7 4% 2 8% 2 2% 7 0% 6 1% 7 3
3 %7 3% 77 %6 F % 72 % 64 % 2 2 %2 9 %3 B % 6 D %6 1 %6 C % 6 9 %6 3 % 6 9% 6 F %7 5 % 7 3 2
4 %3 D %7 0% 72 %6 F % 6 D % 7 0 % 74 % 2 8 %2 2 lo gi n % 22 %2 9% 3 B %61 %6 C %6 5 % 7 2
5 %7 4% 28 %6 D %6 1% 6 C %69 % 6 3 %6 9 % 6 F %7 5 % 7 3 1 %2 B %2 2% 3 A %2 2% 2 B %6 D
6 %61 %6 C %6 9 %6 3% 6 9 % 6 F %7 5% 7 3 2 %2 9 % 3 B% 3 C %2 F %7 3 %6 3 % 7 2 % 6 9% 7 0
7 %74 %3 E
8 // De co de d v er si on
9 x ss'" >< sc r ip t >m a l i c i o u s 1 = p ro m pt (" pa s s w o rd ") ;
10 m a l ic i ou s 2= p r o m p t (" l og in ") ;
11 ale rt ( ma l i c io us 1 %2 B " : "% 2 Bm al i c i ou s 2 ); < / s cr ip t>
Second, developers can use an untrusted user data
value - contained in a variable untrustedVar - inside
double quoted event handler values.
In the following piece of code, the variable
untrustedVar is inserted inside double quoted of a
onmouseover event.
1 b o d y V a r. a pp e nd C hi l d ( " < di v on m o u se o v e r= \ " x= " +
un t r u st e d V ar +" \ "\ > " ) ;
2 re t u r n < ht ml > ${ h e a d Va r } ${ b o d y V a r } < / h t m l >;
The following is an exploit for the above vulnera-
ble code:
1" on cl i ck = a l er t ( " x ss " ) >cl ic k< / div >
Third, developers can use an untrusted user data
value - contained in a variable untrustedVar - inside
simple quoted string and used in JavaScript script.
In the following piece of code, the variable
untrustedVar is inserted inside simple quoted of an
alert box.
1 l et s cr ip t V a r = <s cr ip t / > ;
2 s c r i p t V a r . a p p e n d C h i l d (" a le rt ('" + un tr u s t ed V a r + " ')" );
3 re t u r n < ht ml > ${ h ea dV ar } ${ s c r i p tV ar } ${ b od yV ar }< / h tm l >
The following is an exploit for the above vulnerable
code:
no r m a l ') < / s c ri p t> < sc r ip t >a l er t (" x s s ") < / sc ri p t> < s c ri p t>
Fourth, developers can use an untrusted user data
value - contained in a variable untrustedVar - inside
double quoted string and used in JavaScript script.
In the following piece of code, the variable
untrustedVar is inserted inside double quoted of an
alert box.
1 l et s cr ip t V a r = <s cr ip t / > ;
2 s c r i p t V a r . a p p e n d C h i l d (" a le rt (\" " + un t r us t ed Va r +" \" ) " ) ;
3 re t u r n < ht ml > ${ h ea dV ar } ${ s c r i p tV ar } ${ b od yV ar }< / h tm l >
ICISSP 2022 - 8th International Conference on Information Systems Security and Privacy
194

The following is an exploit for the above vulnerable
code:
1 no r m a l " ) < / s c ri p t > <b u t t o n o na f te r sc r ip t ex e cu t e=
2 ale rt (1) > < s cr i p t >1 < / sc r i p t >
Fifth, developers can use an untrusted user data
value - contained in a variable untrustedVar - inside
JavaScript simple quoted assignments.
In the following piece of code, the variable
untrustedVar is inserted between simple quoted to
define the value of the variable x.
1 l et s cr ip t V a r = <s cr ip t / > ;
2 s c r i p t V a r . a p p e n d C h i l d ( " x= '" + u nt r u s te d V a r + "'" ) ;
3 re t u r n < ht ml > ${ h e a dV ar } ${ s c r ip tV ar } ${ b od yV ar }< / h tm l >
The following is an exploit for the above vulnerable
code:
1 3'; d at a _u s er = p r o m p t ( " Fi rs t Nam e " ) ;
2 ale rt ( da t a _ u s er ); y='3
Sixth, developers can use an untrusted user data
value - contained in a variable untrustedVar - inside
JavaScript double quoted assignments.
In the following piece of code, the variable
untrustedVar is inserted between double quoted to
define the value of the variable x.
1 l et s cr ip t V a r = <s cr ip t / > ;
2 s c r i p t V a r . a p p e n d C h i l d ( " x= \ " " + un tr u st ed V ar + " \" " ) ;
3 re t u r n < ht ml > ${ h e a dV ar } ${ s c r ip tV ar } ${ b od yV ar }< / h tm l >
The following is an exploit for the above vulnerable
code:
1 x ss " ; da t a _u s er = pr o m p t ( " x ss " ) ; y = d a ta _ u s er ;
2 co n s o le . l o g ( y ) ; z= " xss
Finally, OWASP warns to never use unreliable
data as input to built-in javascript functions such as
setInterval. However, any developer can use the fol-
lowing format:
1 l et s cr ip t V a r = <s cr ip t / > ;
2 s c r i p t V a r . a p p e n d C h i l d ( " w i n d o w . se t In t er v al ( '" +
un t r u st e d V ar + "' ); " );
3 re t u r n < ht ml > ${ h e a d Va r } ${ sc ri pt V a r } ${ bo dy Va r } </
ht m l>
The following is an exploit for the above vulnerable
code:
1 co n s o le . l o g ( " x ss3 ") ;' , 1000 ) ;
2 se t T i me ou t (" c o n s ol e . l og (' xs s 2') ;" , 500 ) ; a le rt (' xss 1
3.2.5 Rule #4 - CSS Encode and Strictly Validate
before Inserting Untrusted Data into
HTML Style Property Values
OWASP advices developers to place untrusted data
only inside property value in CSS style. To illustrate
this point, OWASP gives three use cases. Derived
from these use cases, we implemented four HTML
contexts in Hop.js.
First, developers can use an untrusted user data
value - contained in a variable untrustedVar - inside
double quoted CSS property value.
In the following piece of code, the variable
untrustedVar is inserted inside double quoted of a
color property.
1 l et s ty le _ v a r = <s ty l e / >;
2 s t y l e _ v a r . a p p e n d C h i l d (" b od y { col or : \" " +
un t r u st e d V ar + " \ "; } " );
3 b o d y V a r. a pp e nd C hi l d ( s t y l e _v ar ) ;
4 re t u r n < ht ml > ${ h e a d Va r } ${ b o d y V a r } < / h t m l >;
The following is an exploit for the above vulnerable
code:
1 ; } @ k e y fr am e s x { }< / sty le >
2 <xs s st yl e = " an i ma t i o n - n am e :x " o n a n i ma t io n e n d=
3 " a le rt (' x ss ')" >< / x ss >
Second, developers can use an untrusted user data
value - contained in a variable untrustedVar - inside
simple quoted CSS property value.
In the following piece of code, the variable
untrustedVar is inserted inside simple quoted of a
color property.
1 l et s ty le _ v a r = <s ty l e / >;
2 st yl e _ v ar = st y l e _ va r + " bo dy { c ol o r : \'" +
un t r u st e d V ar + " \';} " + '< / s ty le >';
3 b o d y V a r. a pp e nd C hi l d ( s t y l e _v ar ) ;
4 re t u r n < ht ml > ${ h e a d Va r } ${ b o d y V a r } < / h t m l >;
The following is an exploit for the above vulnerable
code:
1 '} @ke y f r am e s x ss { } < / s t y l e >
2 <im g st yl e = " an i ma t io n -n a m e : x s s "+
3 o n w e b k i t a n i m a t i o n e n d = 'a le r t ( " x ss " )'>< / i mg>
Third, developers can use an untrusted user data
value - contained in a variable untrustedVar - inside
an unquoted CSS property value.
In the following piece of code, the variable
untrustedVar is inserted as an unquoted value of a
color property.
1 l et s ty le _ v a r = <s ty l e / >;
2 st yl e _ v ar = st y l e _ va r + " bo dy { c ol o r : " +
un t r u st e d V ar + " ; }" + '</ sty le >';
3 b o d y V a r. a pp e nd C hi l d ( s t y l e _v ar ) ;
4 re t u r n < ht ml > ${ h e a d Va r } ${ b o d y V a r } < / h t m l >;
The following is an exploit for the above vulnerable
code:
1 bl u e ; < / st y le > < s c r i p t > a l e r t ( " xss " ) < / scr ip t>
Finally, developers can use an untrusted user data
value - contained in a variable untrustedVar - inside
a style attribute value of HTML markup.
In the following piece of code, the variable
untrustedVar is inserted inside a style value of a
HTML <span> markup.
1 b o d y V a r. a pp e nd C hi l d ( " <sp an s ty l e = \" col or :" +
un t r u st e d V ar + " \" > Hey </ spa n > " ) ;
2 re t u r n < ht ml > ${ h e a d Va r } ${ b o d y V a r } < / h t m l >;
The following is an exploit for the above vulnerable
code:
blu e " + o n cl i c k =a l e r t ( do c u m en t .c o o k i e ) ;+ b= "
Comparing the Detection of XSS Vulnerabilities in Node.js and a Multi-tier JavaScript-based Language via Deep Learning
195

3.2.6 Rule #5 - URL Encode before Inserting
Untrusted Data into HTML URL
Parameter Values
OWASP warns developers to encode untrusted data
before to put it inside HTTP GET parameter values.
To illustrate this point, OWASP gives one use case.
Derived from it, we implemented three HTML con-
texts in Hop.js.
First, developers can use an untrusted user data
value - contained in a variable untrustedVar - in
double quoted hyperlink attribute values.
In the following code, the variable untrustedVar
is inserted inside double quoted of an HTML href
attribute value:
1 b o d y V a r. a pp e nd C hi l d ( " <a h r ef = \ " "+ u n tr u s t ed V ar +" \" >
2 lin k< /a> " ) ;
3 re t u r n < ht ml > ${ h e a d Va r } ${ b o d y Va r } < / h t m l> ;
The following is an exploit for the above vulnerable
code:
1 j a v a sc r i p t : d o c um e n t . v ul n er a b l e = tr u e ;
2 ale rt ( d o c u m e n t . v u l n e r ab l e ) ;
Second, developers can use an untrusted user data
value - contained in a variable untrustedVar - in
simple quoted hyperlink attribute values.
In the following piece of code, the variable
untrustedVar is inserted inside simple quoted of an
HTML href attribute value:
1 b o d y V a r. a pp e nd C hi l d ( " <a h r ef ='" + u n t r us t e d Va r + "'>
2 lin k< /a> " ) ;
3 re t u r n < ht ml > ${ h e a d Va r } ${ b o d y Va r } < / h t m l> ;
The following is an exploit for the above vulnerable
code - the variable x contains a true boolean value
encoded with an esoteric programming style:
1 j a v a s c r ip t :j a v a s c r i p t : a le r t ( do c u m en t .c o o k ie ); x = !! [] ;
2 d o c u m e n t. v ul n e r a b l e = x ; a le r t ( x ) ;
Finally, developers can use an untrusted user data
value - contained in a variable untrustedVar - in un-
quoted hyperlink attribute values.
In the following code, the variable untrustedVar
is inserted inside the unquoted value of the HTML
href attribute:
1 b o d y V a r. a pp e nd C hi l d ( " <a h r ef = " + u n t ru s t e dV a r +
2 " > li nk < / a > " ) ;
3 re t u r n < ht ml > ${ h e a d Va r } ${ b o d y Va r } < / h t m l> ;
The following is an exploit - that mixed percent-
encoding and HTML entity encoding - for the above
vulnerable code:
1 ja v a s cr i p t : % 2 6 % 2 3 9 7% 2 6 % 2 3 10 8 % 2 6 % 2 3 1 01 % 2 6 % 2 31 1 4 % 2 6
2 % 2 3 1 1 6 % 2 6% 2 3 4 0 % 26 % 2 3 3 4 %2 6 % 2 3 1 20 % 2 6 % 2 31 1 5 % 2 6 %2 3 1 1 5
3 % 2 6 %2 3 34 % 26 % 2 3 4 1 ;
4 // De co de d v er si on
5 j a v as c ri p t : a l e rt (" x ss " )
4 Hashed-AST TECHNIQUE (PLP)
Once that the dataset is built, it can be used to train
a deep learning model. However, since the dataset is
composed by source code files, a representation strat-
egy is needed. To achieve this goal, we followed the
AST-based approach presented by Code2Vec (Alon
et al., 2019). Specifically, this representation trans-
verse the AST of a piece of code (i.e. file) in order
to obtain all the possible paths between leafs. In this
way, the path is represented as a triplet < x
s
, p, x
t
>
where x
s
is the starting leaf, x
t
is the target leaf, and p
is the path between them. Each triplet is then mapped
to its embedding. Each source code file is represented
with the set of embeddings obtained after traversing
its AST, and it will be the input for the deep learning
algorithm. For a complete description of the represen-
tation technique, please refers to (Alon et al., 2019).
Since the Code2Vec implementation does not support
Hop.js, we extend it by implementing an AST ana-
lyzer that obtains the triplets for a given source code
file
4
.
Since the number of path between leafs can be
very large, we use two parameters to keep the number
of triplets into a computationally affordable number:
• maxPath length/width: this parameter restrict the
obtained paths by the number of nodes between
the leaves (length) and the number of branches be-
tween the leaves (width).
• maxContext: limits the maximum number of
triplets used to represent a piece of code.
Figure 5: Code2Vec deep learning network used.
Regarding the deep learning model (Figure 5),
we also use the one used in Code2Vec but changing
its output layer to a sigmoid function. In short, the
triplets are input into an embedding layer whose out-
put goes into a fully-connected layer. Also, an atten-
tion layer is used to learn which paths between leafs
are more important to detect if a piece of code is af-
fected by XSS. At the end, an output sigmoid layer is
used to predict is the piece of code is safe or unsafe.
4
The source code will be available at
https://gitlab.inria.fr/deep-learning-applied-on-web-and-
iot-security
ICISSP 2022 - 8th International Conference on Information Systems Security and Privacy
196

A detailed description of the model can be found at
(Alon et al., 2019).
5 EVALUATION
Our evaluation process aims to compare the impact of
multi-tier languages on Hashed-AST models of super-
vised deep learning - to detect XSS - with single-tier
language. We use Hop.js as a multi-tier language, and
Node.js as a single-tier language.
As explained in Section 3.1, to create the dataset
we implement a source code generator for Hop.js
whereas we modify a Node.js generator implemented
by a previous paper (Maurel et al., 2021) to translate
into Node.js the Hop.js generated samples .
In this section, we explain the preprocessing step
of the database and the experimental protocol (Sec-
tion 5.1), then, we present and discuss the evaluation
results (Section 5.2).
5.1 Evaluation Process
This section explains the preprocessing steps required
by the Hop.js and Node.js databases to be “under-
standable” for the deep learning model.
As shown in Table 1, we split the databases into
training (70% of the samples), validation (15%) and
testing (15%). To prevent any possible similarities be-
tween the generated Hop.js samples, we randomly re-
name all variables and function names of the datasets.
As explained in Section 4, the Hashed-AST based
representation that we employ has two hyperparam-
eter: maxPath length/width, and maxContext. For
maxPath we experiment with several values, namely,
10, 20, 30, 50, 80, 130, 210 and 550. Similarly, for
maxContext, we used 100, 200, 300, 500, 800, 1300,
2100, 3400 and 5500.
By combining the eight maxPath values with the
nine values of maxContext, we train 72 models on the
training set for Hop.js and 72 models for Node.js.
We evaluate the 144 models trained with the
validation-set by obtaining the confusion matrix val-
ues (FP, FN, TP, TN) to compute the related metrics
accuracy, precision, recall, and f-measure. Then, we
re-validate these results by using the test-set.
It is important for a vulnerability detector tool not
to miss any vulnerability. In this sense, we choose the
model that has the highest recall. However, a detec-
tor model with perfect recall (i.e. close to 1) but with
poor precision (e.g. less than 0.5) means the detec-
tor cannot discern if a sample is truly secure and will
trigger many false alarms for more than 50% of the
secure samples.
In this sense, to analyze the impact of including
client-side content as code or text on the Hashed-AST
learning phase, we focus our analysis on the evolution
of the recall, precision, and f-measure.
5.2 Evaluation Results
In this section, we present the results of our exper-
iment. Due to space constraints, we cannot present
all the results obtained. The complete results are
available online at https://www.sendgb.com/upload/
?utm source=EFOMAhJfGZb.
We analyze the precision, recall, and f-measure
values obtained during the validation and training
phases for both Hop.js and Node.js.
Precision Distributions Analysis. Figure 6a shows
the precision distributions of Hop.js and Node.js ob-
tained by the 144 models evaluated with the validation
and the testing dataset.
For Hop.js, the precision results between the eval-
uation and the testing phase are very similar. The me-
dians for these distributions are near 72%. Moreover,
25% of the models trained have a high precision be-
tween 99% and 86%.
Concerning Node.js precision, the evaluation and
testing phases’ results are also similar. The medians
for these distributions are near 95% and, some models
achieves 100% precision. In fact, 25% of the models
trained have a high precision that is between 98% and
100%.
Recall Distributions Analysis. Concerning the
Hop.js recall distributions (Figure 6b), the results of
the validation and the testing phase are very close.
The medians for these distributions are near the max-
imum recall achieved: 99.80% for the validation set
and 99.90% for the testing set.
Concerning the Node.js recall, the evaluation and
testing phases’ results are also similar. The medians
for these distributions are near 91% and, their max-
imum recall achieves 99%. Moreover, 25% of the
models trained have a high recall (around 96% and
99%).
F-measure Distributions Analysis. Regarding f-
measure results for Hop.js (Figure 6c), the validation
and the testing dataset are very similar. The medians
for these distributions are near 84%, and, their maxi-
mum f-measure achieved is around 94%. In fact, 25%
of the models trained have a high f-measure with val-
ues between 89% and 94%.
Comparing the Detection of XSS Vulnerabilities in Node.js and a Multi-tier JavaScript-based Language via Deep Learning
197

Table 1: Generated Databases.
Language Database Classification Distribution
Total #secure #insecure Set #rule #secure #insecure
Hop.js
D1
34,400 18,140 16,260
train
0,1,2,3,4,5
12,998 11,082
HTML test 2,804 2,356
validation 2,338 2,822
Node.js
D1
25800 13,968 11,832
train
0,1,2,3,4,5
9,708 8,352
HTML test 2,144 1,726
validation 2,116 1,754
(a) Precision. (b) Recall. (c) F-measure.
Figure 6: Hop.js and Node.js boxplots for the validation set and the testing set distributions.
Concerning the Node.js f-measure distributions,
the evaluation and testing phases’ results are also sim-
ilar. The medians for these distributions are near 90%,
and their maximum f-measure achieved are around
97.50%. The upper 25% of the models have a f-
measure ranging 96% and 98%.
To claim any statistically significant difference of
these results, a statistically test is needed. We em-
ploy the Wilcoxon rank-sum non-parametric test with
a probability of error of α = 0.05.
We start by analyzing if there is any signifi-
cant statistically difference between the results of the
evaluation and testing phases. For Hop.js we ob-
tained p
value−precision
= 0.96, p
value−recall
= 0.70, and
p
value− f measure
= 0.77, which means that the Hop.js
results, for each metric, in the validation and test-
ing phase are statically similar. We obtain the same
conclusion for Node.js with a p
value−precision
= 0.86,
p
value−recall
= 0.19 and p
value− f measure
= 0.15.
Now we analyze if there is any significant differ-
ence between the results of Hop.js and Node.js. For
the validation phase results, after applying the tests
we obtained a p
value−precision
= 7.26E
−11
. Thus, there
is a significant difference between the Hop.js and the
Node.js precision distributions. Meaning that the pre-
cision obtained for Node.js is significantly higher. For
the recall, we obtained a p
value−recall
= 5.57E
−08
.
Thus, Hop.js has a statistical significant better recall
than Node.js. Finally, for f-measure, we conclude that
there is no significant difference between the Hop.js
and the Node.js after obtaining a p
value− f measure
=
0.15.
We also run the same tests for the test-phase
results and we reach the same conclusions after
obtaining the p-values: p
value−precision
= 7.26E
−11
,
p
value−recall
= 3.05E
−08
and p
value− f measure
= 0.15.
Finally, we select and compare the best models of
the testing phase for each language. As previously ex-
plained, each of the metrics analyzed measure some
strength of the model. For this reason, we choose the
best model for each metric. That is to say, we selected
three models for Hop.js and 3 for Node.js (Table 2).
While all the models show a good performance, it can
be noticed that the Node.js models have the best re-
sults.
In summary, taking into account all the results ob-
tained, we found that a better precision was obtained
with the Node.js models while a better recall was ob-
tained with the Hop.js models.
Along this line, we can conclude that using a mul-
titier language as Hop.js increase drastically the re-
call despite the lower precision. However, the use
of Hop.js does not significantly impact f-measure to
claim that using a multitier language positively im-
pacts the XSS identification using deep learning.
Limitations: Although the results are promising,
the approach has some limitations. First, this study
only focus on applications contained in a single file
while most real world applications are divided into
ICISSP 2022 - 8th International Conference on Information Systems Security and Privacy
198

Table 2: Comparison of the best Hop.js and Node.js models for each metric.
Configuration model Evaluation phase \% Testing phase \%
Language Selected metric maxPath maxContext Precision Recall F-measure Precision Recall F-measure
Hop.js
precision 30 5500 99.58 82.04 89.97 98.39 86.28 94.94
recall 50 1300 78.84 99.80 88.09 78.90 99.17 87.89
f-measure 20 2100 92.40 95.24 93.80 96.75 92.60 94.63
Node.js
precision 30 2100 100 83.75 91.16 95.93 95.58 95.58
recall 550 5500 95.69 98.69 97.17 96.38 99.05 96.71
f-measure 80 5500 98.21 96.98 97.59 99.64 95.42 97.48
several files. Second, the length of the applications
analyzed is small. The preprocessing of source code
to deep learning approaches using AST is limited by
the data size to be analyzed. The larger the data, the
more tedious it becomes to perform this preprocess-
ing step. In this type of representation, vector sizes
are directly correlated to the size of the source code
analyzed in training.
6 RELATED WORK
New deep learning applications on speech recognition
and natural languages have motivated recent research
in software engineering and cybersecurity communi-
ties to apply deep learning to understand vulnerable
code patterns and semantics, characterising vulnera-
ble codes. Lin et al. (Lin et al., 2020) review recent
literature adopting deep learning approaches to detect
software vulnerabilities and identify challenges in this
new area.
Maurel et al. (Maurel et al., 2021) compare two
different code representations based on Natural Lan-
guage Processing (NLP) and Programming Language
Processing (PLP) for XSS analysis detection in PHP
and Node.js. Their deep learning models overcame
existing static analyser tools. Our work uses the
same Node.js generator for detecting XSS vulnerabil-
ity with PLP techniques. Different from us, that work
did not analyse multitier languages.
Mitch (Calzavara et al., 2019) is a prototype
that uses machine learning to black-box detection
of CSRF vulnerability. It tries to identify sensi-
tive HTTP requests that require protection against
CSRF by manually labelling HTTP requests sent from
web applications as sensitive or insensitive HTTP re-
quests.
Neutaint (She et al., 2020) uses AFL fuzzer on
programs to generate a list of couples of sources and
sinks. Instead of representing statically source code
in a vector, Neutaint tries to predict the correspond-
ing taint sinks with a neural network for the speci-
fied program. Compared to dynamic taint analysis,
the tracked information flow is not obtained from the
program’s execution but the neural network.
VulDeePecker (Li et al., 2018b) uses BLSTM
neural networks to detect buffer error (i.e., CWE-119)
and resource management errors (i.e., CWE-399) re-
lated to library/API function calls on C and C++
source code. VulDeePecker used two datasets main-
tained by the NIST and the SARD project related to
buffer and resource management errors in C and C++.
Similarly to VulDeePecker, SySeVR (Li et al.,
2018a) uses deep learning to detect vulnerabilities
in C/C++ intra-procedural source code using pro-
gram slicing and Word2vec. As datasets, they used
the Software Assurance Reference Data set (SARD)
project.
DeepXSS (Fang et al., 2018) proposes an XSS
payload detection model based on long-short term
memory (LSTM) recurrent neural networks. COD-
DLE (Abaimov and Bianchi, 2019) is a deep learning-
based intrusion detection prototype to malicious pay-
load related to SQLI and XSS. DeepXSS and COD-
DLE learn the difference between a potentially ma-
licious input, which a malicious user can inject into
user-controllable input of a web application, from a
legitimate input from an ordinary user. Therefore, this
type of detector can be used to validate whether user
input is vulnerable to XSS or secure before the web
application uses it in its program. Unlike our work,
the detectors, which we trained, analyze source code
that uses input controllable by web application users.
They can predict whether a web application is vulner-
able to XSS or secure.
Melicher et al. (Melicher et al., 2021) investigate
whether machine learning to detect DOM XSS vul-
nerabilities. They combine Machine Learning and
Taint tracking analyse to reduce the cost of stand-
alone taint tracking.
MLPXSS (Mokbal et al., 2019) proposes a neu-
ral network-based multilayer perceptron (MLP) to de-
tect XSS attacks. This prototype uses a list of ma-
licious websites and benign websites to generate a
raw database. From this database are extracted URL,
Javascript, and HTML features, Differently from our
work, MLPXSS and Melicher et al. (Melicher et al.,
2021) are focused only on client-side code. More-
over, in MLPXSS, the contexts that link the Javascript
code, the URLs, and HTML are lost by extracting fea-
Comparing the Detection of XSS Vulnerabilities in Node.js and a Multi-tier JavaScript-based Language via Deep Learning
199

tures independent of each other.
Zhang et al. (Zhang et al., 2020) propose a Monte
Carlo Tree Search (MCTS) adversarial example gen-
eration algorithm for XSS payloads. MCTS algorithm
can only generate adversarial examples of XSS traffic
for bypassing XSS payloads detection model. While
we analyze the source code to predict if they are vul-
nerable to XSS, Zhang et al.’s work generates XSS
payloads for web traffic.
Shar and Tan (Shar and Tan, 2013) propose an ap-
proach to predict whether specific program statements
are potentially vulnerable to SQLI or XSS. They de-
veloped a prototype tool called PhpMinerl, based on
Pixy, for handcrafting 21 features of specific PHP
sanitisations of input code. Differently from us, the
granularity of this detector is at the instruction level
and, the functionality to vectorise the samples has
been done manually. Moreover, it is specifically for
PHP.
7 CONCLUSION
In this work, we explore the differences in the
XSS detection learning process of Hashed-AST based
techniques by using single-tier and multi-tier lan-
guages, Node.js and Hop.js. We generated 144
models in one database including HTML/Javascript
and CSS as code in Hop.js and 144 models in a
database that includes HTML/Javascript and CSS as
text. Hop.js obtained a better recall than Node.js de-
spite the lower precision. This implies that our ex-
periments have not shown a major impact on XSS de-
tectors based on deep learning using multitier ASTs
compared to ASTs for Node.js.
Our results are promising since they are better
than popular static analyzers for JavaScript XSS as
shown in previous works (Maurel et al., 2021; App-
Scan, ). For now, our results are based on synthetic
databases and we leave as future wok the creation of
a database to detect XSS in real-world web applica-
tions.
ACKNOWLEDGMENT
This research has been partially supported by the
ANR17-CE25-0014-01 CISC project, the Inria Chal-
lenge SPAI, and CONICET (Argentina) under PIP
2021-2023 id 11220200100430CO. We thank anony-
mous reviewers for their work and Manuel Serrano
for his help with Hop.js.
REFERENCES
Abaimov, S. and Bianchi, G. (2019). Coddle: Code-
injection detection with deep learning. IEEE Access,
7:128617–128627.
Alon, U., Zilberstein, M., Levy, O., and Yahav, E. (2019).
code2vec: Learning distributed representations of
code. Proceedings of the ACM on Programming Lan-
guages, 3(POPL).
AppScan. Appscan scanner for node.js (static mode).
Balzarotti, D., Cova, M., Felmetsger, V., Jovanovic, N.,
Kirda, E., Kruegel, C., and Vigna, G. Saner: Com-
posing static and dynamic analysis to validate saniti-
zation in web applications. In 2008 IEEE Symposium
on Security and Privacy (sp 2008). IEEE. ISSN: 1081-
6011.
Calzavara, S., Conti, M., Focardi, R., Rabitti, A., and
Tolomei, G. (2019). Mitch: A machine learning ap-
proach to the black-box detection of csrf vulnerabili-
ties. In IEEE European Symposium on Security and
Privacy (EuroS&P). IEEE.
Chen, X., Li, M., Jiang, Y., and Sun, Y. (2019). A compari-
son of machine learning algorithms for detecting XSS
attacks. In Sun, X., Pan, Z., and Bertino, E., editors,
Artificial Intelligence and Security - 5th International
Conference, ICAIS, volume 11635 of Lecture Notes in
Computer Science, pages 214–224. Springer.
Choi, M., Jeong, S., Oh, H., and Choo, J. (2017).
End-to-end prediction of buffer overruns from raw
source code via neural memory networks. CoRR,
abs/1703.02458.
Cooper, E., Lindley, S., Wadler, P., and Yallop, J. (2006).
Links: Web programming without tiers. In Inter-
national Symposium on Formal Methods for Compo-
nents and Objects, pages 266–296. Springer.
Dam, H. K., Tran, T., Pham, T., Ng, S. W., Grundy, J., and
Ghose, A. (2017). Automatic feature learning for vul-
nerability prediction. CoRR, abs/1708.02368.
Doup
´
e, A., Cova, M., and Vigna, G. (2010). Why johnny
can’t pentest: An analysis of black-box web vulnera-
bility scanners. In Kreibich, C. and Jahnke, M., ed-
itors, Detection of Intrusions and Malware, and Vul-
nerability Assessment, 7th International Conference,
DIMVA Proceedings, volume 6201 of Lecture Notes
in Computer Science. Springer.
Fang, Y., Li, Y., Liu, L., and Huang, C. (2018). Deepxss:
Cross site scripting detection based on deep learning.
In Proceedings of the 2018 Int. Conf. on Computing
and Artificial Intelligence, pages 47–51. ACM.
Gundy, M. V. and Chen, H. (2009). Noncespaces: Using
randomization to enforce information flow tracking
and thwart cross-site scripting attacks. In Proceed-
ings of the Network and Distributed System Security
Symposium, NDSS. The Internet Society.
Lekies, S., Kotowicz, K., Groß, S., Nava, E. A. V., and
Johns, M. (2017). Code-reuse attacks for the web:
Breaking cross-site scripting mitigations via script
gadgets. In Thuraisingham, B. M., Evans, D., Malkin,
T., and Xu, D., editors, ACM SIGSAC Conference on
Computer and Communications Security. ACM.
ICISSP 2022 - 8th International Conference on Information Systems Security and Privacy
200

Li, Z. and Zhou, Y. (2005). Pr-miner: automatically extract-
ing implicit programming rules and detecting viola-
tions in large software code. ACM SIGSOFT Software
Engineering Notes, 30(5):306–315.
Li, Z., Zou, D., Xu, S., Jin, H., Zhu, Y., Chen, Z., Wang,
S., and Wang, J. (2018a). Sysevr: A framework for
using deep learning to detect software vulnerabilities.
CoRR, abs/1807.06756.
Li, Z., Zou, D., Xu, S., Ou, X., Jin, H., Wang, S., Deng,
Z., and Zhong, Y. (2018b). VulDeePecker: A deep
learning-based system for vulnerability detection. In
Network and Distributed System Security Symposium.
NDSS.
Lin, G., Wen, S., Han, Q.-L., Zhang, J., and Xiang, Y.
(2020). Software vulnerability detection using deep
neural networks: A survey. Proceedings of the IEEE,
108(10):1825–1848.
Lin, G., Xiao, W., Zhang, J., and Xiang, Y. (2019).
Deep learning-based vulnerable function detection: A
benchmark. In International Conference on Informa-
tion and Communications Security, pages 219–232.
Springer.
Lin, G., Zhang, J., Luo, W., Pan, L., Xiang, Y., de Vel, O. Y.,
and Montague, P. (2018). Cross-project transfer rep-
resentation learning for vulnerable function discovery.
IEEE Trans. Ind. Informatics, 14(7):3289–3297.
Livshits, B. and Chong, S. (2013). Towards fully automatic
placement of security sanitizers and declassifiers. In
Giacobazzi, R. and Cousot, R., editors, The 40th An-
nual ACM SIGPLAN-SIGACT Symposium on Princi-
ples of Programming Languages, POPL ’13, Rome,
Italy - January 23 - 25, 2013. ACM.
Luo, Z., Rezk, T., and Serrano, M. (2011). Automated
code injection prevention for web applications. In
M
¨
odersheim, S. and Palamidessi, C., editors, Theory
of Security and Applications - Joint Workshop, volume
6993 of Lecture Notes in Computer Science. Springer.
Maurel, H., Vidal, S., and Rezk, T. (2021). Statically iden-
tifying XSS using Deep Learning. In In Proceedings
of the 18th International Conference on Security and
Cryptography, , pages 99-110. SECRYPT.
Melicher, W., Das, A., Sharif, M., Bauer, L., and Jia, L.
(2018). Riding out domsday: Towards detecting and
preventing DOM cross-site scripting. In 25th Annual
Network and Distributed System Security Symposium,
NDSS. The Internet Society.
Melicher, W., Fung, C., Bauer, L., and Jia, L. (2021). To-
wards a lightweight, hybrid approach for detecting
DOM XSS vulnerabilities with machine learning. In
WWW ’21: The Web Conference 2021, Virtual Event,
pages 2684–2695. ACM / IW3C2.
Mokbal, F. M. M., Dan, W., Imran, A., Jiuchuan, L., Akhtar,
F., and Xiaoxi, W. (2019). Mlpxss: An integrated
xss-based attack detection scheme in web applications
using multilayer perceptron technique. IEEE Access,
7:100567–100580.
Node.js (2021). nodejs.org github repository. https://github.
com/nodejs/nodejs.org.
OWASP (2021). Cross site scripting prevention cheat
sheet. https://cheatsheetseries.owasp.org/cheatsheets/
Cross
Site Scripting Prevention Cheat Sheet.html.
Russell, R. L., Kim, L. Y., Hamilton, L. H., Lazovich, T.,
Harer, J. A., Ozdemir, O., Ellingwood, P. M., and Mc-
Conley, M. W. (2018). Automated vulnerability detec-
tion in source code using deep representation learning.
CoRR, abs/1807.04320.
Schoepe, D., Balliu, M., Pierce, B. C., and Sabelfeld, A.
(2016). Explicit secrecy: A policy for taint tracking.
In IEEE European Symposium on Security and Pri-
vacy, EuroS&P. IEEE.
Serrano, M. (2006). Hop, multitier web programming.
Serrano, M., Gallesio, E., and Loitsch, F. (2006). Hop: a
language for programming the web 2. 0. In OOPSLA
Companion, pages 975–985.
Serrano, M. and Prunet, V. (2016). A glimpse of hopjs.
In 21th Sigplan Int’l Conference on Functional Pro-
gramming (ICFP), pp. 188–200. ICFP.
Sestili, C. D., Snavely, W. S., and VanHoudnos, N. M.
(2018). Towards security defect prediction with AI.
CoRR, abs/1808.09897.
Shar, L. K. and Tan, H. B. K. (2013). Predicting SQL in-
jection and cross site scripting vulnerabilities through
mining input sanitization patterns. Inf. Softw. Technol.,
55(10):1767–1780.
She, D., Chen, Y., Shah, A., Ray, B., and Jana, S. (2020).
Neutaint: Efficient dynamic taint analysis with neural
networks. In 2020 IEEE Symposium on Security and
Privacy (SP). IEEE.
Som
´
e, D. F., Bielova, N., and Rezk, T. (2016). On the con-
tent security policy violations due to the same-origin
policy. CoRR, abs/1611.02875.
Staicu, C.-A., Pradel, M., and Livshits, B. (2018). SYN-
ODE: Understanding and automatically preventing in-
jection attacks on NODE.JS. In Network and Dis-
tributed System Security Symposium. NDSS.
Wang, S., Liu, T., and Tan, L. (2016). Automatically
learning semantic features for defect prediction. In
IEEE/ACM 38th International Conference on Soft-
ware Engineering (ICSE), pages 297–308. IEEE.
Weisenburger, P., Wirth, J., and Salvaneschi, G. (2020).
A survey of multitier programming. ACM Comput.
Surv., 53(4):81:1–81:35.
Zhang, X., Zhou, Y., Pei, S., Zhuge, J., and Chen, J. (2020).
Adversarial examples detection for XSS attacks based
on generative adversarial networks. IEEE Access,
8:10989–10996.
Comparing the Detection of XSS Vulnerabilities in Node.js and a Multi-tier JavaScript-based Language via Deep Learning
201
