
Text Classification in the Brazilian Legal Domain
Gustavo M. C. Coelho
1 a
, Alimed Celecia
1 b
, Jefferson de Sousa
1 c
, Melissa Cavaliere
1 d
,
Maria Julia Lima
1 e
, Ana Mangeth
2 f
, Isabella Frajhof
2 g
, Cesar Cury
3 h
, Marco Casanova
1 i
1
Tecgraf, PUC-Rio, Rio de Janeiro, Brazil
2
LES, PUC-Rio, Rio de Janeiro, Brazil
3
Escola da Magistratura do Estado do Rio de Janeiro, Rio de Janeiro, Brazil
Keywords:
Document Embedding, Text Classification, Natural Language Processing.
Abstract:
Text classification is a popular Natural Language Processing task that aims at predicting the categorical values
associated with textual instances. One of the relevant application fields for this task is the legal domain, which
involves a high volume of unstructured textual documents. This paper proposes a new model for the task of
classifying legal opinions related to consumer complaints according to the moral damage value. The proposed
model, named MuDEC (Multi-step Document Embedding-Based Classifier), combines Doc2vec and SVM for
feature extraction and classification, respectively. To optimize the classification performance, the model uses
a combination of methods, such as oversampling for imbalanced datasets, clustering for the identification of
textual patterns, and dimensionality reduction for complexity control. For performance evaluation, a 6-class
dataset of 193 legal opinions related to consumer complaints was created in which each instance was manually
labeled according to its moral damage value. A 10-fold stratified cross-validation resampling procedure was
used to evaluate different models. The results demonstrated that, under this experimental setup, MuDEC
outperforms baseline models by a significant margin, achieving 78.7% of accuracy, compared to 61.1% for a
SIF classifier and 65.2% for a C-LSTM classifier.
1 INTRODUCTION
Text classification is a popular Natural Language Pro-
cessing (NLP) task that aims at predicting the categor-
ical values associated with textual instances. Such in-
stances might be composed of phrases, paragraphs, or
even entire documents, naturally increasing the task’s
complexity.
Kowsari et al. (2019) summarizes most text clas-
sification systems as a four-step procedure. The
first step is feature extraction, where textual units
are converted into numerical features. Typical meth-
ods for this purpose are Word2vec (Mikolov et al.,
a
https://orcid.org/0000-0003-2951-4972
b
https://orcid.org/0000-0001-9889-795X
c
https://orcid.org/0000-0002-5928-9959
d
https://orcid.org/0000-0003-1723-9897
e
https://orcid.org/0000-0003-3843-021X
f
https://orcid.org/0000-0003-1624-1645
g
https://orcid.org/0000-0002-3901-4907
h
https://orcid.org/0000-0003-1400-1330
i
https://orcid.org/0000-0003-0765-9636
2013) for word-level representation and Doc2vec (Le
and Mikolov, 2014) for document-level representa-
tion. The second step is an optional dimensional-
ity reduction over the results of the first step. The
third step follows with a classification method, such
as Na
¨
ıve Bayes, support vector machines (SVM), gra-
dient boosting trees and random forests. Finally, the
fourth step is evaluation, where the applicable metrics
are analysed.
One of the relevant applications of text classifica-
tion is the legal domain, which involves a high volume
of unstructured textual documents (Fernandes et al.,
2022). The high cost of manually reviewing those
documents is one of the main reasons for the growing
research in this domain (Wei et al., 2018). If prop-
erly classified by relevant labels, such documents can
provide valuable structured information with regard
to past lawsuits, allowing better assessment by legal
professionals, supporting automated recommendation
systems, or other data-driven applications.
This paper is positioned in the context of the auto-
mated analysis of legal opinions related to consumer
Coelho, G., Celecia, A., de Sousa, J., Cavaliere, M., Lima, M., Mangeth, A., Frajhof, I., Cury, C. and Casanova, M.
Text Classification in the Brazilian Legal Domain.
DOI: 10.5220/0011062000003179
In Proceedings of the 24th International Conference on Enterprise Information Systems (ICEIS 2022) - Volume 1, pages 355-363
ISBN: 978-989-758-569-2; ISSN: 2184-4992
Copyright
c
2022 by SCITEPRESS – Science and Technology Publications, Lda. All rights reserved
355

complaints. A legal opinion is “a written explanation
by a judge or group of judges that accompanies an or-
der or ruling in a case, laying out the rationale and
legal principles for the ruling”
1
. A consumer com-
plaint is “an expression of dissatisfaction on a con-
sumer’s behalf to a responsible party”.
2
In such cases,
the legal opinion contains specific provisions refer-
ring to the plaintiff’s claim, such as moral damage,
material damage, and legal fees due by the defeated
party. These provisions are always related to a mon-
etary value. The use of the term legal opinion is re-
stricted to this particular context in what follows.
As a proof of concept, this paper focuses on the
following specific problem:
• Identify the moral damage value in legal opinions
in the context of consumer complaints.
This problem is challenging since legal opinions
are typically long pieces of text, running through sev-
eral pages, and are written in a variety of styles. A tra-
ditional approach, based on Natural Language tools,
would resort to a manually constructed set of rules
that locate the section of the text that expresses the
desired clause and extract the associated value (Mi-
naee et al., 2021). However, such rules are difficult to
define and maintain.
This paper then introduces MuDEC (Multi-
step Document Embedding-Based Classifier), a new
model that addresses the above question as a clas-
sification problem, justified by the small number of
unique values for moral damage compensation ob-
served in practice. MuDEC combines Doc2vec and
SVM for feature extraction and classification, respec-
tively. To optimize the classification performance, we
propose a combination of methods, such as oversam-
pling for imbalanced datasets, clustering for identifi-
cation of textual patterns, and dimension reduction for
complexity control. We demonstrate that these meth-
ods combined with our main model can decrease the
need for larger annotated datasets when compared to
other models.
To validate the model, the paper describes exper-
iments that use a dataset containing 193 legal opin-
ions (in Brazilian Portuguese) enacted by lower court
judges in the State Court of Rio de Janeiro in the con-
text of consumer complaints involving electric power
companies. It must be noted that such documents are
public. Each legal opinion in the dataset was manu-
ally classified as explained in Section 4.1.
A 10-fold stratified cross-validation resampling
method was used to evaluate different models. We
demonstrate that, under this experimental setup, our
1
https://en.wikipedia.org/wiki/Legal opinion
2
https://en.wikipedia.org/wiki/Consumer complaint
model outperforms by a significant margin the base-
line models, which are based on Smooth Inverse Fre-
quency (SIF) and a combination of Convolutional
Neural Network and Long Short-Term Memory (C-
LSTM).
The rest of this paper is organized as follows. Sec-
tion 2 covers related work. Section 3 contains a de-
tailed description of the proposed model. Section 4
presents the results achieved. Section 5 summarizes
the conclusions and suggests future work.
2 RELATED WORK
Feature extraction from textual instances evolved
from Term Frequency (TF) and Term Frequency-
Inverse Document Frequency (TF-IDF) (Salton and
Buckley, 1988) to word embeddings such as
Word2vec (Mikolov et al., 2013) and Global Vectors
for Word Representation (GloVe) (Pennington et al.,
2014). The main contribution from word embeddings
is the representation of a word as an n dimensional
vector in an unsupervised approach, allowing the use
of pre-trained vectors in different applications.
Despite the success of word embeddings for se-
mantic representation, feature extraction for text clas-
sification through the use of this method is still an
open research topic. This is due to the fact that doc-
uments are composed of a sequence of words, which,
after conversion, are mapped into a sequence of n di-
mensional vectors of various lengths. Since most ma-
chine learning methods require fixed-length feature
vectors, the use of word embeddings for text classifi-
cation requires a specific strategy to map the sequence
of vectors into a valid format while preserving enough
information from the original feature sequence.
To overcome this limitation, several strategies
have been proposed by different authors. Zhou et al.
(2015) applied a padding method, using the maximum
document length in the dataset as a reference and fill-
ing the remaining documents with special symbols at
the end. By doing so, each document can be con-
verted to a vector of fixed dimension composed of its
word embeddings, and the output can be further used
as input for a classifier. Arora et al. (2017) proposed
a simple average of the word vectors in the sentence,
weighted by their inverse frequency and later removal
of the projections of the average vectors on their first
singular vector (“common component removal”). The
method is named Smooth Inverse Frequency (SIF),
and interestingly, besides its simplicity, it outperforms
several complex models, including Recurrent Neural
Networks (RNNs) and LSTMs.
In a different approach, Le and Mikolov (2014)
ICEIS 2022 - 24th International Conference on Enterprise Information Systems
356

proposed an unsupervised algorithm for a fixed-
length feature representation from sequence of words.
Initially named as Paragraph Vector, the model be-
came known as Doc2vec, inheriting important aspects
from Word2vec, such as the semantic representation
of words. As an important advantage when compared
to SIF, the model takes into account the word order, at
least for a small context.
Depending on the method chosen for feature
extraction and its hyperparameters, the resulting
features vector might have high dimension, lead-
ing to problems with time complexity and mem-
ory consumption. To mitigate this problem, differ-
ent methods have been used for dimensional reduc-
tion. Kowsari et al. (2019) lists some of the applica-
ble methods for this task, such as Principal Compo-
nent Analysis (PCA), Linear Discriminant Analysis
(LDA), Non-Negative Matrix Factorization (NMF),
and Random Projection.
One of the natural challenges of a regular classi-
fication task is the presence of imbalanced datasets.
This is the case of our domain since some com-
pensation values for moral damage were signifi-
cantly less frequent than others, as observed in fig-
ure 2. The simple approach of treating these val-
ues as outliers and removing them from the train-
ing dataset has serious limitations since although
rare, they are still significant instances that should
be addressed by the model. The option of bal-
ancing the dataset by under-sampling the majority
classes can also lead to poor classification perfor-
mance, especially in contexts where the volume of
labeled data is scarce. Menardi and Torelli (2014)
treated the dataset imbalance problem by oversam-
pling the minority class based on a smoothed boot-
strap re-sampling technique. Chawla et al. (2002)
follows a similar oversampling strategy, but with the
introduction of synthetic minority class examples.
The method, called Synthetic Minority oversampling
Technique (SMOTE), has shown significant improve-
ments in imbalanced datasets for a variety of applica-
tions from several different domains (Fern
´
andez et al.,
2018).
There is a small number of recent papers that ad-
dress the task of document classification in the Brazil-
ian legal domain. For example, de Araujo et al. (2020)
introduced a dataset constructed from digitalized le-
gal documents of the Brazilian Supreme Court, with
692 thousand instances. In the paper, several models,
based on bag-of-words, CNNs, RNN’s and boosting
algorithms, were implemented as baselines. Although
similar, our work differs from this paper by the task
definition since their focus was on document classi-
fication and theme assignment, while our task aims
at classifying lower-level classes, such as the moral
damage values.
In a different approach, Luz de Araujo et al.
(2018) addressed the problem of information extrac-
tion of documents from Brazilian legal text. More
specifically, the authors focused on named entity
recognition (NER) for the extraction of entities re-
lated to the legal context. Similarly, Fernandes et al.
(2022) proposes a model to extract value from Brazil-
ian Court decisions by using models based on Bidi-
rectional LSTMs and Conditional Random Fields
(CRFs). These methods could be seen as another
valid approach to our proposed task, where the moral
damage value would be interpreted as an entity class.
The main reason for not following this approach was
the need for textual annotations of word positions in
the text and their related entity classes, which we be-
lieve adds complexity to the annotation process when
compared to text classification, where the annotation
is limited to simply assigning one class for an entire
document.
Lastly, a notable trend in recent research is the use
of Deep Learning methods for the text classification
task (Minaee et al., 2021). As an example, Zhou et al.
(2015) proposed a combination of pre-trained word
embeddings, a CNN, and a RNN connected to a soft-
max layer for final classification. The model, called
C-LSTM, extracts higher-level phrase representations
from the sequence of word embeddings by imple-
menting a one-dimensional convolution. The result-
ing output is fed to an LSTM to obtain the sentence
representation. The performance evaluation described
in this work showed that this model provides excel-
lent results for the sentiment classification and ques-
tion classification tasks, which are closely related to
our goal.
3 DESCRIPTION OF THE
PROPOSED METHOD
Our proposed method is divided into six sequential
steps. Figure 1 illustrates these steps by representing
the training and evaluation procedure.
The first step adjusts the textual input according to
regular text pre-processing procedures. This is a spe-
cially important step considering that legal opinions
are structured differently from other domains. The
punctuation, line breakers, and excessive spaces are
removed, and all upper case letters are converted to
lower case.
To minimize the task’s complexity, the document
is filtered to contain only the operative part of the
judgement, where the lower or Appellate Court judge
Text Classification in the Brazilian Legal Domain
357

presents the judicial solution to the lawsuit (Fernan-
des et al., 2022). To identify this section, a list of
regular expressions was used. The list is composed of
expressions such as “given these considerations” and
“in the face of the above” as a reference for splitting
the document and removing the first section. If the
filter fails to identify these expressions, the end sec-
tion is obtained by considering the document’s last m
characters. For our experimental setup, m = 2, 500
was empirically found to be the most suitable value to
comprise most of the end sections. Lastly, stopwords
are removed, and the words are tokenized.
The first step is therefore highly dependent on the
type of legal document in question and must be ad-
justed accordingly for other contexts.
After the division between train and test sets, the
second step extracts the features by using Doc2vec.
The method is trained exclusively by the training text
instances resulting from the previous filtering step,
with no use of external knowledge from pre-trained
embeddings. After training, the model is applied to
both the train and test sets, converting each instance
composed of a list of textual tokens with multiple
sizes to a numerical feature vector of pre-defined di-
mension n. In this step, the moral damage values ex-
pressed in different formats within the filtered text are
expected to be mapped into the n-dimensional vec-
tors.
Following feature extraction, the third step applies
an oversampling method to the train set for treating
its imbalance. For this task, we chose SMOTE as
our oversampling algorithm. By doing so, synthetic
instances are created using a k nearest neighbors ap-
proach, where k instances features are randomly cho-
sen from the minority classes, and a synthetic in-
stance is created along the line segments joining them
(Chawla et al., 2002). This procedure is repeated until
the dataset is evenly distributed.
The fourth step aims at identifying clusters of sim-
ilar instances by applying the k-means clustering al-
gorithm to the feature vectors. The idea behind this
step is based on the existence of sets of instances with
a similar format (e.g., legal opinions using a similar
writing style). Intuitively, this tasks provides a vari-
able that indicates a relation between instances of the
same cluster, which may improve the classifier’s per-
formance. The cluster to which each instance belongs
is turned into a new one-hot-encoded categorical fea-
ture and added to the related feature vector.
The fifth step applies a dimensional reduction by
a pre-defined continuous factor within the range of 0
and 1. The output dimension is equal to this factor
multiplied by the input dimension. For this step, we
chose PCA as the reduction method. PCA aims at ex-
tracting the important information from the features
by creating a set of orthogonal variables called prin-
cipal components. Essentially, the principal compo-
nents are obtained as linear combinations of the orig-
inal features, where the first component is required to
have the largest possible variance and the second is
orthogonal to the first. This process is repeated for
the remaining components until the number of com-
ponents is equal to the output dimension (Abdi and
Williams, 2010). Ideally, the dimension reduction
factor should be chosen to minimize the model com-
plexity while preserving enough information from the
original features.
The last step implements a machine learning clas-
sifier that assigns each instance to one of the possible
classes. The classifier is fed with the real instance
classes as target variables and the results of the last
step as input, i.e., the PCA components from the con-
catenation of (i) the feature vectors of filtered end sen-
tences and (ii) the one-hot-encoded representation of
the cluster to which each end sentence belongs. This
step adopts an SVM classifier, which is one of the
most popular machine learning algorithms, based on
the concept of a hyperplane (also called kernel) con-
struction that maximizes the margins that separate the
classes in the feature space (Vapnik, 2006). Although
the kernel can be defined by different functions, such
as polynomials and radius basis functions, a linear
kernel is used since in practice, it consistently out-
performs the other kernel types for this task.
4 RESULTS
4.1 Experimental Setup
The experiments used a dataset containing 193 man-
ually annotated legal opinions (in Brazilian Por-
tuguese) enacted by lower court judges in the State
Court of Rio de Janeiro in the context of consumer
complaints involving electric power companies. Each
legal opinion in the dataset was manually analysed to
locate the moral damage value and labeled with the
value v found. The labels were then mapped to one of
six possible classes – 0; 1,000; 2,000; 3,000; 4,000;
and 5,000 – where Class 0 indicates no moral dam-
age compensation (v = 0), Class 1,000 that v = 1, 000,
and so on. Values outside these classes are rare and
not present in the dataset. The distribution of v in the
dataset is expressed by Figure 2.
The experiments for hyperparameter tuning were
performed in a 10-fold stratified cross-validation
setup, implemented using the 193 annotated in-
stances, resulting in the definition of 10 different com-
ICEIS 2022 - 24th International Conference on Enterprise Information Systems
358
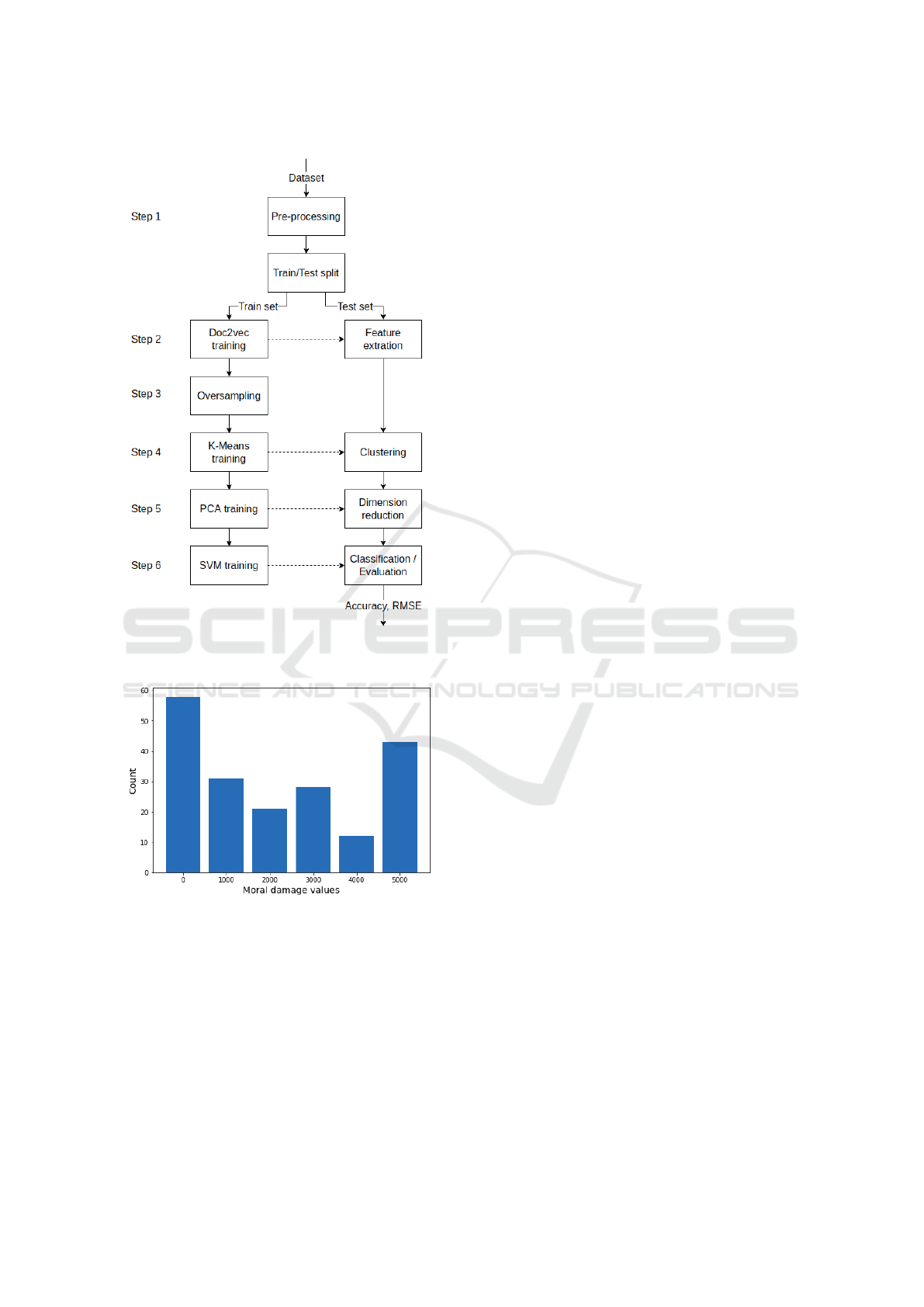
Figure 1: Sequential steps of the model’s training and eval-
uation process.
Figure 2: Distribution of classes in the dataset.
binations of train and test datasets, where the test set
contained 19 instances on average. In every combi-
nation, the test sampling was adjusted to result in a
similar distribution of classes when compared to the
train set. In section 4.3 we discuss the effect of differ-
ent dataset sizes in this setup.
A grid search method was used to explore 2,200
combinations of the following parameters:
• Doc2vec vector size: 100, 200, 300, 400 and 500.
• Number of Doc2vec training epochs: 100, 200,
300, and 500.
• Use of oversampling: true or false.
• Number of k-means clusters: range of 0 to 100
with a step of 10, where 0 means k-means is not
used.
• PCA factor for dimension reduction: range of 0.2
to 1.0, with a step of 0.2, where 1.0 means PCA is
not used.
The linear SVM kernel was empirically found to
be the best option for this setup and was fixed dur-
ing the grid search. The Doc2vec version used was
the distributed bag of words (PV-DBOW), and the Eu-
clidean distance was used for the K-Means clustering.
For each grid search iteration, two main evalua-
tion metrics were stored: the overall accuracy and the
root mean squared error (RMSE). Even though the
problem is generally treated as a classification task,
the RMSE was used to analyse how far off are the
wrong predictions compared to the real moral dam-
age values. This is an important aspect of the domain,
where the quality of a classifier is impacted not only
by the proportion of the corrected predictions but also
by how distant are the wrong predictions from the real
values. In other words, a 5,000 Reais moral damage
value, predicted as 4,000 Reais, is less harmful than if
it is predicted as zero, for instance.
For a baseline comparison, two other models
were implemented over the same dataset and cross-
validation setup. The first model follows the same
steps described in Figure 1, replacing Doc2vec for the
smooth inverse frequency (SIF) (Arora et al., 2017)
as the feature extraction method. For the extraction
of word embeddings to be summarized by SIF, we
used the skip-gram version of Word2vec. For this
model, the following combination of parameters was
used during the grid search process:
• Word2vec vector size: 100, 300, and 600.
• SVM kernel used: linear, polynomial, or radial
basis function.
• Use of oversampling: true or false.
• Number of K-Means clusters: range of 0 to 100
with a step of 10, where 0 means k-means is not
used.
• PCA factor for dimension reduction: range of 0.2
to 1.0, with a step of 0.2, where 1.0 means PCA is
not used.
The second model is based on C-LSTM as a deep
learning version of text classification. The model was
structured based on the original paper, as the example
Text Classification in the Brazilian Legal Domain
359

in Figure 3 shows, where: the Word2vec dimension is
set to 100; 300 filters of size 3 are used during the con-
volution, and the instances are padded to the length of
253.
Figure 3: Summary of implemented C-LSTM model.
Once again, skip-gram Word2vec was used as
word embeddings and, for parameter tuning, the fol-
lowing combination of parameters was tested during
grid search:
• Word2vec vector size: 100, 300, and 600.
• Number of filters for convolution: 100, 200, and
300.
• Size of filter used for convolution: 3, 4, and 5.
• Dimension of the LSTM model: 100, 200, and
300.
• Use of oversampling: true or false.
Following the original C-LSTM implementation,
an L2 regularization factor of 0.001 is applied to the
softmax layer and a dropout probability of 0.5 to the
LSTM layer.
All models were implemented in Python, using
standard libraries such as Numpy, Scikit-learn, Ten-
sorflow, Keras, and Gensim. Pre-trained skip-gram
Word2vec embeddings in Portuguese, provided by
Hartmann et al. (2017), were used. The experiments
were performed under an Intel i7 CPU with 32 GB
of RAM memory and an 8 GB NVIDIA graphic card
(used for C-LSTM training).
4.2 Main Results
Table 1 shows the main performance metrics of the
different models when the optimal parameters found
are applied. The results for the optimal parameters
obtained through the grid search show that MuDEC
outperforms the baseline models SIF and C-LSTM by
17.6% and 13.5% in accuracy and 589.7 and 307.7 in
RMSE, respectively.
The best combination of hyperparameters of our
model, which resulted in the lowest mean accuracy
and mean RMSE, were:
• 400-dimensional Doc2vec embeddings
• 200 Doc2vec training epochs
• Oversampling used
Table 1: Model’s performance under 10-fold stratified
cross-validation.
Model
Mean ac-
curacy
Accuracy
standard
deviation
Mean
RMSE
MuDEC 78.7% 3.7% 1304.3
SIF 61.1% 10.3% 1894.0
C-LSTM 65.2% 11.1% 1611.0
• 50 K-Means clusters
• PCA not used
SIF had the best combination of parameters with
600-dimensional Word2vec embeddings, a radial ba-
sis function as SVM kernel, oversampling used, and
no PCA reduction. C-LSTM achieved the best perfor-
mance when using 600-dimensional Word2vec em-
beddings, 300 convolutional filters of size 5, 100-
dimensional LSTM layer, 300 training epochs, and
oversampling enabled.
A more detailed analysis of the sensitivity of the
parameters in Figure 4, shows their impact on the pro-
posed model. The graphs are plotted by computing
the mean accuracy and mean running time for each
parameter value throughout the entire grid search ex-
amples, providing a general overview of its results.
Figure 4a shows a peak in the mean accuracy for
300-dimensional Doc2vec feature vectors, implying
that lower dimension vectors are not able to properly
map the information granularity needed for the task,
while higher dimension vectors may add unneeded
complexity to the model. The running time increases
with the vector dimension, as an expected result of
complexity added by higher dimensions.
The different Doc2vec training epochs shown in
Figure 4b indicate that the model is subject to over-
fitting when Doc2vec is trained for more than 200 it-
erations, while the time complexity increases almost
linearly with the number of epochs.
The number of clusters illustrated in Figure 4c
interestingly shows a constant increase of accuracy
with the number of clusters, with a sudden drop when
reaching 100. This may indicate a high variety of dif-
ferent patterns seen in the documents. However, fur-
ther conclusions regarding this method are complex
due to the low number of training instances (174 on
average). The increase in the number of clusters nat-
urally adds complexity to the K-Means algorithm and
input features to the classifier since the cluster fea-
tures are one-hot-encoded. This effect is expressed
by the running time curve.
The PCA dimension reduction in Figure 4d indi-
cates that its use slightly degrades the model’s per-
formance in terms of accuracy. At the same time,
PCA significantly reduces the model’s time complex-
ICEIS 2022 - 24th International Conference on Enterprise Information Systems
360

(a) Vector dimensions.
(b) Doc2vec training epochs.
(c) Number of clusters.
(d) PCA output dimension factor (1.0 means PCA
is not applied).
Figure 4: Grid search results for different combinations of
parameters.
ity. The reduction of feature dimensions to 80% of its
original size degrades the accuracy by around 0.5%
on average, while the running time is reduced from
44 to 38 seconds.
Lastly, Table 2 shows a small increase in accuracy
by the use of SMOTE, on average by 0.4%.
Table 2: Grid search results for oversampling.
Metric
Oversampling
used
Oversampling
not used
Mean accu-
racy
73.3% 72.9%
Mean running
time
49.7 s 44.5 s
Figure 5 illustrates another comparison between
the models by presenting the confusion matrices re-
sulting from the predictions of each model when the
optimal parameters are applied. In this comparison,
the models are trained and evaluated under the same
combination of train and test datasets by using one
of the 10-fold cross validation distributions. Note
that, since Figure 5 refers to a particular dataset com-
bination, the accuracy values differ from the cross-
validation mean accuracy shown in Table 1.
4.3 Model Analysis
The superior performance of the proposed model,
when compared to the baselines, is especially relevant
when considering the scarcity of training instances.
The majority of the related research on text classifica-
tion relies on substantially larger datasets. C-LSTM,
for instance, was originally introduced by training
datasets of at least 5,000 instances. In the context of
expensive data annotation, the ability to achieve good
results with fewer instances can be a significant ad-
vantage.
It is also relevant to note that Doc2vec is, in fact
able to map a detailed information, such as the moral
damage value, from relatively large pieces of texts, of
1,700 characters on average. This shows the potential
of expanding this classification task to additional pro-
visions, other than the moral damage value, possibly
allowing the model to become a useful tool for infor-
mation extraction from legal documents, even pertain-
ing to other domains.
In spite of outperforming the baselines, we ac-
knowledge that the model’s end performance should
be improved for its effective utilization due to the
sensitivity of the legal domain. The example illus-
trated by Figure 5a shows the possibility of errors
such as predicting a value of 1,000 Reais for an in-
stance where the true value is 3,000 Reais. This can
lead to unfair assessments caused by misled informa-
tion. As a possible solution, the increase of the train-
ing dataset can lead to more acceptable results. Fig-
ure 6 shows the relation between the cross-validation
Text Classification in the Brazilian Legal Domain
361
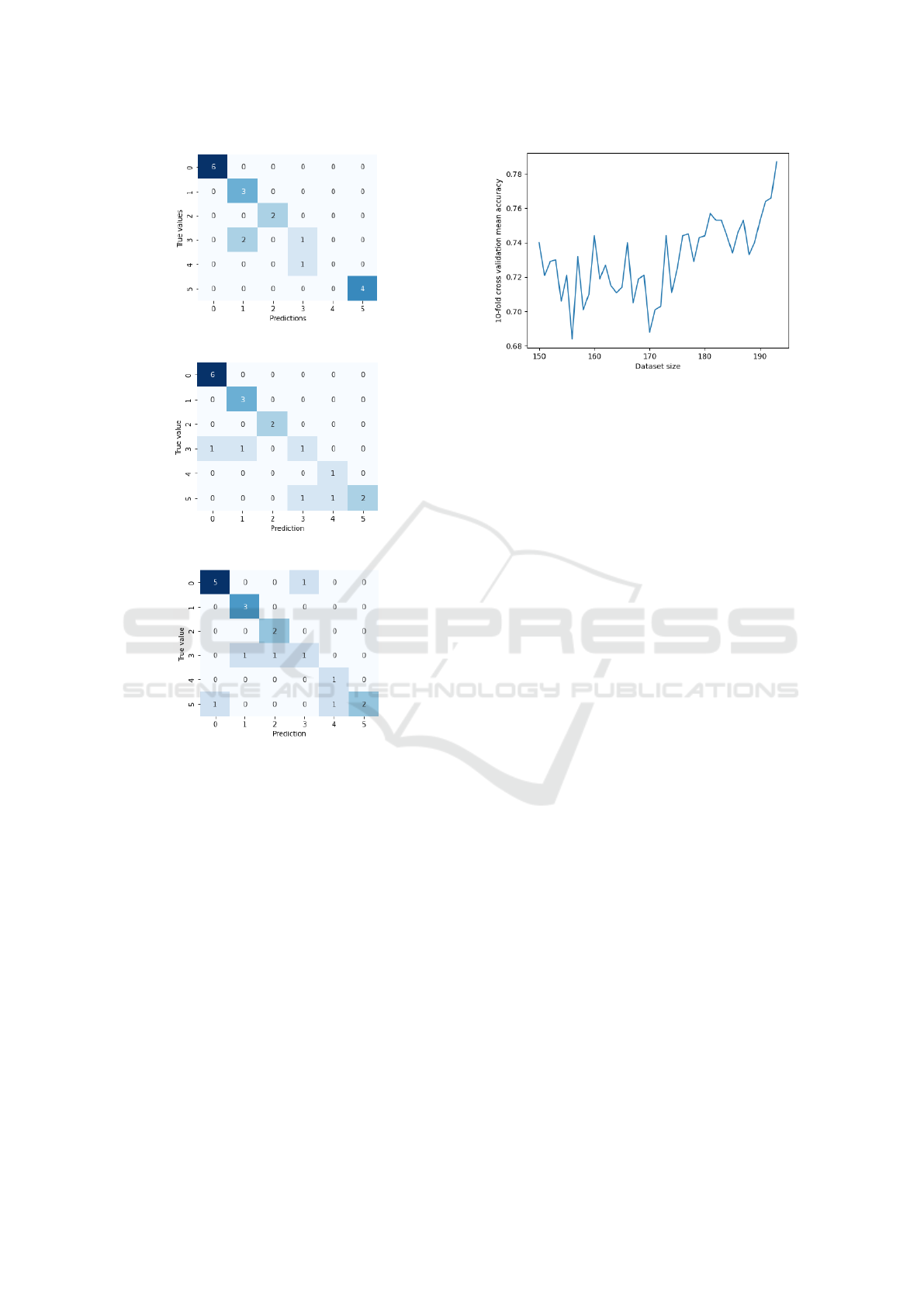
(a) MuDEC. Accuracy: 84%.
(b) SIF. Accuracy: 79%.
(c) C-LSTM. Accuracy: 74%.
Figure 5: Confusion matrices of each model under the same
test data.
accuracy and the dataset size, suggesting a growing
trend in accuracy when adding new instances. This re-
lation suggests that the increase of the dataset leads to
more accurate Doc2vec embeddings, better oversam-
pling or cluster definitions, leading to higher overall
accuracy. The optimal dataset size is to be evaluated
both by the real model’s performance, when applied
to larger datasets, and by the domain requirements re-
lated to accuracy and other evaluation metrics. In any
case, we have strong evidence that relates our model
to the most cost-effective method when related to an-
notation efforts.
Figure 6: MuDEC’s mean accuracy by dataset size.
5 CONCLUSIONS
The results of the paper show that the proposed
model, mainly based on Doc2vec and SVM, outper-
forms the baselines by a substantial margin in the task
of classifying the moral damage value in the legal
opinion of the lower court judges related to consumer
complaints involving electric power companies. The
results are especially relevant when considering the
reduced size of the training dataset, as compared to
similar text classification approaches.
The additional methods included in the main
model slightly improved the model’s performance.
The grid search results show that while oversampling
and clustering increase accuracy, PCA reduces the av-
erage running time. In the future, more robust hy-
perparameter optimization methods, such as Bayesian
Optimization (Snoek et al., 2012) or Evolutionary Op-
timization, (Kim and Cho, 2019) should be consid-
ered, possibly resulting in a more detailed analysis
of the model’s sensibility to these methods. The ad-
dition of new annotated instances, especially the mi-
nority classes, might lead to better cluster definitions
and synthetic oversampling, increasing the impact of
these methods on the overall results.
Although PCA decreases the model’s running
time, the negative impact on the accuracy suggests
the need for testing different dimensionality reduc-
tion methods. In addition to other similar techniques,
this step can be replaced by a feature selection method
that, instead of transforming the features into princi-
pal components, simply removes the non-correlated
features, leaving only a portion of the original vari-
ables.
To expand the comparison, further adjustments
can be applied to the baseline models, such as fine-
tuning word embedding, where the train set can be
used to continue the training of word vectors, provid-
ICEIS 2022 - 24th International Conference on Enterprise Information Systems
362

ing more domain-specific information to the model.
In addition, other models can be added to the base-
line by using different Deep Learning architectures or
different word embedding models.
Finally, we plan to apply MuDEC for classifica-
tion of other provisions of legal opinions related to
consumer complaints, such as the value of the com-
pensation for material damage or the legal fees due
by the defeated party. This would require a more ro-
bust annotation process, which considers all relevant
features, and expands the number of instances in the
current annotated dataset. Going one step further, we
also plan to test the model in legal domains other than
consumer complaints.
ACKNOWLEDGEMENTS
This work was partly funded by FAPERJ under
grant E-26/200.832/2021, by CAPES under grants
88881.310592-2018/01, 88887.626833/2021-00, and
by CNPq under grant 302303/2017-0. The au-
thors wish to thank the Tecgraf Institute, PUC-Rio
and the Court of Justice of the State of Rio de
Janeiro (TJERJ) for supporting this research, in-
cluding the following: LABLEXRIO (N
´
ucleo de
Inovac¸
˜
ao do Poder Judici
´
ario), NUPEMASC (N
´
ucleo
de Pesquisa em M
´
etodos Alternativos de Soluc¸
˜
ao
de Conflitos), CI/TJRJ (Centro de Intelig
ˆ
encia do
TJERJ) and DGTEC (Diretoria-Geral de Tecnologia
da Informac¸
˜
ao e Comunicac¸
˜
ao de Dados do TJERJ).
REFERENCES
Abdi, H. and Williams, L. J. (2010). Principal component
analysis. Wiley interdisciplinary reviews: computa-
tional statistics, 2(4):433–459.
Arora, S., Liang, Y., and Ma, T. (2017). A simple but tough-
to-beat baseline for sentence embeddings. In Interna-
tional conference on learning representations.
Chawla, N. V., Bowyer, K. W., Hall, L. O., and Kegelmeyer,
W. P. (2002). Smote: synthetic minority over-
sampling technique. Journal of artificial intelligence
research, 16:321–357.
de Araujo, P. H. L., de Campos, T. E., Braz, F. A., and
da Silva, N. C. (2020). Victor: a dataset for brazil-
ian legal documents classification. In Proceedings of
The 12th Language Resources and Evaluation Con-
ference, pages 1449–1458.
Fernandes, W. P. D., Frajhof, I. Z., Rodrigues, A. M. B.,
Barbosa, S. D. J., Konder, C. N., Nasser, R. B., de Car-
valho, G. R., Lopes, H. C. V., et al. (2022). Extracting
value from brazilian court decisions. Information Sys-
tems, 106:101965.
Fern
´
andez, A., Garcia, S., Herrera, F., and Chawla, N. V.
(2018). Smote for learning from imbalanced data:
progress and challenges, marking the 15-year an-
niversary. Journal of artificial intelligence research,
61:863–905.
Hartmann, N., Fonseca, E., Shulby, C., Treviso, M., Ro-
drigues, J., and Aluisio, S. (2017). Portuguese word
embeddings: Evaluating on word analogies and natu-
ral language tasks. arXiv preprint arXiv:1708.06025.
Kim, J.-Y. and Cho, S.-B. (2019). Evolutionary optimiza-
tion of hyperparameters in deep learning models. In
2019 IEEE Congress on Evolutionary Computation
(CEC), pages 831–837. IEEE.
Kowsari, K., Jafari Meimandi, K., Heidarysafa, M., Mendu,
S., Barnes, L., and Brown, D. (2019). Text classifica-
tion algorithms: A survey. Information, 10(4):150.
Le, Q. and Mikolov, T. (2014). Distributed representations
of sentences and documents. In International confer-
ence on machine learning, pages 1188–1196. PMLR.
Luz de Araujo, P. H., de Campos, T. E., de Oliveira, R.
R. R., Stauffer, M., Couto, S., and Bermejo, P. (2018).
LeNER-Br: a dataset for named entity recognition in
Brazilian legal text. In International Conference on
the Computational Processing of Portuguese (PRO-
POR), Lecture Notes on Computer Science (LNCS),
pages 313–323, Canela, RS, Brazil. Springer.
Menardi, G. and Torelli, N. (2014). Training and assessing
classification rules with imbalanced data. Data mining
and knowledge discovery, 28(1):92–122.
Mikolov, T., Sutskever, I., Chen, K., Corrado, G. S., and
Dean, J. (2013). Distributed representations of words
and phrases and their compositionality. In Advances in
neural information processing systems, pages 3111–
3119.
Minaee, S., Kalchbrenner, N., Cambria, E., Nikzad, N.,
Chenaghlu, M., and Gao, J. (2021). Deep learning–
based text classification: A comprehensive review.
ACM Computing Surveys (CSUR), 54(3):1–40.
Pennington, J., Socher, R., and Manning, C. D. (2014).
Glove: Global vectors for word representation. In
Proceedings of the 2014 conference on empirical
methods in natural language processing (EMNLP),
pages 1532–1543.
Salton, G. and Buckley, C. (1988). Term-weighting ap-
proaches in automatic text retrieval. Information pro-
cessing & management, 24(5):513–523.
Snoek, J., Larochelle, H., and Adams, R. P. (2012). Practi-
cal bayesian optimization of machine learning algo-
rithms. Advances in neural information processing
systems, 25.
Vapnik, V. (2006). Estimation of dependences based on em-
pirical data. Springer Science & Business Media.
Wei, F., Qin, H., Ye, S., and Zhao, H. (2018). Empirical
study of deep learning for text classification in legal
document review. In 2018 IEEE International Con-
ference on Big Data (Big Data), pages 3317–3320.
IEEE.
Zhou, C., Sun, C., Liu, Z., and Lau, F. (2015). A c-lstm
neural network for text classification. arXiv preprint
arXiv:1511.08630.
Text Classification in the Brazilian Legal Domain
363
