
Machine Learning Performance on Predicting Banking Term Deposit
Nguyen Minh Tuan
a
Department of Mathematics, Faculty of Applied Science,
King Mongkut’s University of Technology North Bangkok, Thailand
Keywords:
Machine, Prediction, Deep Machine Learning, Banking, Term Deposit.
Abstract:
With the expansion of epidemic diseases and after the crises of the economy in the world, choosing finan-
cial deposits for many purposes is very helpful. To identify a customer whether deposit or not, based on the
information given to analyze and predict, it is becoming increasingly difficult for banks to identify whether
customer that is right for them. Many banks will be reconfigured beyond recognition to attract customers,
while others are facing a shortage drawing customers to maintain the business as a corollary of advances in
particular. To serve customers with the information needed to select a suitable deposit in such a rapidly evolv-
ing and competitive arena requires more than merely following one’s passion. We assert such information may
be derived by analyzing some descriptions using deep neural network models, a novel approach to identifying
the descriptions about age, job, marital, education, default, balance, housing, loan, contact, day, month, du-
ration, campaigns, pdays, previous, outcome, deposit (y) in choosing an appropriate deposit customer. There
have been some researchers written about this prediction but they just focused on algorithms models instead
of concentrating on deep machine learning. In this paper, we will muster up algorithms using the models on
deep machine learning with Long-Short Term Memory (LSTM), Gated Recurrent Unit (GRU), Bidirectional
Long-Short Term Memory (BiLSTM), Bidirectional Gated Recurrent Unit (BiGRU), and Simple Recurrent
Neuron Network (SimpleRNN). The result will suggest suitable customers based on the information given.
The results showed that Gated Recurrent Unit (GRU) reaches the best accuracy with 90.08% at epoch 50
th
,
and the following is the Bidirectional Long-Short Term Memory (BiLSTM) model with 90.05% at epoch 50
th
.
The results will be helpful for the banks to confirm whether the customers could deposit or not.
1 INTRODUCTION
The crisis of the economic and epidemic disease
could lead people to bankrupt and connect to the bank
for finance. Given such variety, the challenge for
banks is how to choose a method corresponding to
their situational finance. Basing on the phone calls,
the banks want to be sure to confirm that a customer
whether making a term deposit at that time or not.
This is a financial campaign of the bank in main-
taining the development and existing policy for cus-
tomers. The banks usually call the client over one
time to confirm that they have subscribed to the bank-
ing deposit or not. This prediction will help the bank
to establish a new strategy for the patrons. In bank-
ing, the prediction needs to get the best accuracy to
propose a new strategy in business. Confirmation in
banking before proposing a package to customers is
very important to the bank. They could cost much
a
https://orcid.org/0000-0002-4035-1759
time and much money for customer investigation. Af-
ter that, they will classify the customers and estimate
the deposit of the customers. The suitable findings
will reduce the time and money for the bank in call-
ing and attracting customers.
In paper (Hung et al., 2019), they fully compared
the Spark MLlib and ML packages and they showed
that ML packages got the best accuracy in predict-
ing term deposit. To compare Spark MLlib and ML
packages they applied Random Forest and Gradient
Boosting and the result for Gradient Boosting accu-
racy approach to 86%. They gave a good result for
the banking prediction but they just got a compari-
son in PySpark Apache. They never tried to use deep
machine learning to make a comparison in predicting
customers.
In paper (Kurapati et al., 2018), they used ma-
chine learning to predict the defaulters based on the
customer’s information. In that paper, they used
the algorithms in Scikit-Learn for prediction and
compared the accuracy of algorithms before feature
Tuan, N.
Machine Learning Performance on Predicting Banking Term Deposit.
DOI: 10.5220/0011096600003179
In Proceedings of the 24th International Conference on Enterprise Information Systems (ICEIS 2022) - Volume 1, pages 267-272
ISBN: 978-989-758-569-2; ISSN: 2184-4992
Copyright
c
2022 by SCITEPRESS – Science and Technology Publications, Lda. All rights reserved
267
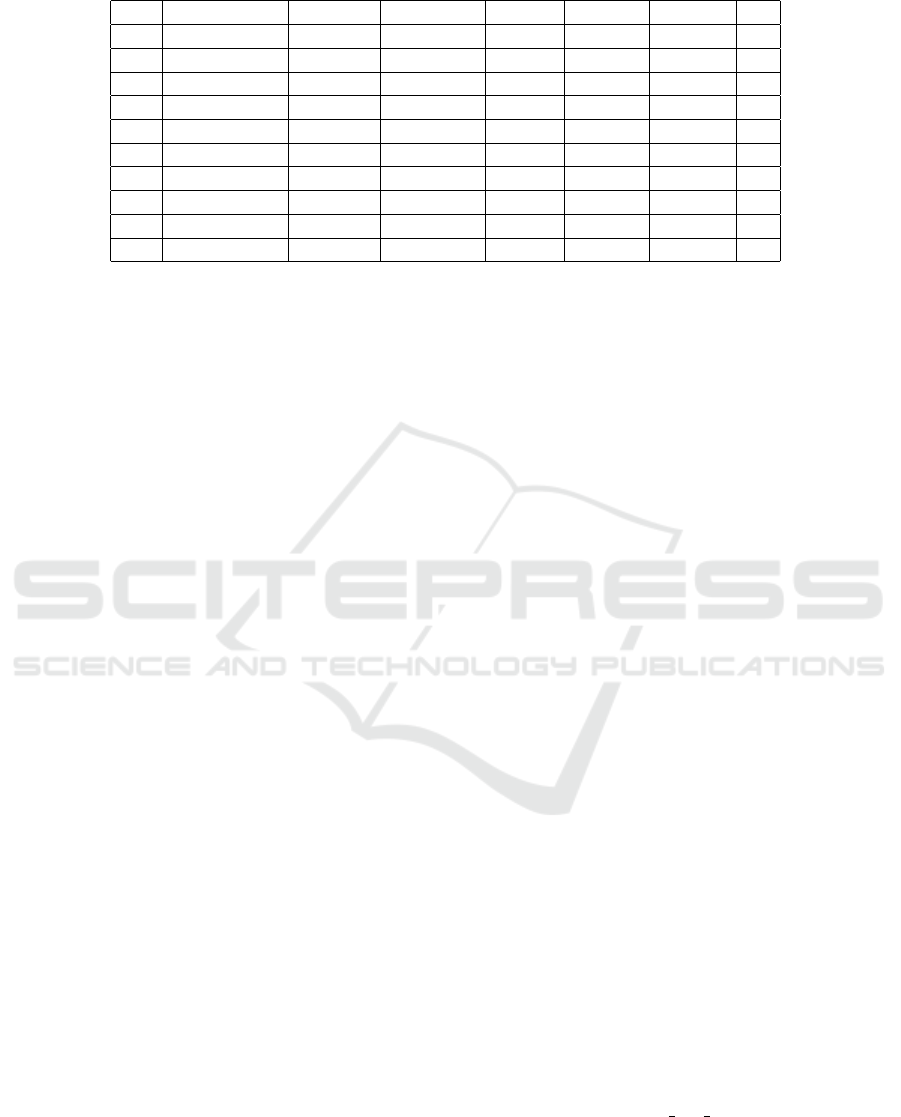
Table 1: Some example rows for data.
age job marital education default balance housing y
58 management married tertiary no 2143 yes no
44 technician single secondary no 29 yes no
33 entrepreneur married secondary no 2 yes no
47 blue-collar married unknown no 1506 yes no
33 unknown single unknown no 1 no no
35 management married tertiary no 231 yes no
28 management single tertiary no 447 yes no
42 entrepreneur divorced tertiary yes 2 yes no
58 retired married primary no 121 yes no
43 technician single secondary no 593 yes no
selection and after feature selection. Getting the
best algorithm is Random Forest to predict credit
defaulters compared to Decision Tree, Gradient
Boosting, and Extra Tree Classifier. They compared
the accuracy of prediction in defaulting payment
using machine learning techniques. In paper (Zhu
et al., 2019), they got a study for predicting loan de-
fault base on machine learning algorithms. The result
proving the performance of Random Forest showed
the best answer compared to the other algorithms
such as Decision Tree, SVM, and Logistic Regres-
sion. In the paper (Gupta et al., 2020), they applied
machine learning for predicting bank loan systems
by using Logistic Regression and Random Forest
and they did not compare to the other algorithms.
In the paper (Rahman and Kumar, 2020), they also
used KNN, SVM, Decision Tree, and Random Forest
to predict in machine learning based on customer
churn prediction. However, all of the papers have not
applied deep machine learning to predicting or got a
comparison for the models in deep machine learning.
In this paper, we got data (as shown in Fig 1) and
applied deep machine learning to take an accuracy
comparison using the LSTM model, GRU model,
and other algorithm models. We did try many
different algorithms and chose the best performance
for predicting a customer depositing in a bank. After
trying all the algorithms, we chose for performance
five best algorithms like Long-Short Term Memory
(LSTM), Gated Recurrent Unit (GRU), Bidirectional
Long-Short Term Memory (BiLSTM), Bidirectional
Gated Recurrent Unit (BiGRU) and Simple Re-
current Neuron Network (SimpleRNN). The main
purpose is to find a new comparison to generate
the customers’ information especially using deep
machine learning. Nowadays, banking is a useful
channel for relation in finance. They have the trend to
solve the financial work through the bank especially
in the economic crisis. Through Coivid-19, many
things have changed, the working is limited and they
tend to live at home and solve the problem online
where deposit banking is examined by customers.
In unprecedented circumstances, the banks have to
make phone calls to confirm the customers and have
some instructions to invite them to make a banking
term deposit. With machine learning, the banks could
solve the problems faster and decide the matters
rightly. This paper is aimed to confirm a customer
whether they could make a deposit or not using deep
machine learning. It is also convenient for the bank
to solve with an enormously large of customers in a
short time.
In this paper, we got input data from
the following website: https://www.kagg
le.com/vinicius150987/bank-full-machine-
learning/data. We also used the data set with
45,211 records and a total of 16 attributes. 1 shows
some examples extracted from data. The data consist
of numerical columns such as age, balance, day,
duration, campaign, pdays, and previous and other
columns are strings such as job, marital, default,
housing, loan, month, and deposit (y) which will be
turned into numeric by the StringIndexer. The term
deposit (y) is choosing for a label in predicting.
2 LITERATURE REVIEWS
Machine learning day by day has become a useful ap-
plication in most traditional stochastic methods espe-
cially in financial market forecasting as well as sup-
port vector machines (Ryll and Seidens, 2019; Ghani
et al., 2019). In this paper, we covered map all the
coulumns to convert the input numeric to string. Af-
ter that, we add all the attributes to the features. In the
next step, we apply train test split to slit the data. We
also try all the algorithms and choose some good algo-
rithms which are suitable to predict such as Gradient-
Boosted Trees, Random Forest, Decision Tree, Logis-
tic Regression, and deep learning machine is LSTM
ICEIS 2022 - 24th International Conference on Enterprise Information Systems
268
model, GRU model.
Long-Short Term Memory (LSTM) and Bidirectional
Long-Short Term Memory (BiLSTM) model is a kind
of recurrent neural network, is designed to memorize
information through using time (Junyu, 2020; Tuan
and Meesad, 2021). The structure of LSTM in every
section has repeated form, usually tanh gate, and has
been rearranged in effective layers. The target point
of the LSTM network is built input data by a sigmoid
function, called forget gate. LSTM has a function that
will omit or add the information to the system state by
the gate and sigmoid function (Fig 2).
Similar to LSTM, Gated Recurrent Unit (GRU) and
Bidirectional Gated Recurrent Unit (BiGRU) is a sup-
ply formed data transformed from input nodes to out-
put nodes (Verster et al., 2021; Tuan et al., 2021).
GRU consists of reset gate and updates gate. The
reset gate is to update the hidden state after the first
investigation and control how much the previous in-
formation we want to keep in. The update gate allows
control of how much the new state and information
copied from the old state. GRU (Kumar et al., 2020)
is a very important model for predicting the order in
the artificial neural network (Fig 3). GRU has reduced
the break-gradient information to LSTM.
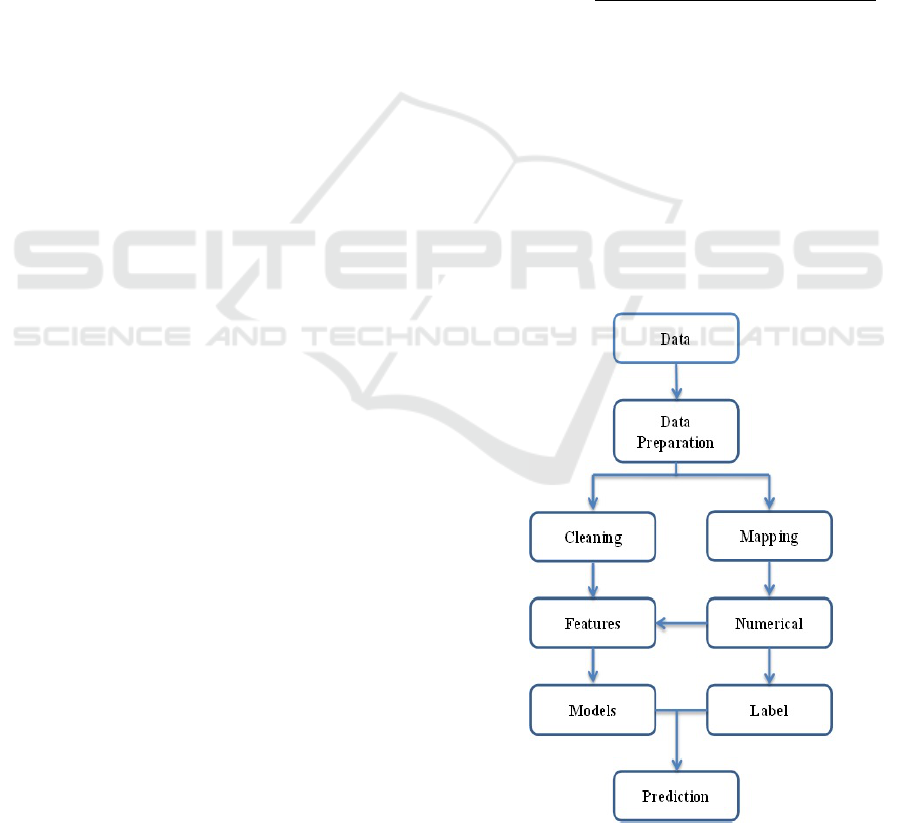
3 RESEARCH METHODOLOGY
In this paper, we approach the way to explore the
role of text preprocessing and feature representation
by using the available tools in Scikit-Learn library.
We use Python as a data analytics tool to implement
experiments. We extract randomly a dataset into
two parts in the ratio: 7:3 of total of 45,211 records.
All of them consist of four stages ( see Fig 1): Turn
all the string attributes into numerical attributes,
feature selection (adding all the numerical attributes
and categorical to features), predict banking term
deposit by using models, and using transformation
for the testing part with model and evaluation. In
the preprocessing, we clean the data with empty
records and apply ML packages to evaluate with four
differently detail preprocessing techniques:
+ Firstly, we divide the data into two kinds of
attributes. We put the string columns: age, balance,
day, duration, campaign, pdays, and previous into
the numerical columns. After that we apply map for
all the columns: job, material, education, default,
housing, loan, contact, month, poutcome, and put all
to the categorical column.
+ Secondly, we combine the numerical column and
categorical column to the new column “Features”
through the for the column deposit “y” to get the
label column. We transform the old data to new data
with selected columns.
+ Thirdly, we split data randomly into two parts:
training part (70%) and testing part (30%). We train
the model and execute the training in the pipeline and
predict the outcome.
+ Lastly, we evaluate the algorithms and get the best
algorithm with the greatest accuracy. After that, I
show the term deposit prediction.
To evaluate the model, we also use the accuracy, is
defined as the numbers of the ratio of numbers of
samples correctly classify by algorithms to the total
numbers of samples for a given data set, as shown as
the equation 1:
Accuracy =
T P
BT P
+ T N
BT P
T P
BT P
+ T N
BT P
+ FP
BT P
+ FN
BT P
(1)
Where T P
BT P
is true positive samples of banking term
deposit prediction, FP
BT P
is mistake positive sam-
ples of banking term deposit prediction, TN
BT P
is true
negative samples of banking term deposit prediction,
FN
BT P
is mistake negative samples of banking term
deposit prediction. With two deep learning machine
models: LSTM and GRU models, we combine all the
columns to features columns except the target y (de-
posit or not). We turn the target to 1 and 0 for predic-
tion. In the preprocessing, we tokenize and fit the text
to the features column.
Figure 1: Steps for preprocessing dataset.
Machine Learning Performance on Predicting Banking Term Deposit
269
4 EXPRIMENTAL RESULTS
After processing the data, we apply machine learning
models and compare them. We choose the best algo-
rithm to apply prediction for the outcome. In Table 2,
we got predictions for accuracy using the testing part.
In the LSTM model, we consider the data as string
and split the data into two parts with the ratio of 7:3.
We built 4 layers consisting of Embedding, Spacial-
Dropout1D, LSTM, and Dense, the shape for input
and output is (64;5) with 49,669 parameters. In the
GRU model, we applied the same structure to LSTM
and built 4 layers consisting of Embedding, Spacial-
Dropout1D, GRU, and Dense, the shape for input and
output is (64;5) with 41,605 parameters.
In the BiLSTM model, we apply the same method and
the same ratio in PySpark. We built 4 layers consist-
ing of Embedding, SpacialDropout1D, LSTM, and
Dense, the shape for input and output is (64;5) with
83,013 parameters. In the BiGRU model, we built 4
layers consisting of Embedding, SpacialDropout1D,
GRU, and Dense, the shape for input and output is
(64;5) with 66,885 parameters. In the BiGRU model,
we built 4 layers consisting of Embedding, Spacial-
Dropout1D, GRU, and Dense, the shape for input and
output is (64;5) with 24,901 parameters. In this exper-
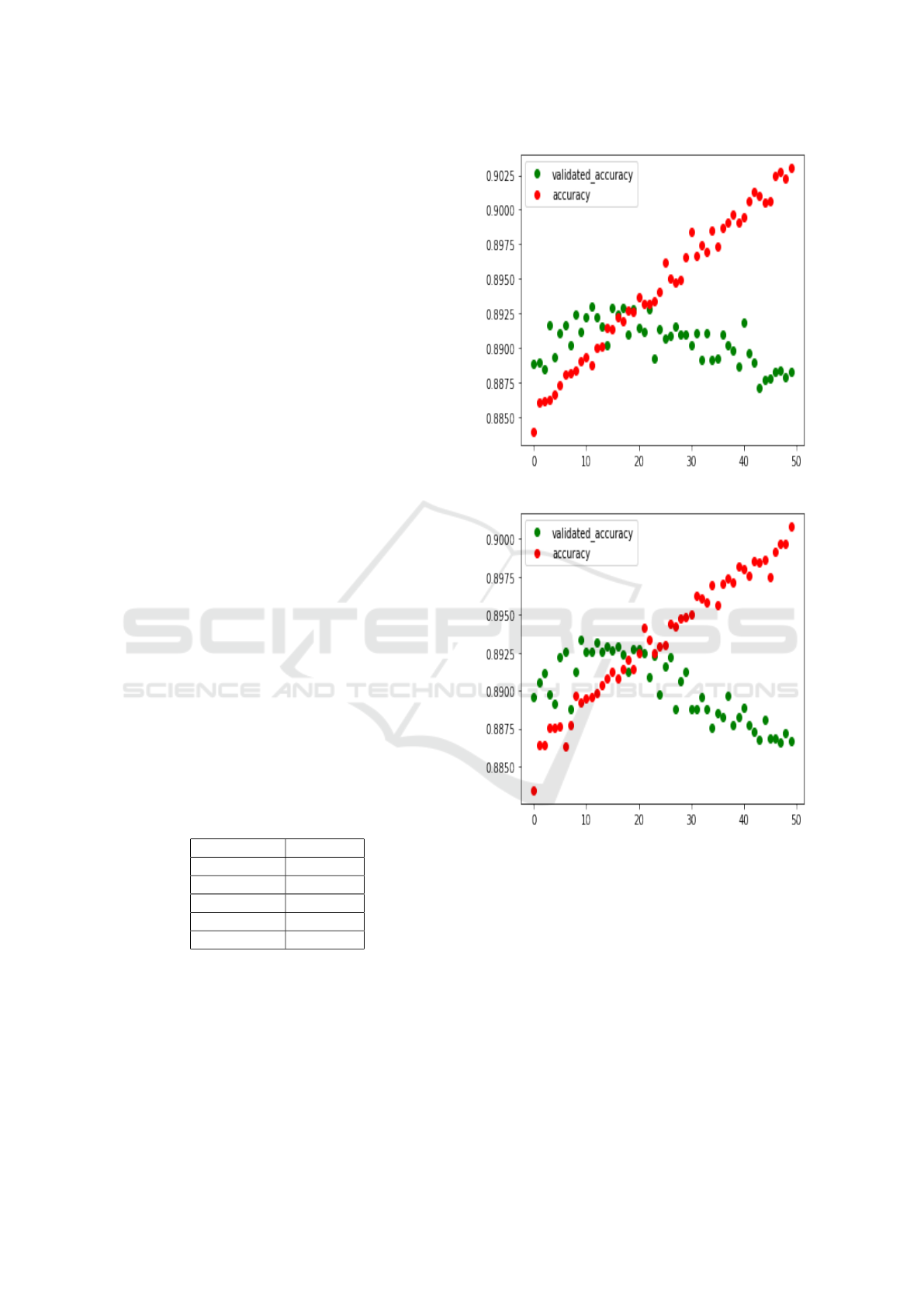
iment, the GRU model showed the best performance,
reaching the accuracy of 0.908 with 48s at the first
50th epoch, and could get better when repeating more
times (Shown in Fig 3). The BiLSTM model comes
alongside 0.905 with 52s at the 50th epoch (Fig 4).
The LSTM get close to 0.903 (Fig 2) and the follow-
ing is BiGRU (Fig 5) and SimpleRNN (Fig 6) respec-
tively reaching 0.901 and 0.892.
Table 3 shows the summary of predictive number
Table 2: Five best results in deep machine learning using
Scikit-Learn library.
Models Accuracy
BiLSTM 0.905
BiGRU 0.901
SimpleRNN 0.892
LSTM 0.903
GRU 0.908
values, the first label is 1 and prediction 1 are cor-
responding with true prediction numbers; the second
label 0 and prediction 1 are corresponding with false
prediction numbers; The third label 1 and prediction 0
are corresponding with false prediction numbers; the
fourth label 0 and prediction 0 are corresponding with
true prediction numbers.
Compared to the algorithms’ training in ScikitLearn
with the same data, we tried the algorithms and
Figure 2: LSTM prediction.
Figure 3: GRU prediction.
choose the five best models with accuracy as shown
in Table 2. We could see that with the same method,
the same models and algorithms but we get the best
answers in PySpark library than in Scikit-learn library
(usually online in Kaggle.com).
5 CONCLUSIONS AND FUTURE
WORK
The development of technology has led to many
things to solve in life especially in finance. They
usually have a tendency to get benefits at home, so
ICEIS 2022 - 24th International Conference on Enterprise Information Systems
270
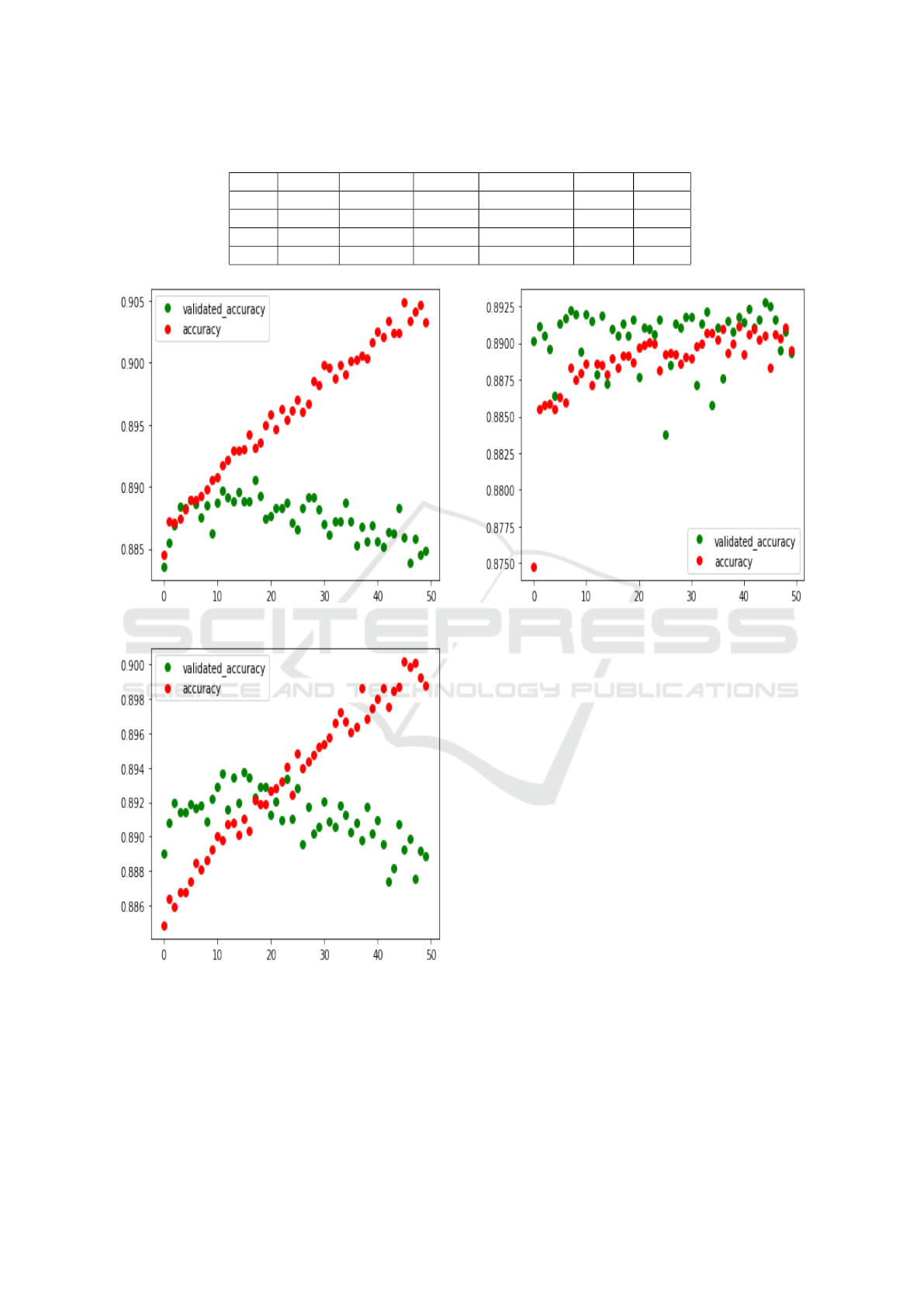
Table 3: Counting prediction values summary.
label predict BiLSTM BiGRU SimpleRNN LSTM GRU
1 1 390 347 586 346 368
0 1 209 260 381 418 446
1 0 1156 1199 960 1179 1151
0 0 11740 11689 11568 11621 15824
Figure 4: BiLSTM prediction.
Figure 5: BiGRU prediction.
investment by making a banking term deposit is one
of the channels to do this (Viswanathana et al., 2020;
Prasetyo et al., 2021). So, the banks need to have a
plan for calling the potential customers. To do this,
they must have a method for predicting whether cus-
tomers could have tended to make a profit by banking
Figure 6: RNN prediction.
term deposit. In this paper, the comparison is a use-
ful method to know more clearly about the nature of
the problems. Machine Learning algorithms are ap-
plied to all the matters of the jobs especially in some-
thing changeable every time and every day (N.dikum,
2020; Zhong and Enke, 2019; Ren et al., 2021). In
this paper, we have summarized the ease of using al-
gorithms in machine learning in machine learning and
Scikit-learn library and proposed the best models in
deep machine learning such as BiLSTM model and
GRU model. The results showed the best prediction in
banking term deposit customers which is GRU mod-
els with an accuracy of 90.8%. The result is one of
the methods for banks to confirm the target customers
and for expanded research in the future.
REFERENCES
Ghani, M. U., Awais, M., and Muzammul, M. (2019). Stock
market prediction using machine learning (ml) algo-
rithms. In Advances in Distributed Computing and
Artificial Intelligence Journal.
Gupta, A., Pant, V., Kumar, S., and Bansal, P. K. (2020).
Bank loan prediction system using machine learning.
In International Conference on System Modeling and
Advancement in Research Trends.
Machine Learning Performance on Predicting Banking Term Deposit
271

Hung, P. D., Hanh, T. D., and Tung, T. D. (2019). Term
deposit subscription prediction using spark mllib and
ml packages. In 5th International Conference on E-
Business and Applications.
Junyu, H. (2020). Prediction of financial crisis based on
machine learning. In The 4th International Confer-
ence on Business and Information Management.
Kumar, V. S., Bhardwajb, B., Guptac, V., Kumarc, R., and
Mathurc, A. (2020). Gated recurrent unit (gru) based
short term forecasting for wind energy estimation. In
International Conference on Power, Energy, Control
and Transmission Systems.
Kurapati, N., Kumari, P., and Bhansali (2018). Predicting
the defaulters using machine learning techniques. In
Research Paper.
N.dikum, P. (2020). Machine learning algo-
rithms for financial asset price forcasting. In
https://doi.org/10.1093/rfs/hhaa009.
Prasetyo, I., Utar, W., Susanto, H., Rusdiyanto, and Hi-
dayat, W. (2021). Comparative analysis of banking
financial performance: Evidence from indonesia. In
Ilkogretim Online - Elementary Education Online.
Rahman, M. and Kumar, V. (2020). Machine learning based
customer churn prediction in banking. In Fourth Inter-
national Conference on Electronics, Communication
and Aerospace Technology.
Ren, L., Dong, J., Wang, X., Meng, Z., Zhao, L., and Deen,
M. J. (2021). A data-driven auto-cnn-lstm prediction
model for lithium-ion battery remaining useful life. In
IEEE Transactions Industrial Informatics.
Ryll, L. and Seidens, S. (2019). Evaluating the perfor-
mance of machine learning algorithms in financial
market forecasting: A comprehensive survey. In
http://arxiv.org.
Tuan, N. M. and Meesad, P. (2021). A study of pre-
dicting the sincerity of a question asked using ma-
chine learning. In International Conference on Nat-
ural Language Processing and Information Retrieval,
https://doi.org/10.1145/3508230.3508258.
Tuan, N. M., P., M., and H.C, N. H. (2021). English-
vietnamese machine translation using deep learning.
In Recent Advances in Information and Communica-
tion Technology IC2IT.
Verster, T., Harcharan, S., Bezuidenhout, L., and Bae-
sens, B. (2021). Predicting take-up of home
loan offers using tree based ensemble models: A
south african case study. In Research Article at
https://doi.org/10.17159/sajs.2021/7607.
Viswanathana, P. K., Srinivasan, S., and Hariharan, N.
(2020). Predicting financial health of banks for in-
vestor guidance using machine learning algorithms. In
Research Article.
Zhong, X. and Enke, D. (2019). Predicting the daily re-
turn direction of the stock market using hybrid ma-
chine learning agorithms. In Finacial Innovation.
Zhu, L., Qiu, D., Ergu, D., and Liu, C. Y. K. (2019). A
study on predicting loan default base on random forest
algorithm. In International conference on Information
Technology and Quantitative Management.
ICEIS 2022 - 24th International Conference on Enterprise Information Systems
272
