
Detecting Bots in Social-networks using Node and Structural
Embeddings
Ashkan Dehghan
1
, Kinga Siuta
1,2
, Agata Skorupka
1,2
, Akshat Dubey
1
, Andrei Betlen
3
, David Miller
3
,
Wei Xu
1
, Bogumił Kami
´
nski
2 a
and Paweł Prałat
1 b
1
Ryerson University, Toronto, ON, Canada
2
SGH Warsaw School of Economics, Warsaw, Poland
3
Patagona Technologies, Pickering, ON, Canada
Keywords:
Structural and Node Embeddings, Detecting Bots, Social Networks.
Abstract:
Users on social networks such as Twitter interact with and are influenced by each other without much knowl-
edge of the identity behind each user. This anonymity has created a perfect environment for bot and hostile
accounts to influence the network by mimicking real-user behaviour. To combat this, research into designing
algorithms and datasets for identifying bot users has gained significant attention. In this work, we highlight
various techniques for classifying bots, focusing on the use of node and structural embedding algorithms. We
show that embeddings can be used as unsupervised techniques for building features with predictive power
for identifying bots. By comparing features extracted from embeddings to other techniques such as NLP,
user profile and node-features, we demonstrate that embeddings can be used as unique source of predictive
information. Finally, we study the stability of features extracted using embeddings for tasks such as bot classi-
fication by artificially introducing noise in the network. Degradation of classification accuracy is comparable
to models trained on carefully designed node features, hinting at the stability of embeddings.
1 INTRODUCTION
Internet and social media impact all aspects of our
lives. We use them to read news, connect with friends
and family, share opinions, buy products, and enter-
tain us. It affects our beliefs, behaviour and so it
shapes our political, financial, health, and other im-
portant decisions. Unfortunately, as a result, social
networks created an information platform in which
automated accounts (including human-assisted bot
accounts and bot-assisted humans) can try to take ad-
vantage of the system for various opportunistic rea-
sons: trigger collective attention (Lehmann et al.,
2012; De Domenico and Altmann, 2020; Gonz
´
alez-
Bail
´
on and De Domenico, 2021), gain status (Cha
et al., 2010; Stella et al., 2019), monetize public atten-
tion (Carter, 2016), diffuse disinformation (Bail et al.,
2020; Freelon et al., 2020; Monti et al., 2019), or seed
discord (Woolley and Howard, 2018). It is known
that a large fraction of active Twitter users are bots
and they are responsible for much disinformation—
a
https://orcid.org/0000-0002-0678-282X
b
https://orcid.org/0000-0001-9176-8493
see, (Yang et al., 2019) for many examples of manip-
ulation of public opinion. Having said that, not all bot
accounts are designed to harm or take advantage of
other users. Some of them are legit and useful tools
such as chatbots that respond to common questions of
users, or knowbots that are designed to automatically
retrieve some useful information from the Internet.
On the other hand, human accounts may also spread
disinformation and be responsible for some other ma-
licious behaviour. Detecting bots and understanding
roles they play within the system falls into a common
machine learning task of node classification.
The main objective of this paper is to investigate
whether graph embeddings extract information from
the associated network that can be successfully used
for node classification task. In our experiments, we
concentrate on Twitter data and the task of identi-
fying bot accounts but our questions (and answers)
are much broader and so potentially more influential.
They are applicable to all kinds of networks and data
sets that are naturally represented as graphs which, of
course, includes social media platforms such as Twit-
ter. Moreover, they are applicable to a much wider
class of machine learning tasks: node classification
50
Dehghan, A., Siuta, K., Skorupka, A., Dubey, A., Betlen, A., Miller, D., Xu, W., Kami
´
nski, B. and Prałat, P.
Detecting Bots in Social-networks using Node and Structural Embeddings.
DOI: 10.5220/0011147300003269
In Proceedings of the 11th International Conference on Data Science, Technology and Applications (DATA 2022), pages 50-61
ISBN: 978-989-758-583-8; ISSN: 2184-285X
Copyright
c
2022 by SCITEPRESS – Science and Technology Publications, Lda. All rights reserved

algorithms train a model to learn in which class a
node of the graph belongs to. Bot detection is a spe-
cific example of this class of problems in which a
binary classification is performed (nodes are catego-
rized into bots and humans) (Antenore et al., 2022).
However, in general, multi-class classifications is also
often considered and needed. Other important appli-
cations of this nature include, for example, identifying
nodes associated with users that might be interested
in some specific product, or detecting hostile actors.
For this reason there is an increasing need for effec-
tive methods of analysis data represented as graphs.
For more details we direct the reader to a recent sur-
vey (Matwin et al., 2021) and a book (Kami
´
nski et al.,
2021).
There are many approaches that can be used to
perform node classification in graphs. Most tech-
niques attempt to detect bots at the account level by
processing many social media posts and analyzing
them using various NLP techniques with the goal to
extract some important and distinguishing features.
These features are usually complemented with user
metadata, friend metadata, content and language sen-
timent, as well as temporal features (Dong and Liu,
2018). In this paper, we will refer to these features
as NLP+P (NLP+Profile). These techniques are very
powerful but a supervised machine learning algorithm
is only as good as the data used for training. Unfor-
tunately, good quality datasets with the ground-truth
are rarely available. Additional challenge is that so-
cial bots evolve rapidly and so one needs to constantly
update datasets and evolve the set of features to keep
up with the other side. In particular, hot topics dis-
cussed on social media evolve rapidly; for example,
NLP features that were important for bot detection be-
fore presidential elections in some country might be-
come quickly outdated after the elections. Similarly,
results of NLP analysis cannot be easily transferred
from one language to another or across differ geo-
graphical regions or countries. As a result, a collab-
orated effort of many researchers and data scientists
is needed to maintain bot detection models. One suc-
cessful example is Botometer, bot detection tool de-
veloped at Indiana University using various labelled
datasets and 1,209 features (current, 3rd version of the
model) (Yang et al., 2019); see also (Sayyadiharikan-
deh et al., 2020) for a new supervised learning method
that trains classifiers specialized for each class of bots
and combines their decisions through the maximum
rule (ensemble approach). Botometer handles over a
quarter million requests every day! However, since
the bot score is intended to be used with English-
language accounts, what can one do with non-English
accounts? What if the content or metadata is not eas-
ily available? Finally, how about other node classifi-
cation tasks which cannot enjoy such powerful tools
such as Botometer?
An alternative approach is to use some features of
nodes that can be calculated exclusively using graph
data. The main advantage of this approach is that such
information is easier to obtain and is typically less
sensitive as it does not include the analysis of user
messages and metadata associated with them. More
importantly, it can be hypothesised that the signal is
more stable in time and graph space, that is, if some
topological structure of the network indicates that
some nodes are likely to be bots, then such signal is
likely to loose its predictive power slower than, for ex-
ample, discussion topics extracted from NLP features.
Typical features concentrate on local properties of
nodes such as node degree, various node centralities,
local clustering coefficient, etc. We will call features
derived using this approach as GF (Graph Features).
The idea behind is that bots need to use some strate-
gies to form an audience. They employ various algo-
rithms to gather followers and expand their own so-
cial circles such as following popular accounts and
ask to be followed back (Aiello et al., 2012), gener-
ating specific content around a given topic with the
hope to gain trust and catch attention (Freitas et al.,
2015), or even interacting with other users by engag-
ing in conversation (Hwang et al., 2012). These al-
gorithms create networks around the bots that should
be structurally and topologically distinguishable from
the ones around real human beings which, in turn, af-
fect the extracted graph features. The same rationale
applies to other applications of node classification.
The above approach, based on analysis of prede-
fined graph features, was proved to be useful in vari-
ous node classifications tasks but it has a few issues.
First of all, very often features of one node alone
are not enough to adequately classify this node. In-
deed, bots typically work in a coordinated way and
are not usually suspicious when considered individu-
ally. Hence, bot detection requires combining infor-
mation about multiple bots and analyzing them to-
gether (Chavoshi et al., 2016). This often is very
challenging, both conceptually as well as computa-
tionally, as it requires to consider at least a quadratic
number of pairs of nodes. As mentioned earlier,
graph features capture properties that are rather local
whereas some embedding algorithms aim to extract
more global and structural properties. Moreover, we
often do not have access to a complete network but
rather sample it using some sampling method. Un-
fortunately, the choice of a sampling algorithm may
substantially affect GF. Finally, the features that are
to be analyzed need to be predefined by the analyst.
Detecting Bots in Social-networks using Node and Structural Embeddings
51

Therefore, the result of this approach depends heavily
on skills, knowledge, or just sheer luck of the user.
In order to solve at least some of these problems,
we propose to utilize node embedding algorithms that
assign nodes of a graph to points in a low dimensional
space of real numbers. The goal of the embedding is
to decrease the dimension but, at the same time, to ex-
tract the most important features of nodes and ignore
noise. We will call features obtained based on this ap-
proach EMB. These algorithms have quickly became
an intensely researched topics in recent years; see, for
example, (Cai et al., 2018) or a recent book (Kami
´
nski
et al., 2021), and the list of potential applications
constantly increases. After reducing the dimension
via node embeddings, node classification can be done
more efficiently compared to extracting graph fea-
tures and using the original network to identify syn-
chronized behaviour. On the other hand, synchro-
nized behaviour should create similar network struc-
ture around the involved nodes and so should be cap-
tured by the embedding. Such group of nodes may
be then potentially extracted (even in an unsupervised
way) by some machine learning tools such as DB-
SCAN that are able to identify dense regions of the
embedded space. Some of embedding algorithms not
only capture local properties of graphs but also try to
pay attention to global structure and different roles the
nodes play within the network (Ribeiro et al., 2017;
Donnat et al., 2018) which might carry more predic-
tive power than local GF. Additional benefit of such
approach, in comparison to using GF, is that features
are identified automatically in an unsupervised way
by the algorithm, as opposed to having to identify
them manually by the analyst. Finally, embeddings
seem to be less sensitive to sampling techniques and
so they might be used as a foundation for more robust
classification algorithms.
In this paper we show the following:
• Profile features are predictive for identifying bots,
since they capture core social properties of the
ground-truth network, such as friends and follow-
ers count.
• NLP approaches are powerful but are data specific
and so cannot be generalized across time, regions
and languages. Predictive features of NLP change
over time and need to be constantly updated.
• EMB approaches provide an unsupervised way
of capturing statistically significant predictive fea-
tures.
• Features built using EMB techniques perform
equally well for classifying bots as compared with
carefully designed GF features.
• EMB techniques are as stable as features built us-
ing GF method, as the network is perturbed with
noise.
• EMB features contribute incremental predictive
power to bot classification when used in combi-
nation with GF features.
Finally, let us stress that despite the fact that these re-
sults are optimistic and show a potential of algorithms
based on graph embeddings, this is an early stage of
research in this direction. We finish the paper with a
discussion of future work that will deepen our under-
standing of the power (as well as potential issues) of
embeddings.
2 DATASETS
Developing and evaluating bot detection algorithms
relies on the availability of unbiased labeled datasets.
Although there are numerous datasets used for build-
ing and benchmarking bot detection algorithms, we
mainly focus on using two recently curated Twitter
datasets by Feng et al. (Feng et al., 2021) [TwiBot-
20] and Setlla et al. (Stella et al., 2019) [Italian Elec-
tion]. We recognize that labeled bot-datasets often
contain some level of bias, since the real ground-truth
is not readily available. In general, labels are identi-
fied by careful analysis of humans or by cleverly de-
signed algorithms. Throughout our study, we ensure
to stay aware of this fact and highlight any impact this
may have on our findings.
In the TwiBot-20 dataset, the authors focus on
building a comprehensive Twitter dataset composed
of semantic, property, and neighbourhood informa-
tion. Here, semantic is the Tweet text generated by
the user; property is the information related to user
profile such as number of followers and following,
and finally, neighbourhood is the network structure
of the user. We highlight the features used from
this dataset below. To capture a natural representa-
tion of the ground-truth Twittersphere, the authors im-
plemented a breadth-first search algorithm, to sample
and build the dataset. In this methodology, a user is
selected as the root of the tree and subsequent lay-
ers are built using the directed follow edges of each
user. This process is repeated up to layer 3, creating a
sample network with a selected user at its root (Feng
et al., 2021). The sampling algorithm used by the au-
thors builds a directed graph, where nodes are users
and edges are follow relationship. As highlighted by
Feng et al., this method of sampling does not focus on
any particular topic or pattern and should be a more
natural representation of the Twittersphere.
Raw features available from the TwiBot-20
dataset are listed and discussed in the journal version
DATA 2022 - 11th International Conference on Data Science, Technology and Applications
52

of this paper. Note that the values for these features
are a snapshot captured at the time of sampling. We
categorize each feature into three types: Profile, NLP
and Graph. The profile features are datapoints avail-
able through Twitter’s API, and highlight some prop-
erties of each user. As pointed out by Feng et al.,
the followers and following are randomly selected.
We use the raw user Tweets as the input to our NLP
feature engineering—details are provided in the jour-
nal version of this paper. Lastly, graph features are
build using the raw edge list provided in the TwiBot-
20 dataset. As mentioned before, an edge between
two nodes indicated a follow relationship between the
nodes. Although the original network provided by
Feng et al. is a directed graph, we convert it to undi-
rected graph for our analysis. Lastly, we note that the
profile feature verified is excluded from the bot clas-
sification process. This is done for two main reasons.
Firstly, most users accounts are not subject Twitter’s
verification process, where an account is confirmed to
be owned by the user it claims to be. This process
would inherently exclude bots from being verified.
Secondly, due to the nature of the verification pro-
cess, this feature could introduce bias for any classi-
fier, thus making the discovery other meaningful fea-
tures more difficult.
In the Italian Election dataset, Setlla et al. (Stella
et al., 2019) aim to investigate the online social inter-
actions during a 2018 Italian election and how it helps
to understand the political landscape. In their work,
the authors study relationship between real users and
bots, using the Twitter network. Unlike the TwiBot-
20 dataset, the authors build a sample of the social
network by focusing on tweets containing a list of po-
litical topics; such as ”#ItalyElection2018”, ”#voto”,
etc. The sampling technique used by Setlla et al. re-
sults in a network with a vastly different graph topol-
ogy than that created by Feng et al.. By sampling the
TwitterSphere based on topics, the authors created a
dataset in which nodes are users and edges represent
interactions between users, such as retweets or men-
tions. Although this makes it difficult to compare the
performance of bot detection algorithm between these
two datasets, having diversity in how a social network
is constructed helps us understand how bots manifest
themselves within a network. The Italian Election
dataset also contains labels indicating if a user is iden-
tified as a bot or not. As described by the authors,
the bot/not-bot labels were generated by using an a
classifier trained using Twitter user’s profile informa-
tion (Stella et al., 2019). Although the original dataset
used by Setlla et al. (Stella et al., 2019) contains user
profile and raw Tweet data, in this work we only have
access to the network data and thus we can only fo-
cus on features extracted from the underlying network
structure. Similar to the TwiBot-20 network, the Ital-
ian Election graph is directed, with edges pointing
from users who interact with other user’s content. We
also convert the Italian Election graph into an undi-
rected graph for the purpose of our study.
High-level statistics of both networks are provided
in the journal version of this paper. It is important
to note that we apply additional data cleansing and
filtering to provided dataset. For example, we run our
analysis on the largest component of each graph, and
convert both graphs into undirected networks.
3 PROFILE AND NLP FEATURES
In the journal version of this paper, we provide a de-
tailed analysis of features extracted from user’s pro-
file information and their tweets. We perform feature
engineering, specially on the raw tweets using vari-
ous NLP techniques. Since we only have profile and
tweet data from the Twibot-20, our analysis is cen-
tered around this dataset.
To maximize their impact on a social network,
bots aim to mimic real-user behaviour. To this end,
bots aim to create accounts and content that seem nat-
ural, such that it was generated by a real user. An ex-
ample of such actions could include following other
users, tweeting about relevant topics and engaging in
conversations. Despite their effort, bots often leave
behind signs that allow us to distinguish them from
non-bots. Having said that, bots are constantly get-
ting more clever. We provide a strong evidence that
NLP approach cannot be easily generalized and might
require constant re-training.
As one would expect, the way tweets are written
seems to be different linguistically between bots and
non-bots. However, with recent advances in Trans-
former models, computer generated text is becom-
ing evermore human like. The current state-of-the-
art is the OpenAI’s GPT-3 (Brown et al., 2020), a
generative model for NLP tasks with 175 billion pa-
rameters! GPT-3 has been demonstrated to be effec-
tive on a variety of few-shot tasks: due to its exten-
sive pre-training and size, it is able to learn rapidly
from very few training examples. It generates texts
that are nearly indistinguishable from human-written
texts: Humans correctly distinguished GPT-3 gener-
ated texts from real human texts approximately 52%
of the time, which is not significantly higher than a
random chance (Brown et al., 2020). For more details
on GPT-3 and other related topics we direct the reader
to, for example, a recent survey (Matwin et al., 2021).
Detecting Bots in Social-networks using Node and Structural Embeddings
53

4 GRAPH DERIVED FEATURES
Another potentially independent source for extract-
ing features is rooted in the way users/bots interact
with others in the network. One can capture this in-
formation by analyzing various graph properties de-
rived from the underlying social-network. This can
be done in two ways. One, by carefully designing
statistical features of the nodes. Second, using unsu-
pervised methods to learn node and structural repre-
sentations of the nodes. In this section, we provide
a detailed analysis of node feature engineering in ad-
dition to features extracted using various embedding
techniques.
4.1 Node Features
In this section, we build node features derived from
the underlying network structure using both TwiBot-
20 and Italian Election datasets. For extracting fea-
tures we use NetworkX as well as igraph python
packages depending on the efficiently of the corre-
sponding algorithms. Here is the list of extracted
node-features that were computed for all nodes. For
detailed definition we direct the reader to, for exam-
ple, (Kami
´
nski et al., 2021) or any other textbook on
network science.
• degree centrality - degree (the number of edges
the vertex has)
• strength - minimum ratio of edges re-
moved/components created during graph de-
composition process
• eigen centrality - eigenvector centrality, a mea-
sure of the importance of the vertex (using relative
scores)
• closeness - closeness centrality, a measure of the
importance of the vertex calculated using the sum
of the length of the shortest path between the ver-
tex and other vertices
• harmonic centrality - harmonic centrality (an-
other variant of closeness centrality, calculated
similarly)
• betweenness - betweenness centrality, a measure
of the importance of the vertex calculated using
number of shortest paths that pass through the
node
• authority - authority score, sum of the scaled hub
values that have edge to the given node
• hub score - hub score, sum of the scaled authority
values of the nodes it has edge to
• constraint - Burt’s constraint, an index that mea-
sures the extent to which a person’s contacts are
redundant
• coreness - coreness (unique value of k such that a
node belongs to the k-core but not to the (k + 1)-
core)
• eccentricity - eccentricity (the maximum distance
from a given node to other nodes)
• pagerank - another way of measuring node im-
portance - invented by Google Search to rank web
pages in Google search engine output
In addition to the above list of features, we compute
average, standard deviation, minimum and maximum
of every feature for the neighbouring nodes of each
vertex. A full list of these features is given in the jour-
nal version of the paper.
As we highlighted in section 2, there are major
differences in how the TwiBot-20 and Italian Elec-
tion datasets were constructed. Firstly, the underly-
ing network constructed in the TwiBot-20 captures
follower-following relationship, while the network in
the Italian Election dataset represents interactions
between users. Secondly, the sampling technique
used in the TwiBot-20 dataset results in much more
uniform graph topology since at each sampling layer a
fix number of nodes (followers) were sampled. This is
in contrast to the Italian Election dataset, were nodes
were more randomly sampled. The difference in the
network topology between these two datasets is re-
flected in the values captured using the node-features
(a full analysis of these differences is presented in
journal version of the paper). This is indeed an impor-
tant observation, since one could extract more mean-
ingful node-features by resampling the same underly-
ing graph using different techniques.
The features whose calculation did not involve
neighbours indicate only slight differences between
bots and non-bots, both in terms of feature count and
magnitude of discrepancies.
Discrepancies between bot and non-bots groups
are more visible on the distributions of features in-
volving particular nodes’ neighbours’ during calcula-
tion. Similarly to the previous group of characteris-
tics, differences are more visible on the Italian Elec-
tion data and again, values in this dataset seem to have
lower variance or variance among groups. In particu-
lar, values for bots’ features seem to have even lower
standard deviation, which may be an indicator of the
fact that bots constitute a homogenous group. Nev-
ertheless, as different conclusions may be drawn on
the basis of TwiBot-20 dataset, so this observation
may be attributed to different sampling or annotating
method.
DATA 2022 - 11th International Conference on Data Science, Technology and Applications
54

The fact that node features constructed on the ba-
sis of data about vertices’ neighbours may help in ex-
plaining being bot versus non-bot (at least more than
pure node features) indicates the purposefulness of
node embeddings usage. However, as this assump-
tion is based solely on graphical analysis, one may be
interested in modelling the relationship of node fea-
tures and “being a bot”. This is done in the following
sections.
4.2 Node and Structural Embedding
There are over 100 algorithms proposed in the liter-
ature for node and structural embeddings which are
based on various approaches such as random walks,
linear algebra, and deep learning (Goyal and Fer-
rara, 2018; Kami
´
nski et al., 2021). Moreover, many
of these algorithms have various parameters that can
be carefully tuned to generate embeddings in some
multidimensional spaces, possibly in different dimen-
sions. In this paper, we typically set all parameters
but the dimension to the default values recommended
by their authors. Once parameters are fixed, the algo-
rithms learn the embedding in an unsupervised way.
Having said that, some algorithms are randomized
and so the outcome might vary. For our experiments,
we selected 6 popular algorithms that span different
families and includes both node as well as structural
embeddings.
The first two algorithms, Deep Walk (Perozzi
et al., 2014) and Node2Vec (Grover and Leskovec,
2016), are based on random walks performed on the
graph. This approach was successfully used in NLP;
for example the Word2Vec algorithm (Mikolov et al.,
2013) is based on the assumption that “words are
known by the company they keep”. For a given word,
embedding is achieved by looking at words appear-
ing close to each other as defined by context win-
dows (groups of consecutive words). For graphs, the
nodes play the role of words and “sentences” are con-
structed via random walks. The exact procedure how
one performs such random walks differs for the two
algorithms we selected.
In the Deep Walk algorithm, the family of walks
is sampled by performing random walks on graph G,
typically between 32 and 64 per node, and for some
fixed length. The walks are then used as sentences.
For each node v
i
, the algorithm tries to find an embed-
ding e
i
of v
i
that maximizes the approximated likeli-
hood of observing the nodes in its context windows
obtained from generated walks, assuming indepen-
dence of observations.
In node2vec, biased random walks are defined via
two main parameters. The return parameter (p) con-
trols the likelihood of immediately revisiting a node
in the random walk. Setting it to a high value ensures
that we are less likely to sample an already-visited
node in the following two steps. The in-out parame-
ter (q) allows the search to differentiate between in-
ward and outward nodes so we can smoothly inter-
polate between breadth-first-search (BFS) and depth-
first search (DFS) exploration.
The above algorithms primarily capture proximity
among the nodes, nodes that are close to one another
in the network are embedded together. But proximity
among the nodes does not always imply similarity, as
in the specific application we consider in this paper,
bot detection. A role the nodes play within the net-
work depends more on the structure of the network
around them more than the distance between them.
(See (Rossi and Ahmed, 2014) for a survey on roles.)
The next four algorithms aim to create embeddings
that capture structural properties of the network.
The first algorithm from this family,
Role2Vec (Ahmed et al., 2019), generalizes the
above techniques based on traditional random walks.
To capture whether two nodes have the same role
within the network, the notion of attributed random
walks is introduced which is not tided to node iden-
tity but is instead using a function that maps a node
attribute vector to a role. As a result, the algorithm
learns associations among subsets of nodes (that is,
roles) instead of properties of individual nodes.
RolX (Henderson et al., 2012) is another approach
to explicitly identify the role of nodes using exclu-
sively the network structure. This algorithm is based
on enumerating various structural features for nodes
in an unsupervised way, and finding the most suited
basis vector for this joint feature space. Then, the al-
gorithm assigns every node with a distribution over
the identified roles (basis), allowing for mixed mem-
bership across the roles.
The next algorithm, Struc2Vec (Ribeiro et al.,
2017) uses a hierarchy to measure node similarity at
different scales. As a result, it constructs a multilayer
graph to encode structural similarities and generate
structural context for nodes. This hierarchical view
is useful as it provides a sequence of more restricted
notions of what it means to be structurally similar. At
the bottom of the hierarchy, similarity between nodes
depend exclusively on their degrees whereas at the top
of the hierarchy similarity depends on the entire net-
work.
The last algorithm we tested, GraphWave (Donnat
et al., 2018) uses techniques from graph signal pro-
cessing. It learns structural embeddings by propagat-
ing a unit of energy from a given node and character-
izes its neighbouring topology based on the response
Detecting Bots in Social-networks using Node and Structural Embeddings
55

of the network to this probe. The runtime of this al-
gorithms scales linearly with the number of edges.
As mentioned earlier, we fix most of the hyper-
paramters of each algorithm to their default value, and
only adjust the embedding dimension. Of course, it is
important to note that it is possible to optimize the
outcome of each algorithm by searching for the ideal
set of parameters for the task at hand, however our
goal is not to optimize for the best metrics, but rather
learn whether embeddings can help us in identifying
bots in a social network.
5 BOT CLASSIFICATION
Thus far, we have focused on engineering and ana-
lyzing features built using user-profile, NLP, node-
features and embeddings. In effort to understand the
predictability of these features in identifying bot ac-
counts, we train and test various classification models
using the TiwBot-20 and Italian Election datasets.
Since the underlying data for these datasets are dif-
ferent, we divide our analysis into two section ac-
cordingly, focusing on each dataset separately. In
both cases, datasets are sampled such that bot/non-bot
classes are balanced (50/50). Furthermore, we use a
80/20 split for the train/test datasets. A 5-fold cross-
validation process is then used to arrive the best per-
forming model. All metrics are then computed using
the test-set.
5.1 Bot Detection using TwiBot-20
Dataset
In this section, we use NLP+P, GF and EMB features
to build a bot classification model. Our goal is not
to optimize for the best performing model, but rather
understand the predictive power of each feature-set.
We build five models using various combinations of
feature-sets. A summary of the performance of each
model is highlighted in Table 1. As shown, the best
performing model (based on accuracy) is the one
trained on all features combined, achieving an accu-
racy of 81.76%. Furthermore, we note that models
trained on EMB perform slightly better than those
trained on GF alone. This enforces the fact that unsu-
pervised embedding algorithms have the potential to
learn complex and meaningful node features. More
importantly, a model built on a combined GF+EMB
performs better than GF and EMB separately, hinting
that embedding features capture incremental predic-
tive information about the nodes. Lastly, we note that
models built using features extracted from the under-
lying network (GF and EMB) suffer from the uni-
form topology of the TwiBot-20 dataset, as described
previously. A different sampling technique could po-
tentially result in a boost in the predictive power of
features built using the network structure.
Next, we use feature importance analysis to ex-
plore the contribution of various features in the GF
+ NLP+P feature-sets to the performance of mod-
els. Since the embedding algorithms learn continu-
ous representation of nodes in an unsupervised way,
it is not easy to reverse engineer what each embed-
ding dimension represents. Starting with feature im-
portance using GF feature-set, we find that top two
most predictive features for the TwiBot-20 datasets
are degree centrality and pagerank. Given the high
overlap in the performance of models built using GF
and EMB datasets, one could postulate that embed-
ding algorithms learn some form of centrality mea-
sure about the nodes.
Next, we apply similar feature importance analy-
sis to the NLP+P feature-sets. According to top 20
variable importances the set of the top three predic-
tor features are two original Twitter API variables,
f ollowers count, listed count, and the percentage of
English tweets, perc en extracted in the course of this
study. This feature’s importance has manifested in the
basic EDA too. Further behind, we can see three vari-
ables with a similar importance, i.e, f riends count,
links per tweet and av tweet len. Quite noticeable
impact was noted for user mentions per tweet as well
as for sentiment related features.
A complementary feature importance analysis can
be done using Shapley technique. It is confirmed that
the more followers users have, the least chance of
them being a bot. Also, even though bots are not
generally as followed on Twitter as bots are, the re-
lationship is opposite for Twitter friendships—the ex-
treme values for f riends count are generally associ-
ated with bots in the ML classifier as well. Another
significant distinction between bots and humans can
be found in listed count. Large number of public lists
that this user is a member of is associated with being
a human. The percentage of tweets written in English
is not as monotonously related to being a bot, but the
highest values are characteristic exclusively for bots.
These users also seem not to be keen on using geo-
graphical tagging when they’re posting (this was an
opt-in feature on Twitter). The links and mentions per
tweet tend to be higher for the identified bots, even
though the initial basic EDA could not detect this ten-
dency clearly for the links feature.
DATA 2022 - 11th International Conference on Data Science, Technology and Applications
56

Table 1: Performance measure for models trained using TwiBot-20 dataset.
Procedure Accuracy Precision Recall F1 MCC
NLP+P 0.8036 0.8059 0.8675 0.8356 0.5952
GF 0.6352 0.6357 0.8563 0.7297 0.2274
EMB 0.6481 0.6562 0.8153 0.7271 0.2594
GF+EMB 0.6620 0.6599 0.8507 0.7433 0.2905
NLP+P+GF+EMB 0.8176 0.8256 0.8657 0.8452 0.6246
5.2 Bot Detection using Italian-Election
Dataset
In this section, we build and analyze bot classification
models using the Italian Election dataset. As pointed
out earlier, we do not have user profile or tweet data
for the Italian-Election dataset, and thus all mod-
els are built using only the GF and EMB features.
As before, we train our models on balanced datasets
containing 50/50 proportion of bot and non-bot ex-
amples. Test, train split is kept consistent to 80/20
split. Furthermore, we keep the model architecture
and all hyperparameters the same for all runs, to keep
performance comparison consistent across all feature
sets. We measure a number of metrics when com-
paring the performance of each feature set, includ-
ing accuracy, recall, precision and Matthews correla-
tion coefficient (MCC). Since some embeddings such
as Node2Vec and DeepWalk are randomized (rely
on random walks), we run those algorithms multiple
times (sample size 100) and report our findings on the
sample.
We summarize the result of our classification anal-
ysis in Table 2, highlighting the metrics used for com-
paring the performance measures. As a reference, we
plot the model accuracy for each feature set in Fig-
ure 2. We note that the goal for this analysis was
not to optimize the model performance, buy rather
learn about the predictive power of each algorithm.
As highlighted, using carefully designed node fea-
ture (as highlighted in the previous section), one could
achieve accuracy of 66% in detecting bot vs. non-bot
accounts.
Features such as pagerank and coreness show pre-
dictive power as compared with other node features.
One could use this information to design similar fea-
tures related to node centrality and coreness to cap-
ture additional predictive power, however this pro-
cess is time consuming and could miss important fea-
tures. As we have suggested, a different approach
is to leverage unsupervised machine learning tech-
niques to capture various properties on nodes, without
time consuming featuring engineering. As we show in
this section, one could utilize node and structural em-
bedding to learn different types of representations of
node, and combine them to gain even greater predic-
tive power.
We see in Figure 2 that models trained exclu-
sively on features extracted using embeddings per-
form inline with a model trained using engineered
node features. Node embeddings, such as Node2Vec
and DeepWalk, could learn information about the
node’s local community and proximity, while struc-
tural embeddings could learn information about the
local structure of the network around each node. As
we can see, a combination of these features could cap-
ture a broader representation of nodes, and in fact per-
form as well, or even better than a model trained on
node features. In this case, All Embedding is a model
trained on a feature set built by combining all the em-
beddings together. We note that to make our com-
parison fair, we apply Principal Component Analysis
(PCA) to this combined feature set to reduce the di-
mensionality to 64 (same as embedding dimension of
the embedding algorithms). We also highlight the fact
that models trained using Role2Vec embedding out-
performs all other embedding, indicating that for the
Italian Election dataset, the structural property of the
nodes is a better indicator if an account is bot vs. non-
bot. Other metrics in presented in Table 2 tell similar
stories, where models trained on all embedding per-
form best in our study.
Lastly, we perform feature importance analysis on
the GF feature-set. Similar to the TwiBot-20 dataset,
pagerank appear in the top two most predictive fea-
tures. Given the difference in the topology of the two
graphs, TwiBot-20 and Italian Election, it is interest-
ing to observe pagerank appearing as one of the most
important features. However, unlike TwiBot-20, we
observe a number of important features derived from
statistics of node-features from neighbouring nodes of
each vertex. This indicates that identifying bots using
node-features requires more than local properties of
nodes. This further supports the use of embeddings,
since many embedding algorithms can learn global
properties of nodes.
We conclude this section by emphasizing that
the performance of each embedding on this dataset
Detecting Bots in Social-networks using Node and Structural Embeddings
57
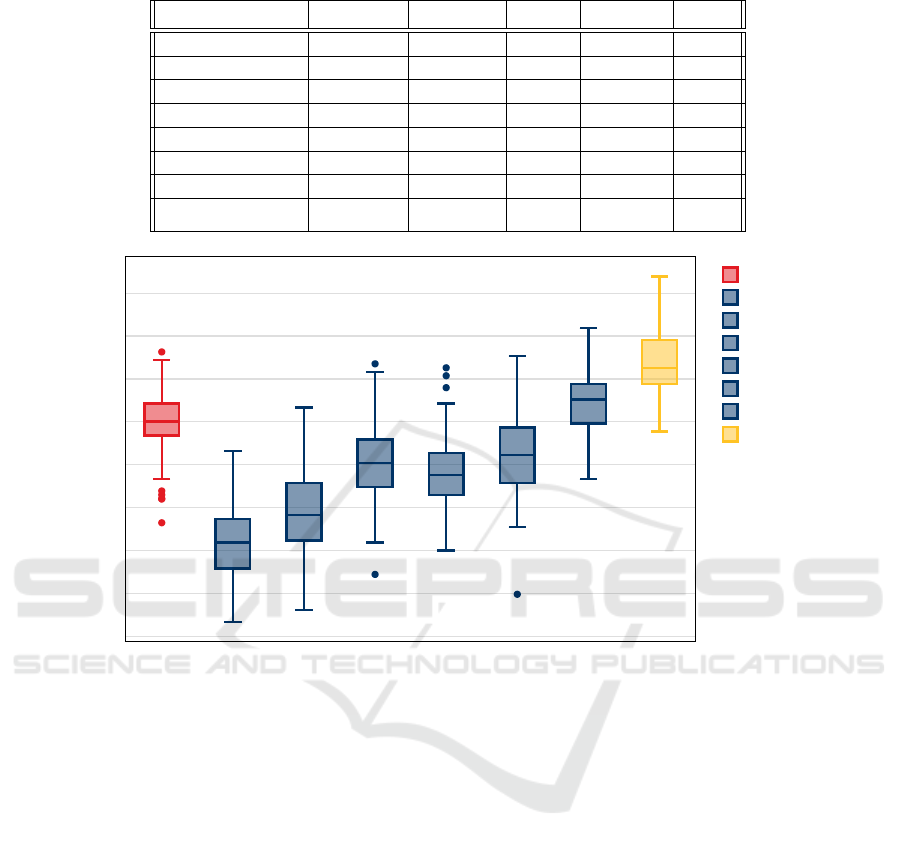
Table 2: Bot classification performance summary for the Italian-Election dataset.
Feature-Set Accuracy Precision Recall f1-Score MCC
Node Features 0.66 0.65 0.66 0.66 0.31
All Embeddings 0.69 0.70 0.64 0.67 0.38
Node2Vec 0.61 0.62 0.57 0.59 0.22
DeepWalk 0.62 0.62 0.59 0.60 0.23
LSME 0.64 0.64 0.65 0.64 0.29
Struc2Vec 0.63 0.66 0.55 0.60 0.27
GraphWave 0.64 0.65 0.61 0.63 0.29
Role2Vec 0.67 0.68 0.61 0.65 0.34
Node Features
Node2Vec
DeepWalk
LSME
Struc2Vec
GraphWave
Role2Vec
All Embedding
0.56
0.58
0.6
0.62
0.64
0.66
0.68
0.7
0.72
Node Features
Node2Vec
DeepWalk
LSME
Struc2Vec
GraphWave
Role2Vec
All Embedding
Accuracy
Figure 1: Accuracy for bot classification for the Italian-Election dataset. Distributions are over 10 runs of each embedding
algorithm and 10 runs of classifier. Accuracy is measured using sample size 100 runs.
(Italian-Election) is not an indication that they per-
form in similar range if applied to other datasets.
In general, embeddings are very application specific.
This can also be said about hand-designed node fea-
tures. Given the diversity amongst datasets, one
should aim to use techniques that learn a wide range
of representation of nodes in an unsupervised way.
For this reason, an embedding technique (or a com-
bination of them) could be power tool that could gen-
eralize well across various applications.
6 PREDICTIVE STABILITY
To understand the impact of data-noise on the qual-
ity of features extracted by embedding algorithms,
we performed simulations, where we artificially in-
troduced noise into the Italian Election dataset while
measuring the accuracy of bot classifier models. As a
benchmark, we compared all results against a model
built using node-features. Based on our simulations,
we found that features learned via embeddings are as
resilient to noise as node-features. These results are
highlighted in Figure 2, where we compared the per-
formance of each embedding algorithm (blue) against
a model built using node-features (red) and a model
built using the combined embedding features (yel-
low).
7 CONCLUSION
In this work, we examined four distinct feature-sets
extracted from the Twitter social network for identi-
fying bot accounts. We divided the features into those
captured directly from the Twitter network, NLP and
DATA 2022 - 11th International Conference on Data Science, Technology and Applications
58
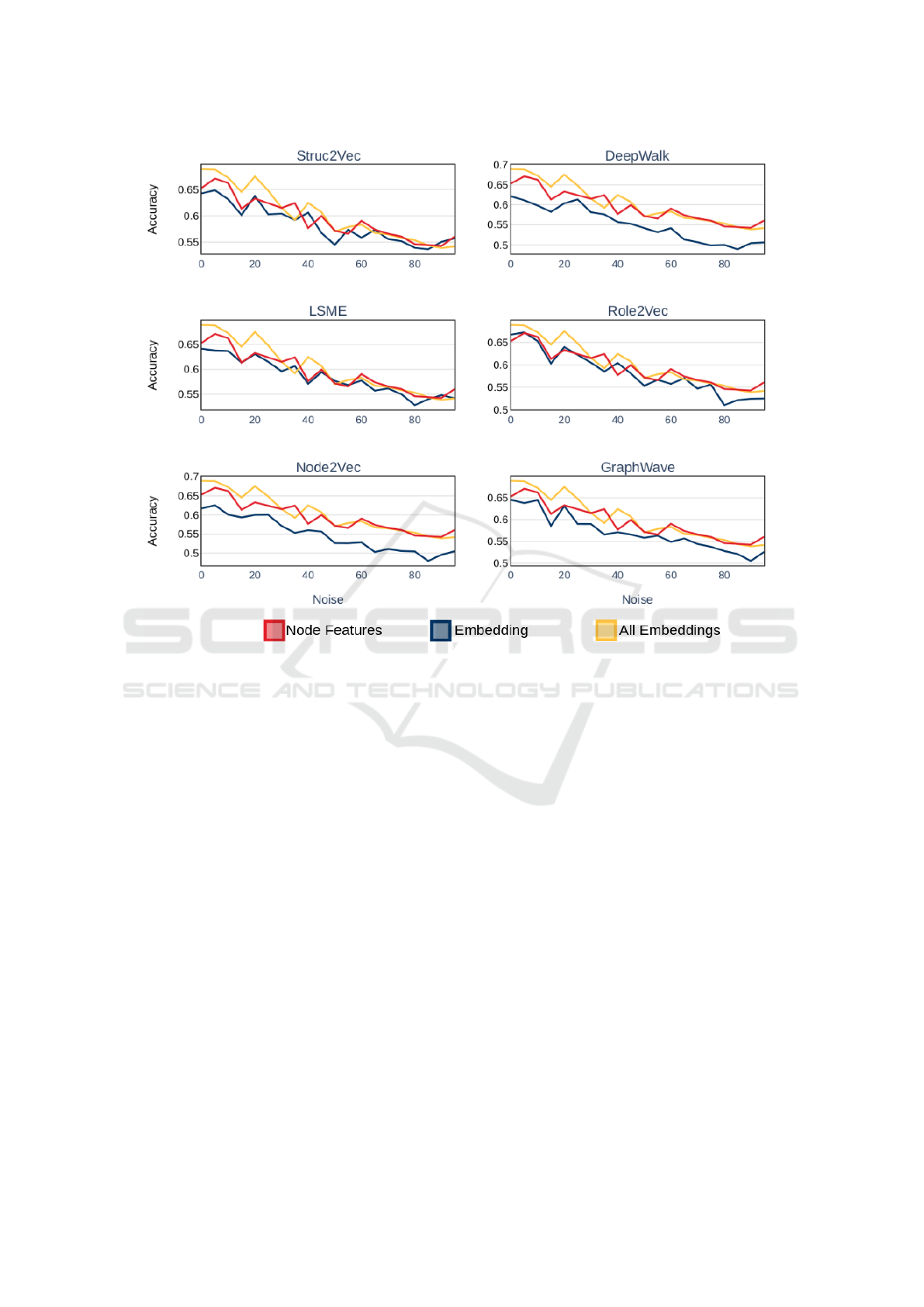
Figure 2: Stability of accuracy score: accuracy of node features (red), accuracy of specific embedding (blue), and accuracy of
all embeddings combined (yellow).
user-profile data, and those derived from the underly-
ing network structure, node-features and embeddings.
We showed that NLP and user profile features have
strong predictive power, however they suffer from the
lack of generalizability. For example, language mod-
els trained for identifying bot accounts in a English
speaking region can not be used to other regions. Sim-
ilarly, clever bot accounts can modify their user pro-
files to appear more natural (non-bot like), and avoid
being detected as bots. A much more difficult task
however is altering the topology of the social network
surrounding an account to appear as if it was created
organically. Building on this intuition, we showed
that the features extracted by mining graph structures
indeed holds predictive power in helping us identify
bots.
We analyzed features extracted from two Twitter
datasets, one (Twibot-20) built using the follower as
well as following relationships between users, and the
other (Italian Election) constructed based on the in-
teractions between users. We saw that in both net-
works, features mined from the underlying graph,
either through node-feature engineering or learned
in an unsupervised way via embedding algorithms,
have predictive power. This hints at the fact that
bot behaviour in a social network is distinguishable
from non-bot users in both how they (bots) build re-
lationships with other users and how they interact
with them. An interesting future research question
would be to study the impact of combining features
from various networks, for example one built on fol-
lower/following and another on user-user interaction,
for identifying bots.
Lastly, we showed that features captured using un-
supervised embedding techniques are as predictive for
bot classification as those built using node-feature en-
gineering. One major advantage of using embedding
algorithms is that they can learn a wide spectrum of
properties about the proximity and structural proper-
ties of nodes. We also showed that one could combine
features learned from various node and structural em-
beddings to a hybrid feature set.
Detecting Bots in Social-networks using Node and Structural Embeddings
59

REFERENCES
Ahmed, N. K., Rossi, R. A., Lee, J. B., Willke, T. L., Zhou,
R., Kong, X., and Eldardiry, H. (2019). role2vec:
Role-based network embeddings. In Proc. DLG KDD,
pages 1–7.
Aiello, L. M., Deplano, M., Schifanella, R., and Ruffo, G.
(2012). People are strange when you’re a stranger:
Impact and influence of bots on social networks. In
Sixth International AAAI Conference on Weblogs and
Social Media.
Antenore, M., Camacho Rodriguez, J. M., and Panizzi,
E. (2022). A comparative study of bot detection
techniques with an application in twitter covid-19
discourse. Social Science Computer Review, page
08944393211073733.
Bail, C. A., Guay, B., Maloney, E., Combs, A., Hilly-
gus, D. S., Merhout, F., Freelon, D., and Volfovsky,
A. (2020). Assessing the russian internet research
agency’s impact on the political attitudes and behav-
iors of american twitter users in late 2017. Proceed-
ings of the national academy of sciences, 117(1):243–
250.
Brown, T. B., Mann, B., Ryder, N., Subbiah, M., Kaplan,
J., Dhariwal, P., Neelakantan, A., Shyam, P., Sastry,
G., Askell, A., et al. (2020). Language models are
few-shot learners. arXiv preprint arXiv:2005.14165.
Cai, H., Zheng, V. W., and Chang, K. C.-C. (2018). A com-
prehensive survey of graph embedding: Problems,
techniques, and applications. IEEE Transactions on
Knowledge and Data Engineering, 30(9):1616–1637.
Carter, D. (2016). Hustle and brand: The sociotechni-
cal shaping of influence. Social Media+ Society,
2(3):2056305116666305.
Cha, M., Haddadi, H., Benevenuto, F., and Gummadi, K.
(2010). Measuring user influence in twitter: The mil-
lion follower fallacy. In Proceedings of the Interna-
tional AAAI Conference on Web and Social Media,
volume 4.
Chavoshi, N., Hamooni, H., and Mueen, A. (2016). Debot:
Twitter bot detection via warped correlation. In Icdm,
pages 817–822.
De Domenico, M. and Altmann, E. G. (2020). Unraveling
the origin of social bursts in collective attention. Sci-
entific reports, 10(1):1–9.
Dong, G. and Liu, H. (2018). Feature engineering for ma-
chine learning and data analytics. CRC Press.
Donnat, C., Zitnik, M., Hallac, D., and Leskovec, J. (2018).
Learning structural node embeddings via diffusion
wavelets. In Proceedings of the 24th ACM SIGKDD
International Conference on Knowledge Discovery &
Data Mining, pages 1320–1329.
Feng, S., Wan, H., Wang, N., Li, J., and Luo, M. (2021).
Twibot-20: A comprehensive twitter bot detection
benchmark. In Proceedings of the 30th ACM Interna-
tional Conference on Information & Knowledge Man-
agement, pages 4485–4494.
Freelon, D., Bossetta, M., Wells, C., Lukito, J., Xia, Y.,
and Adams, K. (2020). Black trolls matter: Racial
and ideological asymmetries in social media disin-
formation. Social Science Computer Review, page
0894439320914853.
Freitas, C., Benevenuto, F., Ghosh, S., and Veloso, A.
(2015). Reverse engineering socialbot infiltration
strategies in twitter. In 2015 IEEE/ACM International
Conference on Advances in Social Networks Analysis
and Mining (ASONAM), pages 25–32. IEEE.
Gonz
´
alez-Bail
´
on, S. and De Domenico, M. (2021). Bots are
less central than verified accounts during contentious
political events. Proceedings of the National Academy
of Sciences, 118(11).
Goyal, P. and Ferrara, E. (2018). Graph embedding tech-
niques, applications, and performance: A survey.
Knowledge-Based Systems, 151:78–94.
Grover, A. and Leskovec, J. (2016). node2vec: Scal-
able feature learning for networks. In Proceedings
of the 22nd ACM SIGKDD international conference
on Knowledge discovery and data mining, pages 855–
864.
Henderson, K., Gallagher, B., Eliassi-Rad, T., Tong, H.,
Basu, S., Akoglu, L., Koutra, D., Faloutsos, C., and
Li, L. (2012). Rolx: structural role extraction & min-
ing in large graphs. In Proceedings of the 18th ACM
SIGKDD international conference on Knowledge dis-
covery and data mining, pages 1231–1239.
Hwang, T., Pearce, I., and Nanis, M. (2012). Socialbots:
Voices from the fronts. interactions, 19(2):38–45.
Kami
´
nski, B., Prałat, P., and Th
´
eberge, F. (2021). Mining
Complex Networks. CRC Press.
Lehmann, J., Gonc¸alves, B., Ramasco, J. J., and Cattuto,
C. (2012). Dynamical classes of collective attention
in twitter. In Proceedings of the 21st international
conference on World Wide Web, pages 251–260.
Matwin, S., Milios, A., Prałat, P., Soares, A., and Th
´
eberge,
F. (2021). Survey of generative methods for social
media analysis. arXiv preprint arXiv:2112.07041.
Mikolov, T., Sutskever, I., Chen, K., Corrado, G. S., and
Dean, J. (2013). Distributed representations of words
and phrases and their compositionality. In Advances in
neural information processing systems, pages 3111–
3119.
Monti, F., Frasca, F., Eynard, D., Mannion, D., and Bron-
stein, M. M. (2019). Fake news detection on social
media using geometric deep learning. arXiv preprint
arXiv:1902.06673.
Perozzi, B., Al-Rfou, R., and Skiena, S. (2014). Deepwalk:
Online learning of social representations. In Proceed-
ings of the 20th ACM SIGKDD international confer-
ence on Knowledge discovery and data mining, pages
701–710.
Ribeiro, L. F., Saverese, P. H., and Figueiredo, D. R.
(2017). struc2vec: Learning node representations
from structural identity. In Proceedings of the 23rd
ACM SIGKDD international conference on knowl-
edge discovery and data mining, pages 385–394.
Rossi, R. A. and Ahmed, N. K. (2014). Role discovery in
networks. IEEE Transactions on Knowledge and Data
Engineering, 27(4):1112–1131.
DATA 2022 - 11th International Conference on Data Science, Technology and Applications
60

Sayyadiharikandeh, M., Varol, O., Yang, K.-C., Flammini,
A., and Menczer, F. (2020). Detection of novel social
bots by ensembles of specialized classifiers. In Pro-
ceedings of the 29th ACM International Conference
on Information & Knowledge Management, pages
2725–2732.
Stella, M., Cristoforetti, M., and De Domenico, M. (2019).
Influence of augmented humans in online interactions
during voting events. PloS one, 14(5):e0214210.
Woolley, S. C. and Howard, P. N. (2018). Computational
propaganda: political parties, politicians, and politi-
cal manipulation on social media. Oxford University
Press.
Yang, K.-C., Varol, O., Davis, C. A., Ferrara, E., Flammini,
A., and Menczer, F. (2019). Arming the public with
artificial intelligence to counter social bots. Human
Behavior and Emerging Technologies, 1(1):48–61.
Detecting Bots in Social-networks using Node and Structural Embeddings
61
