
Coordinated Access to Shared Data Sources for Geo-replicated State
Machines
Enes Bilgin
1
and Tolga Ovatman
2 a
1
Siemens R&D Center
˙
Istanbul, Turkey
2
Department of Computer Engineering, Istanbul Technical University, 34469
˙
Istanbul, Turkey
Keywords:
State Machine Replication, Geographic Locality, Serverless Computing.
Abstract:
State machine replication techniques are widely used to create fault tolerant services in cloud computing.
However, reaching consensus between remote regions may take substantially long time. Many algorithms are
proposed to solve this problem regarding the geographic locality of the objects while trading off some con-
sistency properties of the system. Most of these studies consider direct replication of arbitrary parts of the
system, but contemporary online services share some unique data sources that may not be replicated. This
paper proposes a coordinated method to manage shared data sources between replicas by utilizing geographic
locality of the data sources. The proposed algorithm present better performance than using a leader based ap-
proach in terms of request processing throughput. We provide the design and implementation of the proposed
algorithm in detail and present the throughput performance of the algorithm in a geographically distributed
environment.
1 INTRODUCTION
Geo-distributed state machine replication (Coelho
and Pedone, 2018) enables systems to tolerate failures
by maintaining consistent copies of an application’s
states at different geographical regions. Geographic
replication could improve performance by placing the
data close to the clients, which reduces latency and it
prevents failure in case of outages in different regions.
Even if application’s states are replicated, some sys-
tems may still share some non-replicable data sources
which can be local services from different regions or
single control units. This also raises new problems
in active replication techniques for the cases where
replicas are expected to process the requests in the
same order, but only one replica is able to update the
state of shared data sources.
Geo-replicated state machine studies in the liter-
ature focus on reducing latency between geographi-
cally distributed replicas while trying to reach con-
sensus. Therefore, it may be assumed that all data
sources of systems can be easily replicated. How-
ever, there may exist non-replicable third party online
services or private database accesses as shared data
sources. In our study, we work on a coordinated so-
lution to handle access to non-replicable shared data
a
https://orcid.org/0000-0001-5918-3145
sources, regarding their geographical positions, while
comprising the read consistency of the system. For
the use cases where read consistency is not of primary
concern (Eischer et al., 2020) this trade off could be
reasonable in improving performance of the system.
We have implemented two different approaches
using the Spring State Machine framework
1
. First
approach uses a predetermined replica to manage all
shared data sources (leader based approach) and the
second approach selects different replicas by consid-
ering their geographic locations in order to reduce la-
tency (coordinated approach).
In our experiments, we have implemented a geo-
graphically distributed state machine replica system
on Amazon Web Services. We get better performance
results when the system takes the geographical posi-
tions of shared data sources into account, especially
for the specific requests accessing the data source.
2 BACKGROUND AND RELATED
WORK
In this section, we provide background on replicated
state machines techniques and consensus protocols.
1
https://spring.io/projects/spring-statemachine
Bilgin, E. and Ovatman, T.
Coordinated Access to Shared Data Sources for Geo-replicated State Machines.
DOI: 10.5220/0011269600003266
In Proceedings of the 17th International Conference on Software Technologies (ICSOFT 2022), pages 625-629
ISBN: 978-989-758-588-3; ISSN: 2184-2833
Copyright
c
2022 by SCITEPRESS – Science and Technology Publications, Lda. All rights reserved
625

Additionally this section also motivates why coordi-
nated access is required between geo-replicas.
Replication techniques are divided into two cate-
gories as active and passive replication. In the pas-
sive replication, the primary state machine executes
the events and updates states of replicas. However, in
active replication, each event is processed by all repli-
cas and ends up in the same state. The active state ma-
chine replication uses consensus protocols for order-
ing requests by assigning them to slots with consec-
utive sequence numbers which define the execution
order. This also means that a replica can execute a re-
quest only after it has received and processed all pre-
decessors to ensure that all replicas execute the same
set of requests in the same order.
State machine replication (Schneider, 1990),
mostly serves to provide fault-tolerant systems. It
works by running the same deterministic state ma-
chine on multiple devices, called replicas, which pro-
cess events guaranteeing total order consistency. Con-
sensus is an abstraction where replicas agree on a
common value (e.g., the order, next operation to be
executed). One way to implement the consensus
algorithm is by using a leader based protocol like
Raft (Ongaro and Ousterhout, 2014), Zap (Junqueira
et al., 2011) and MultiPaxos (Chandra et al., 2007).
As a first step the replicas elect a replica as leader
which needs votes from a majority quorum of repli-
cas. Then the leader assigns requests to sequence
numbers by sending Propose messages to all repli-
cas. Each assignment must be confirmed by a ma-
jority quorum of replicas by replying with an Accept
message to the leader. The leader’s Propose message
also implicitly counts as an Accept. The operation is
committed by replicas when the leader confirms the
majority of votes received.
Most of the replicated systems are distributed
across different regions to be not affected by cascaded
failures in a single region. However, this causes se-
rious latencies when these consensus algorithms are
considered, and also wide area communication incurs
some latency overheads. Shortly, reaching an agree-
ment between different regions can take several hun-
dred milliseconds afterwards a request can be pro-
cessed. In terms of shared data source access, the
same rules are applied like geo-replication and still
there are some open problems to be solved. Reaching
to shared data sources from a close replica instead of
a remote leader will reduce latency.
In GeoPaxos (Coelho and Pedone, 2018), authors
are trying to solve the coordination among geograph-
ically distributed replicas. Instead of providing total
order consistency, their method proposes a partial or-
der for execution of operations. Besides, they are also
benefiting from the idea that objects are located at
sites where they are most likely to be accessed. In
our approach, we also take advantage of the idea to
keep a single replica for shared data sources.
In Mencius (Mao et al., 2008), researchers try to
find a better approach to implement Paxos (Lamport
et al., 2001) for geographically distributed state ma-
chines. Mencius is a multi-leader version of Paxos
and tries to eliminate the single entry-point require-
ment in Paxos. It splits the leader role across all repli-
cas by statically partitioning data and assigning a part
to each replica site. A client sends its request to the
nearest leader to avoid the first wide area communica-
tion step. In our approach, we do not require a leader
role for shared data access since we affiliate a single
replica with a designated shared data source.
In Gemini (Vogels, 2009), authors created a so-
lution to reduce latency across different regions by
relaxing consistency of some operations. Mainly,
they categorize operations as red (strong consistency)
and blue (weak consistency). Also, they provide a
method to increase the number of potential blue oper-
ations. Experiments show that benefiting from even-
tual consistency (DeCandia et al., 2007) for some op-
erations, significantly improves the performance of
geo-replicated systems. In our study, we designate
weak consistency for all of the operations that are per-
formed on reading from shared data sources.
In Weave (Eischer et al., 2020), authors tried to
minimize high response times of write requests which
occurred in case of totally-ordered geo-distributed
systems. To address this problem they present Weave
(Paxos based) that relies on replica groups in multi-
ple geographic regions to efficiently assign stable se-
quence numbers to incoming requests. Weave’s ar-
chitecture enables the protocol to perform guaranteed
writes without involving wide-area communication.
As recognized, these studies focus on improving
reaching consensus about order of operations regard-
ing geographic locations of requests; our approach,
alternatively, approaches the problem by initially con-
sidering (and increasing) the locality of operations
performed on shared data sources before ordering the
operations performed.
3 PROPOSED APPROACH
The proposed approach, presented in the pseudo-code
in Algorithm 1, utilizes geographic locality to remove
the induced latency during a replica’s access to a dis-
tant data source by delegating access operations to
a geographically closer replica. The closer replica
will perform all of the update and write operations
ICSOFT 2022 - 17th International Conference on Software Technologies
626
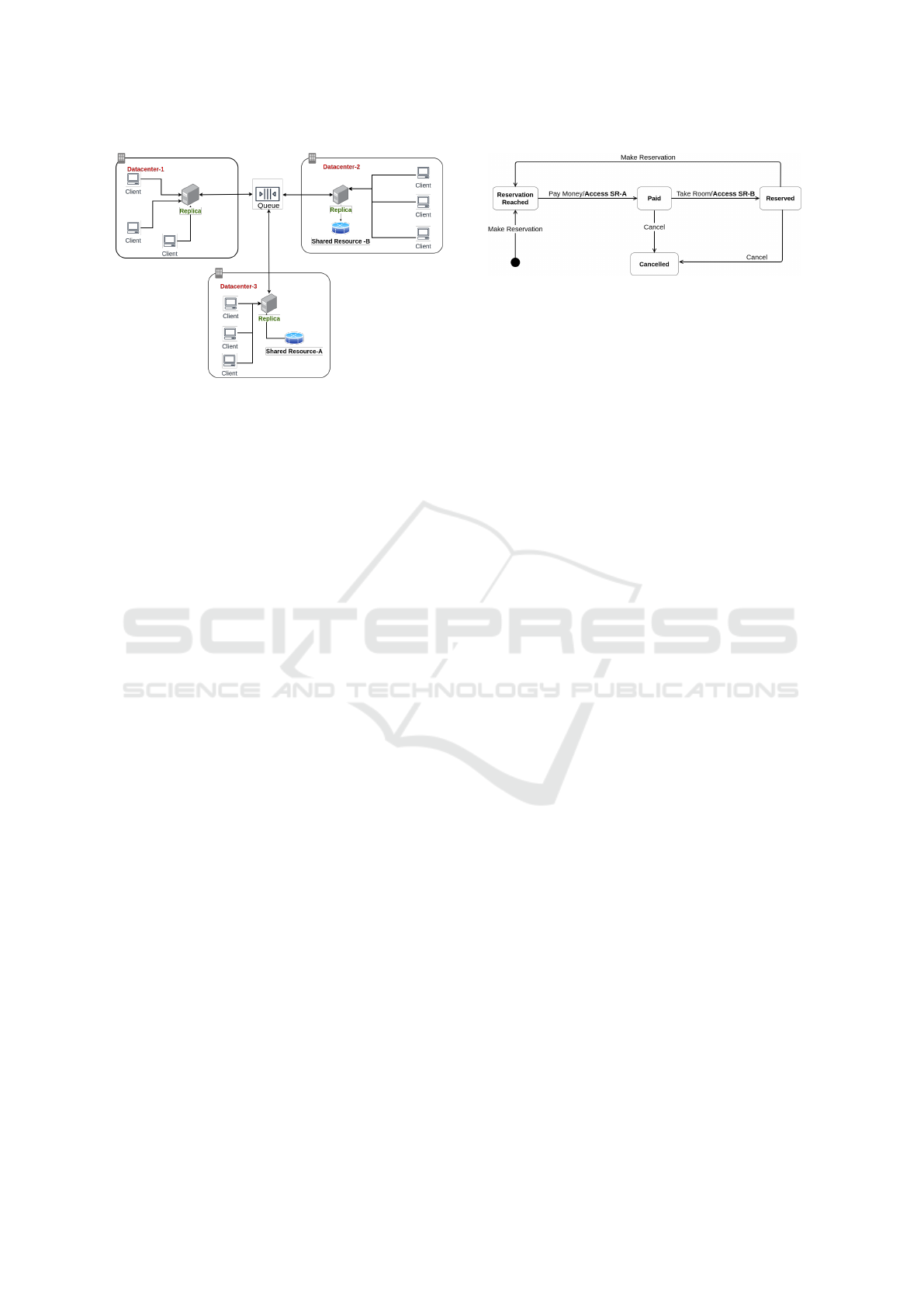
Figure 1: A deployment of the system in three regions.
on the data source and the other replicas will proceed
without experiencing a huge delay when accessing the
data on a remote region.
The replicas that are authorized to access the
shared data sources are determined with configura-
tion parameters of the system. These configuration
parameters also contain possible successors of these
authorized replicas in order to replace them in case of
stop-failures.
When implementing the coordination algorithm
we use a distributed queue to avoid missing some op-
erations in case of a failure in the replica(s) in the
shared data source’s site. The distributed queue keeps
a copy of the received requests in each replica so that
they can lazily perform the write operations on the
data source when no replicas exist because of a fail-
ure or any other reason.
A drawback of this algorithm is losing read con-
sistency of the system, since the shared data source’s
coordinator may perform the operations on shared
data later than the system. In our implementation
we use a consensus protocol relying on majority quo-
rums which may slow down the writing operations.
As mentioned earlier, our approach will be suitable
mostly for the systems where write consistency is of
prior importance.
4 EXPERIMENTAL
ENVIRONMENT
Figure 1 presents the overall architecture of the ex-
perimental environment we have implemented. In
our experiments we have used a fully replicated setup
in terms of application states and we distribute state
machine instances in different regions. Active state
machine replication is implemented by using Spring
State Machine framework which uses Zookeeper in
order to implement replication among replicas. Basi-
Figure 2: Experimental room reservation state machine.
cally, Zookeeper (Hunt et al., 2010) works as an API
which guarantees some consistency semantics such as
linearizability (Herlihy and Wing, 1990) for write op-
erations and eventual consistency (Vogels, 2009) for
read operations. Under the hood, Zookeeper also uses
a consensus algorithm, called Zap. This way, we pro-
vide all of the operations conducted on Zookeeper to
be linearizable.
We also placed non-replicable data sources on
different regions, in proximity of specific state ma-
chine instances. By definition, updating or writing
these data sources must be conducted only by a single
replica (coordinator).
Figure 2 presents the state machine used in our
experiments, representing the application logic of a
hypothetical hotel reservation application. In this
application, hotel reservation is performed in two
steps, once the room to be reserved is determined and
locked. In the first step payment is performed for the
room to be reserved and afterwards reservation is fi-
nalized and written to database. Databases for the
monetary transactions room reservation statuses are
distinct and kept in single locations where a state ma-
chine replica for each is running in the designated site.
Data sources (A and B) are placed in geographi-
cally distinct locations and accessed during two tran-
sitions of the state machine. We choose to define re-
quests of the system as events in order to be com-
patible with our design. Clients send requests to the
system from different regions. Data sources are ac-
cessed in transitions of state machine. In Figure 2,
each transition that performs a write on shared data
source (such as in Figure 1) is labeled with “SR-A”
and “SR-B” corresponding to “Shared Resource A”
and “Shared Resource B” respectively.
In our test scenarios we generate bursty write re-
quests from each simulated client with uniform ran-
dom distribution for a possible event that may be re-
ceived in a certain state. For the cases where the trans-
action is cancelled due to the receiving event or some
other failures we execute rollback operations if nec-
essary for the failing request.
Coordinated Access to Shared Data Sources for Geo-replicated State Machines
627
Algorithm 1: Sample Event Processing System.
procedure PROCESS(event)
if event contains writing a shared data source then
if Replica is leader then
add operation to queue
else if Replica is coordinator for the shared data source then
Pop the operation from queue
Apply the operation on shared data source
else
Skip the operation on data source
Move on to a new state
5 EXPERIMENTS
In this section we evaluate the proposed algorithm us-
ing the room reservation state machine replicas. We
run the leader based approach and proposed coordi-
nated algorithm on a cloud environment and compare
the results of using a conventional leader based ap-
proach and assigning coordinator replicas to shared
data sources. Implementation of the system that has
been used in the experiments can be accessed for the
author’s online repository
2
.
In our experiments, we have implemented a base-
line method, where just the leader of the replicated
cluster will access the shared data even if the source’s
locations is remote, causing latency problems. We
have compared this baseline method with the pro-
posed approach in terms of provided throughput and
latency. Throughput analyses are conducted on the
leader replica since the requests arrived on other repli-
cas are forwarded the leader replica by Zookeeper ar-
chitecture to be ordered properly. Clients submit their
request synchronously in a closed loop. We increase
the number of clients until the system is saturated and
no increase in throughput is possible. Clients connect
to servers through remote procedure calls and each
server has a local buffer store for incoming requests
and a separate thread to manage this buffer.
Replicas are deployed in different regions of AWS
(US, UK, Asia, Brazil and Sydney) in docker contain-
ers. We use t3.medium virtual machines of Amazon
EC2 platform to host our replicas. Our virtual ma-
chines contain 4 vCPUs, 4GB RAM and runs Ubuntu
20.04.2 LTS. When replicas are deployed in 5 differ-
ent regions, clients are also created in different ma-
chines in US, UK, Asia, Sydney and Turkey. Shared
databases are located in two different location in Asia
and the US which pushes the leader based approach
to reach the data sources other than its local region.
2
https://gitlab.com/enesbilgin61/sharedresourcecoordi
nator
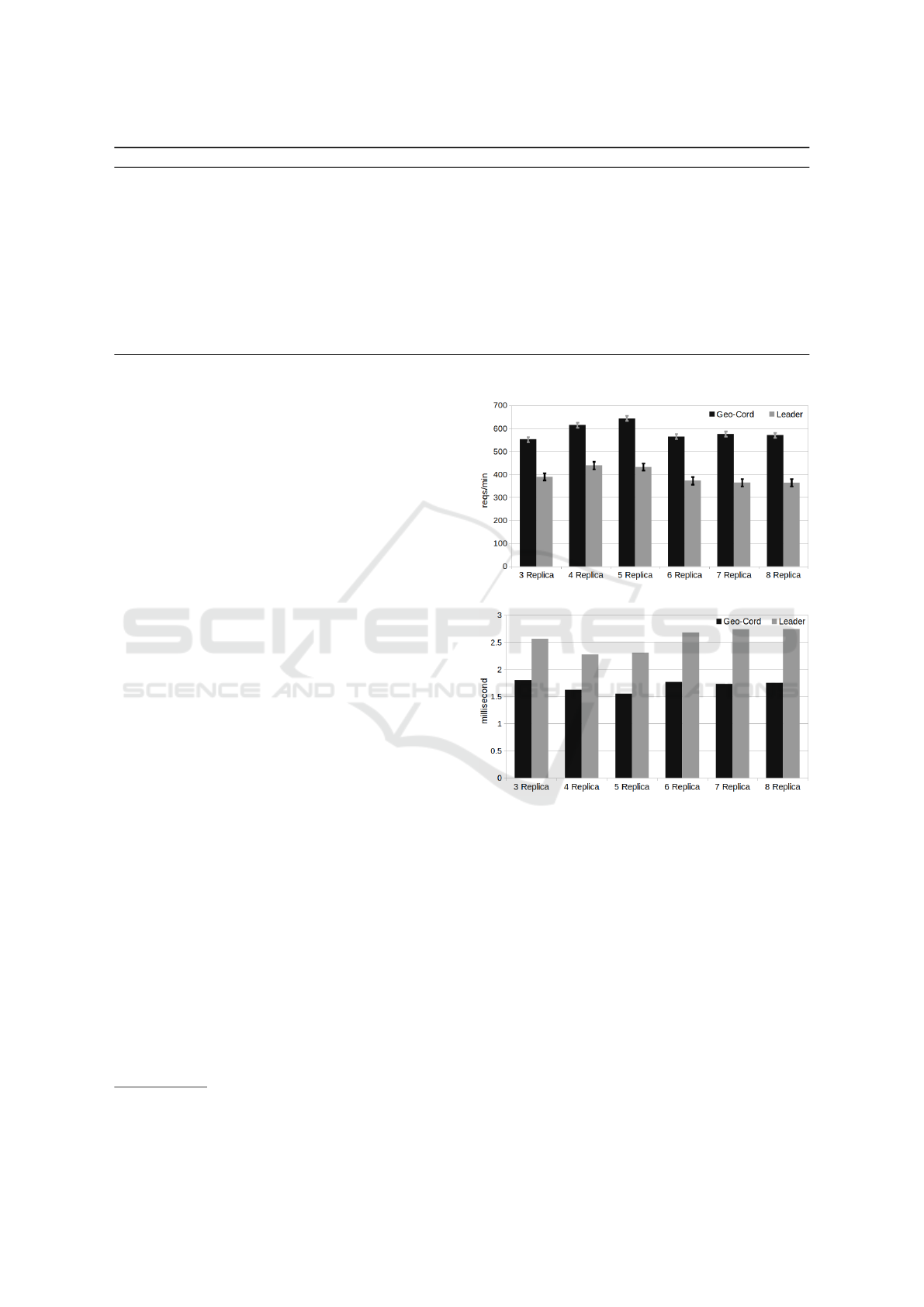
(a) Throughput comparison
(b) Latency comparison
Figure 3: Throughput comparison of the proposed coordi-
nated approach with leader based approach.
Figure 3 shows the throughput and latency results
when different number of replicas are spread through
five different geographical regions over AWS. In our
experiments we have used end-to-end latency by mea-
suring the average of each client’s request time span
from the beginning of sending the request until re-
ceiving the final response of the request (payment
done, room reserved, etc.). For the throughput of
the system, we have counted the number of requests
responded by our system and present the rate of re-
sponded requests per minute. Since our clients are is-
suing write requests (trigger state changes) in a bursty
fashion we have measured throughput from the per-
ICSOFT 2022 - 17th International Conference on Software Technologies
628

spective of state machine replica system as a whole.
Since, proposed coordinated approach can elimi-
nate much of the communication latency when reach-
ing the shared data it provides better throughput as the
number of replicas reach number of regions. When
the number of replicas exceed the number of avail-
able regions throughput decreases but still taking ad-
vantage of geographic locality by applying the coor-
dinated approach provides better throughput.
As the number of replicas increases, the distance
between consensus voting machines begins to in-
crease, causing an increasing communication delay
due to the distance.
For six, seven and eight replicas in Figure 3, the
replica count requires more votes for quorum that in-
creases the necessary number of messages exchanged
between replicas. Compared to five replica case, since
the advantage obtained by exploiting the geographic
locality is weakened (eight replicas are spread to five
regions as well) throughput naturally decreases.
6 CONCLUSION AND FUTURE
WORK
In this study, we proposed a coordinated way for repli-
cated state machines in order to access shared data
sources based on their geographical locations. This
approach is designed for event processing applica-
tions (consume write requests) which are replicated
and share some common data. The results indicate
that the coordinated approach outperforms the leader
based approach in cloud environment by compromis-
ing read consistency of the system.
ACKNOWLEDGEMENTS
This study is supported by the scientific and tech-
nological research council of Turkey (TUBITAK),
within the project numbered 118E887.
REFERENCES
Chandra, T. D., Griesemer, R., and Redstone, J. (2007).
Paxos made live: an engineering perspective. In Pro-
ceedings of the twenty-sixth annual ACM symposium
on Principles of distributed computing, pages 398–
407.
Coelho, P. and Pedone, F. (2018). Geographic state ma-
chine replication. In 2018 IEEE 37th Symposium on
Reliable Distributed Systems (SRDS), pages 221–230.
IEEE.
DeCandia, G., Hastorun, D., Jampani, M., Kakulapati,
G., Lakshman, A., Pilchin, A., Sivasubramanian, S.,
Vosshall, P., and Vogels, W. (2007). Dynamo: Ama-
zon’s highly available key-value store. ACM SIGOPS
operating systems review, 41(6):205–220.
Eischer, M., Straßner, B., and Distler, T. (2020). Low-
latency geo-replicated state machines with guaranteed
writes. In Proceedings of the 7th Workshop on Princi-
ples and Practice of Consistency for Distributed Data,
pages 1–9.
Herlihy, M. P. and Wing, J. M. (1990). Linearizability: A
correctness condition for concurrent objects. ACM
Transactions on Programming Languages and Sys-
tems (TOPLAS), 12(3):463–492.
Hunt, P., Konar, M., Junqueira, F. P., and Reed, B. (2010).
Zookeeper: Wait-free coordination for internet-scale
systems. In USENIX annual technical conference,
volume 8.
Junqueira, F. P., Reed, B. C., and Serafini, M. (2011). Zab:
High-performance broadcast for primary-backup sys-
tems. In 2011 IEEE/IFIP 41st International Con-
ference on Dependable Systems & Networks (DSN),
pages 245–256. IEEE.
Lamport, L. et al. (2001). Paxos made simple. ACM Sigact
News, 32(4):18–25.
Mao, Y., Junqueira, F. P., and Marzullo, K. (2008). Men-
cius: Building efficient replicated state machines for
wans. In Proceedings of the 8th USENIX Confer-
ence on Operating Systems Design and Implementa-
tion, OSDI’08, page 369–384, USA. USENIX Asso-
ciation.
Ongaro, D. and Ousterhout, J. (2014). In search of an under-
standable consensus algorithm. In 2014 {USENIX}
Annual Technical Conference ({USENIX}{ATC} 14),
pages 305–319.
Schneider, F. B. (1990). Implementing fault-tolerant ser-
vices using the state machine approach: A tutorial.
ACM Computing Surveys (CSUR), 22(4):299–319.
Vogels, W. (2009). Eventually consistent. Communications
of the ACM, 52(1):40–44.
Coordinated Access to Shared Data Sources for Geo-replicated State Machines
629
