
Towards Semantic Interoperability of Core Registers in Croatia
Kornelije Rabuzin
1
, Darko Gulija
2
, Leo Mršić
3
and Nikola Modrušan
4
1
Faculty of Organization and Informatics, University of Zagreb, Pavlinska 2, Varaždin, Croatia
2
Gulija Consulting and Smart Solutions, Vinogradska 74, Zagreb, Croatia
3
Algebra University Zagreb, Gradišćanska 24, Zagreb, Croatia
4
Central State Office for the Development of Digital Society, Ivana Lučića 8, Zagreb, Croatia
Keywords: Interoperability, Core Registers, EIF, Data Quality, Digital Government.
Abstract: Digital government assumes sharing and use of government data without restrictions. However, different
reports and indicators presented in this paper show that in Croatia, core register data could and should be used
and shared more extensively. In this way, better services to citizens and companies could be offered. The first
step to accomplish this goal is to examine core registers in Croatia, in order to detect possible issues and
problems which hinder data use, sharing and exchange. For that purpose, a project was started whose goal is
to analyse basic register data in Croatia. Findings from the first phase of the project, including the first set of
registers, are presented in this paper.
1 INTRODUCTION
In the past, all governments were analogue, working
almost exclusively with paper, with many non-
automated procedures that required a lot of manual
work. Then the concept of e-government was
introduced, leading to better services to citizens, as
processes stopped to being performed manually.
Consequently, this increased the speed and the quality
of services, both for citizens and companies. Today,
the concept of digital governments has its focus in
including citizens into making decisions, defining
priorities, proposing new ideas and services, etc.
Digital Government refers to the use of digital
technologies, as an integrated part of governments’
modernisation strategy, in order to create public value
(OECD, 2014). For that concept to be implemented,
it is necessary to use digital technologies, including
Internet, social media, cell phones, etc.
A public sector is considered data-driven when
generates public value through the reuse of data in
planning, delivering and monitoring public policies,
while adopting ethical principle for trustworthy and
safe reuse of data (OECD, 2019a). Also, it governs
and manages data as a strategic asset for the creation
of public value and the agile and responsive provision
of public services (OECD, 2019b). The OECD
proposed 12 key recommendations/ principles which
should support the digital transformation of the public
sector, grouped in three pillars: Openness and
Engagement, Governance and Coordination, and
Capacities to Support Implementation. Openness and
transparency as well as data driven culture play an
important role in the digital transformation.
Many principles and key ideas are crucial in
digital transformation, but one of the most important
facts is that data-driven governments ensure that
public sector data are shared inside and outside the
public sector in a trustworthy fashion, and under clear
protection, privacy, security rules and ethical
principles for national and public interest (OECD,
2019a). Open government data should be considered
as a public good, and should be proactively delivered
with a purpose, and with a focus on reuse, in line with
user needs and its potential contribution to creating
value (OECD, 2019a).
Estonia can be considered as an excellent example
of the large pool of digital services, both simple and
complex, that can be offered to citizens and
companies (Estonia X-Road. Open Digital Ecosystem
(ODE) Case study, 2020). With these services the
transparency is increased, there are solutions easily
accessible by using different devices, and different
services are available online, among others.
In order to get better services and to include
citizens, data sharing is crucial, which means that
government data cannot be stored as independent
silos between public bodies, but instead have to be
Rabuzin, K., Gulija, D., Mrši
´
c, L. and Modrušan, N.
Towards Semantic Interoperability of Core Registers in Croatia.
DOI: 10.5220/0011271100003269
In Proceedings of the 11th International Conference on Data Science, Technology and Applications (DATA 2022), pages 337-344
ISBN: 978-989-758-583-8; ISSN: 2184-285X
Copyright
c
2022 by SCITEPRESS – Science and Technology Publications, Lda. All rights reserved
337

used and shared. This will lead to processes to be
more streamlined and with a faster execution.
Core registers are “reliable sources of basic
information on items such as persons, companies,
vehicles, licenses, buildings, locations and roads”,
and “are authentic and authoritative and form,
separately or in combination, the cornerstone of
public services” (European Commission, 2015).
Also, they should be highly specialized, so each
register should not contain data about different
business entities. The interfaces between these
registries need to be defined, published and
harmonized, at both semantic and technical levels
(European Commission, 2015). Public
Administrations could (and should) get information
from different core registries without having to
require it to the business or citizen. Accessibility and
interoperability of core registries are enablers of the
Once-Only Principle (European Commission, 2015).
This principle states that each citizen and company
should only give each information once, to ensure
efficiency in the processes.
From an IT point of view, interoperability is a
property of computerized systems that represents the
ability to exchange information with other similar
systems. For the purpose of the European
Interoperability Framework (EIF), interoperability is
the ability of organisations (public administration
units) to interact with each other to achieve mutually
beneficial goals, involving the sharing of information
and knowledge between these organisations. This is
done through the business processes they support, by
exchanging data between their ICT systems (“The
New European Interoperability Framework,” 2017).
EIF distinguishes 4 different levels of
interoperability: legal, organizational, semantic and
technical. Semantic interoperability, which is
important for this paper, ensures that both the format
and meaning of exchanged data (and at the same time,
information) is preserved and understood throughout
exchanges between parties, i.e. ‘what is sent is what
is understood’ (“The New European Interoperability
Framework,” 2017).
Today, interoperability is an important topic, as
systems that do contain large amounts of data should
share it as well. Several reports conducted in the past
few years show that Croatia is generally not badly
ranking in the digital transformation topic.
Nevertheless, there is an issue with core registers in
Croatia, since they do not share data among them.
This complicates simple procedures for data owners
and citizens, since services that could be available
online still require a lot of written documents and
bureaucracy.
A project whose goal was to investigate and
improve the interoperability of public registers in
Croatia was approved. This project had in its team the
authors of this paper. In the first phase of the project,
18 registers were included, along one extra register
that already contains data aggregated from other
registers (so 19 registers in total). This paper brings
some findings which, in our opinion, will affect
further developments of interoperability and data
sharing between core registers in Croatia.
The rest of the paper is organized as follows; first
we present some general information about
interoperability and data sharing, and then we move
to the core register analysis. After that, future
research is presented, and in the end some
conclusions are given.
2 BACKGROUND
In the past few years different analysis and reports
were conducted in Croatia, revealing several
problems around these topics. One of them is that
core registers do not exchange data in a satisfactory
manner (for example, (World Bank Group, 2017)).
Digital Economy and Society Index (DESI), EU
eGovernment Benchmark, and EUROSTAT showed
there is an insignificant digitalization of Government
to Business (G2B) services and several challenges in
the reuse of business data in online forms (World
Bank Group, 2021). Furthermore, Both Croatian
National Development Strategy 2030 and National
Recovery and Resilience Plan (NRRP) recognized
that a slow pace of digitalization of G2B services
prevents faster improvements of the business
environment forms (World Bank Group, 2021). The
report also concludes that (World Bank Group, 2021):
The slow pace of digitalization of Government to
Business (G2B) services impedes faster
improvement of the business environment;
The provision of government services to
entrepreneurs (G2B) remains in an analogue
format, and the level of information exchange
between stakeholders is limited;
Both interoperability and integration of business
data are weak, and although the ICT solutions
currently in place are a step in the right direction,
they need to be further strengthened to correctly
provide G2B services.
For people and institutions this usually means that
they often have to submit the same data multiple time,
in paper forms, and to different public bodies.
Although some of this data is already stored in the
DATA 2022 - 11th International Conference on Data Science, Technology and Applications
338
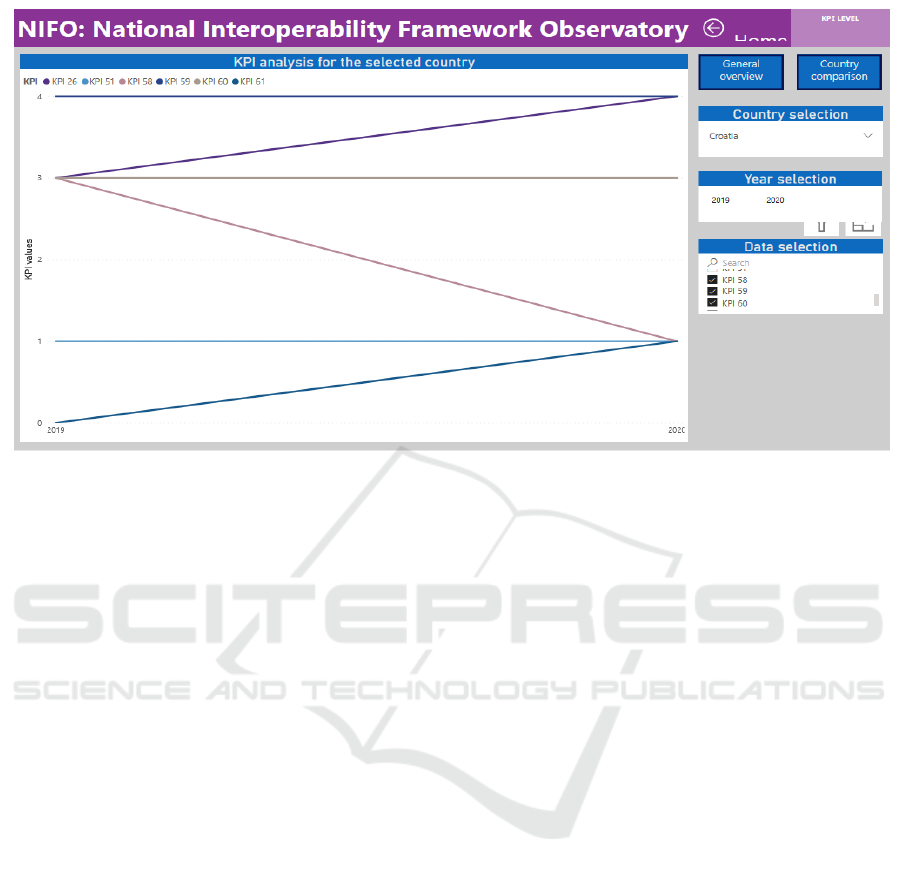
Figure 1: EU National Interoperability Framework Observatory KPI's related to Base Registries for Croatia for 2019 and
2020, accessed on October 24, 2021 (https://joinup.ec.europa.eu/collection/nifo-national-interoperability-framework-
observatory/eif-monitoring).
computerized systems, it is not easily available to be
used. This is frustrating, both for people and
companies as they have to submit the same paper
forms multiple times to get some services which
could be made available online. Registers containing
data are treated as independent silos, and the level of
data exchange is rather low.
The key performance indicators (KPI) from the
European Interoperability Framework Monitoring
Mechanism (EIFMM) that are related to the
interoperability of base registers for Croatia show
space for improvements, as shown in Figure 1.
In particular, the master data management and
reusable data structures for semantic interoperability
of core registers can be upgraded.
As seen in Figure 1, some KPIs are rated 1 out of
4:
KPI 26 - Extent to which the five major Base
Registries (Population, Vehicle, Tax, Land,
Business) are available for reuse in digital public
services;
KPI 51 - Existence of metadata, master data and
reference data management policies;
KPI 58 - Existence of agreements on reference
data in the form of taxonomies, controlled
vocabularies, thesauri, code lists and reusable
data structure/models to achieve semantic
interoperability of the Base registries;
KPI 59 - Existence of registry of Base Registries;
KPI 60 - Extent to which base registries draw up
and implement a data quality assurance plan to
ensure the quality of their data;
KPI 61 - Existence of a master data management
and Quality Assurance (QA) plans for one or
more of the five major Base Registries:
Population, Vehicle, Tax, Land, Business.
As discussed earlier, registers should represent
trusted sources of information containing data about
basic entities, which include people, vehicles,
businesses, etc. As it has been stated above, the
interoperability and data exchange are still not
satisfactory, and a good starting point for improving
semantic interoperability is to perceive data and
information as a valuable public asset (“The New
European Interoperability Framework,” 2017).
Within the first phase of the project the main registers
about persons and business entities were analysed. In
the next section the most important findings for
selected registers in Croatia will be presented.
3 CORE REGISTER ANALYSIS
This section is composed of several subsections that
cover different aspects of the analysis that has been
conducted during the project. One register contains
Towards Semantic Interoperability of Core Registers in Croatia
339

data aggregated from other registers, while one
register that is called “Metaregistar” contains
metadata about other registers. All other registers, 17
of them, contain data about people (birth register,
death register, register of life partnership …),
business entities (craft register, register of business
entities, court register…) and territorial units, all of
them included in this analysis. In the next phase of the
project, other core registers will be covered.
3.1 Database Management Systems
(DBMS) in Use
When looking at the selected core registers in Croatia,
it is clear that there are three main database
management systems in use, which are: MS SQL
Server, Oracle and DB2. Only one register is
implemented in PosthreSQL DBMS. Table 1 shows
the number of registers that are implemented in each
system:
Table 1: Number of registers per DBMS.
Database management systems Number of registers
DB2 5
MS SQL Server 3
Oracle 8
PostgreSQL 1
3.2 Naming Conventions –
Recommendations
Naming conventions could be defined as rules that,
although not written, if applied have the ability of
increasing the readability and understanding of the
model that is being generated. Usually, a database
contains a large number of tables, and by using these
naming conventions it is easier to find objects that are
needed at each moment. There are advantages of
using them in the implementation phase, for updating
data, for development application, among others.
The first question is whether to use singular or
plural when naming objects. In the conceptual design
phase, an entity type is usually specified as a singular
noun, while in the implementation phase table names
are usually plural nouns, since it is expected that each
table contains a large number of entity instances. To
connect two or three words usually the symbol “_” is
used; leading to the use of customer_purchase in
contrary to customerpurchase, for example. Also, it is
preferable to use lowercase writing, for example
customer_purchase, over CUSTOMER_PURCHASE.
Regarding the primary key, “_id” can be added to
the end of the column, like customer_id, or simply use
the id as a primary key column. A foreign key should
also be created in a similar way, for example, in the
orders table we could have a customer_id as a foreign
key, to denote that an order belongs to a customer.
When creating a constraint, it should also have a
name as well, and for example a primary key
constraint could be named as table_pk.
For columns that contain data we could use
country_code, country_name, etc. Also, when using
dates, it is better to specify what the date means, for
example start_date, end_date, etc. For columns that
can have binary values, like flags which denote that
something is added, updated, or deleted, it can be
used, for example, is_deleted, is_updated, etc.
There are also some rules for stored procedures,
functions, and views, but these were not explained in
this paper, since there was no access to registers’
databases and all the database objects. Also, for some
registers, only the documentation was available.
3.3 Naming Conventions - Analysis
Here we have to repeat that there was no access for
some registers of the database, and so, analysis was
done based on the available documentation. For that
reason, it is not possible to give answers to some of
the recommendations mentioned previously.
However, based on the analysis of selected registers
the following can be stated:
Column and table names are mostly in Croatian,
except for one database whose table and column
names are specified in English;
Regarding singular and plural naming
convention, some registers contain just one table,
so we did get only the column names, and not the
table name. For other registers, no rules were
taken into account in this matter. Table names are
always specified as nouns, sometimes as singular
and sometimes as plural;
Underscore is mostly used when naming objects
in databases, but many situations were found that
did not use this rule. For example,
DATUMRODJ is a column that represents the
birth date, where two words are merged together
without using “_” or any other special character.
Other example is PREZIMEBRACDRUGA,
which is a column name that consists of three
words that are merged together without any
separation (the spouse last name). Also, words
are written in uppercase, which goes against
previously stated naming conventions. As it is
DATA 2022 - 11th International Conference on Data Science, Technology and Applications
340

possible to see, this slightly affects and
diminishes the readability of the information;
Regarding upper and lower case, one register
uses combinations such as DateCreated, where
words are merged together, and each letter of a
new word is written in uppercase. The same
happens in the following example:
ContractDeliveryDate;
Regarding the primary key:
o some registers use only the ID as a
primary key column name,
o some registers use other identifiers, like
OIB or MBS, as they are usually good
natural keys,
o in some registers we have the
combination of ID and table name (for
example, ID_MATICE),
o some registers use arbitrary names for
primary keys.
Regarding the dates, we list some of the
examples found:
o DATUMUPISA - represents the date of
registration. As one can see, both words
are merged together and the underscore
symbol is not used,
o DATUM - is a date column, but it is not
known which value should be stored.
Luckily, there was a comment specified
for the column, so it was possible to
determine what should be stored and
what is the true meaning of the values,
o DATUM_VERIFIKACIJE - represents
the date when the entry was verified.
Most date columns in registers do
contain the word which denotes the
precise meaning of a date column (start
date, end date, date of change, etc.).
Comments are mostly not used, except for one
database which is well commented. Here we
were able to query the structure and to extract the
comments, as everything was specified in
English.
Based on the findings above, it is clear why
semantic interoperability may be hard to achieve.
Heterogeneous data sources, different naming
conventions, different column meanings, in some
cases even for the same column names, etc., represent
the challenges which will certainly affect the level of
interoperability of these systems.
Regarding the data access, it is clear that data is
protected, with several levels of security being
usually operational, like usernames and passwords,
certificates, Intranet, etc. Furthermore, in order to get
access to some of the registers, institutions require an
agreement to be signed first, and only afterwards data
access can be granted.
3.4 Data Types
When designing a database, it is important to select
appropriate data types. The recommendation is to use
standardized data types, since specific data types can
cause problems in migrations and/or integrations.
Also, usually new versions of the same database
management system do not support the exact same
data types. Some specific types can be declared as
obsolete, and in some point of time the support for
them will simply end.
One of the main identifiers in Croatia is the OIB
number (Personal Identification Number). It was
introduced in 2009, and is used for different purposes.
One of them is related to tax purposes, in order to help
to determine the amount of tax each citizen has to pay.
One of the reasons this number was introduced was
to comply with the EU legislation.
OIB should contain 11 digits (0 – 9), it should not
contain any private data and the number should be
randomly generated. Based on the previously
presented facts, the OIB data type should be specified
as CHAR(11). Since the last digit is a control digit,
when entering the OIB also it is possible to check and
calculate whether the entered value is correct or not.
In the analysis phase, it was found that different
data types were being used in the OIB columns, and
some of them possibly incorrect ones. While in the
OIB columns for some of the registers the data type
was set to CHAR(11), others used VARCHAR and
INT data types instead. This is not a good practice for
at least two reasons: different data types could cause
problems during the data integration phase, and by
selecting an inappropriate data type some data could
be lost, which is a big security concern. Since the
length of OIB is fixed, there is no need to use
VARCHAR, and using an INT data type could result
in data loss.
For other columns the data type selection was
somewhat appropriate. In some cases, the specified
length was a longer then actually needed; for
example, in one register the first name was specified
as VARHCAR(240), which is definitely too long to
store that kind of data.
Towards Semantic Interoperability of Core Registers in Croatia
341
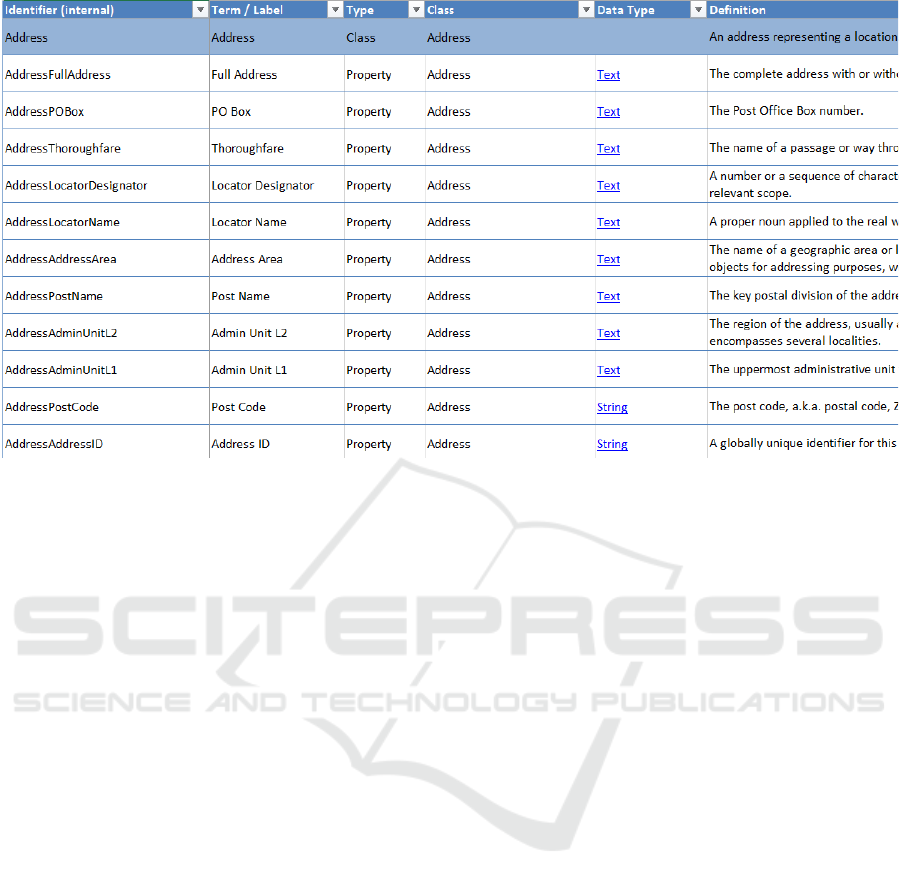
Figure 2: EUCore Vocabularies.
3.5 Authentic Data
Each register should contain authentic data and it
should be clear for each register which data is
authentic and which is not. The analysis revealed that:
the same data is declared as authentic in at least
two registers;
the data that should be authentic within the
register was not declared as authentic;
several registers hold the same redundant data,
which leads to unnecessary storage.
3.6 The Use of Standard Codes,
Vocabularies and Classifications
As proposed in (European Commission, 2015), the
use of controlled vocabularies should be obligatory.
EUCore Vocabularies are simplified, reusable and
extensible data models that capture the fundamental
characteristics of an entity in a context-neutral
fashion. These consist on the list below, and can be
also seen in Figure 2 (European Commission, n.d.-a).
The Core Business Vocabulary - simplified,
reusable and extensible data model that captures
the fundamental characteristics of a legal entity,
e.g. legal name, activity, address, legal identifier,
company type, and its activities;
The Core Location Vocabulary - a simplified,
reusable and extensible data model that captures
the fundamental characteristics of a location, for
example an address, a geographic name, or
geometry. The Location Vocabulary is aligned
with the INSPIRE data specifications;
The Core Person Vocabulary - a simplified,
reusable and extensible data model that captures
the fundamental characteristics of a person, e.g.
name, gender, date of birth, etc.;
The Core Public Service Vocabulary - a
simplified, reusable and extensible data model
that captures the fundamental characteristics of a
service offered by public administration. Such
characteristics include title, description, inputs,
outputs, providers, locations, etc. of the public
service;
The Core Public Organisation Vocabulary - a
simplified, reusable and extensible data model
used for describing public organizations in the
European Union.
Core Vocabularies can be used in two ways
(European Commission, n.d.-b):
By designing a new data model and either
binding it to an existing syntax or creating a new
syntax for it; or
By creating mappings from a data model to the
Core Vocabularies’ conceptual data model and to
the respective syntaxes.
DATA 2022 - 11th International Conference on Data Science, Technology and Applications
342
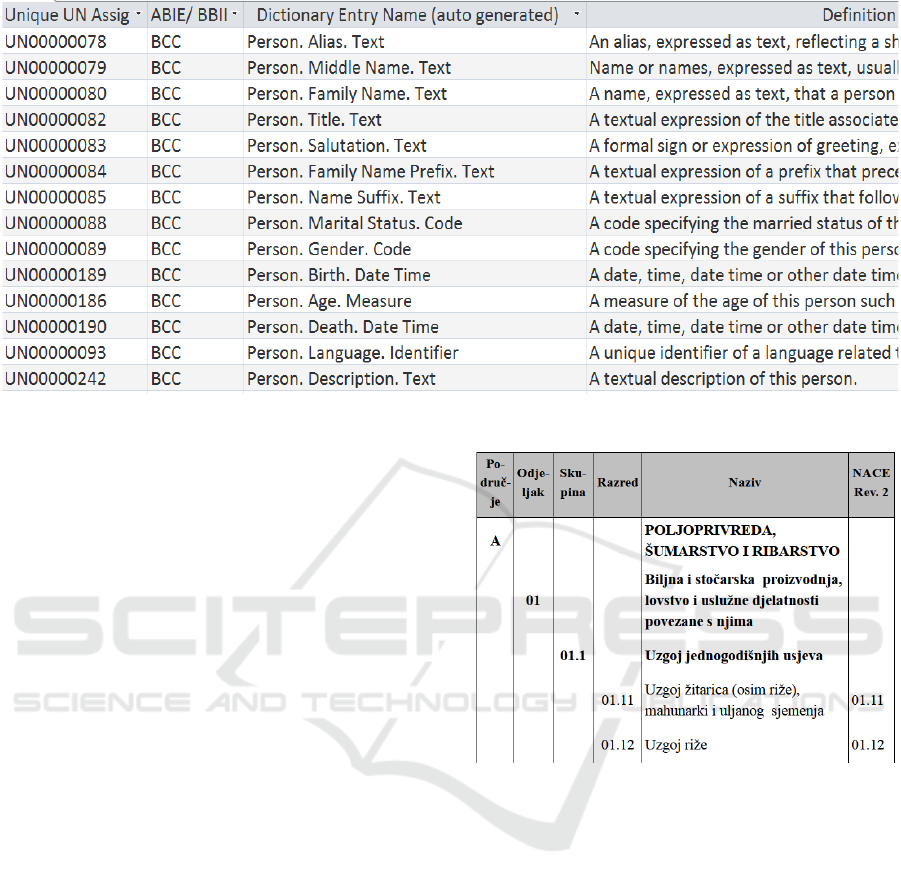
Figure 3: UN CCL.
The UN Core Component Library (CCL) is a
library of business semantics in data models that is
harmonized, audited and published by UN/CEFACT
(United Nations, 2012). The library contains a list of
business entities, for example party, organization,
location, person, etc., and they can be reused in
different domains and contexts. Business entities are
based on core components, and each component has
a vast number of attributes that are suitable and can
be used in different scenarios, as seen in Figure 3.
EUCore Vocabularies also define mappings
between different vocabularies, including mappings
between the EU Core Vocabularies and UN CCL.
There are also other vocabularies that can be used,
for example IMI Core Vocabulary or eIDAS
minimum dataset, but unfortunately, this cannot be
covered within the scope of this paper. However, one
of the goals of this work was to map the existing data
model that comes from different registers with Core
Vocabularies or UN CCL. This would lead one step
closer to semantic interoperability of the mentioned
registers, as proposed by (European Commission,
n.d.-b).
3.7 National Classifications
In Croatia there are two important national
classifications: national classification of activities
and national occupational classification.
National classification of activities contains areas
(one-letter mark), sections (two-digit number),
groups (three-digit numbers) and classes (four-digit
numbers), and be analyzed in Figure 4.
Figure 4: National classification of activities.
The national classification of occupations
contains a list of occupations, and was established for
the first time in 1998 by the Croatian Bureau of
Statistics. It is comparable to the International
Standard Classification of Occupations (ISCO-88).
The second updated version was released in 2008, and
it was changed later in 2010, after ISCO-08 appeared
in 2008.
We can conclude that database designers of the
analyzed registers were aware of the two
classifications, and both classifications were
extensively used within the registers.
However, when looking at some international
classifications, including ISO 3166 Country Codes,
ISO 4217 currency codes, etc., only two registers use
ISO 3166 country codes (register of territorial units
and personal identification number register), and
other classifications are not used at all. For example,
ISO 11179 classifications (used for objects,
Towards Semantic Interoperability of Core Registers in Croatia
343

properties, representations, etc.) are only used within
the Metaregistar.
There is also the register of territorial units (RPJ),
which holds country data on counties, cities, etc. This
is an important register as data from the register can
be used for different purposes. Although the register
contains important data, it is not used by the majority
of registers.
4 FUTURE WORK
At this stage, the research is extended to cover a larger
set of core registers, in a total of seventy core
registers. This phase should be finished until autumn
2022.
For the second phase, the goal is to implement a
small application which would be used to map
existing data models to EU Core Vocabularies or UN
CCL. In that way, it would be possible to solve some
of the issues mentioned previously. For example, it
would be possible to find authentic data, to find all
the attributes that are relevant for the basic set of
entities (persons, business entities, among others),
etc. Also, it would be possible to reconstruct basic
entities and their attributes based on the mappings.
This would be important for the design of new web
services which should integrate data from different
registers.
Since interoperability also covers organizational
and legal issues, the plan is to identify other issues,
and to amend existing regulations, laws and
procedures accordingly to the results of the study, and
the plan is to publish the findings in mentioned areas.
5 CONCLUSION
Within the project, whose goal is to analyze and to
improve the interoperability of public registers in
Croatia, the current state of the art was analyzed and
some findings regarding the core registers are
presented in this paper. Generally speaking, there is a
low level of data exchange between the registers,
which slows down the procedures, both for citizens
and companies. Namely, for the digital government
concept, data sharing is crucial, and there is still a
significant space for improvement in a form of core
register data sharing and exchange.
The analysis also revealed that heterogeneous
database management systems are in use, with
different naming conventions within the registers.
Also, standard vocabularies are not used, standard
classifications are used partially, and column
meanings are not always clear as conventions are not
always used, among others. These problems will have
to be tackled as they prevent the semantic
interoperability with the hinder of the development
towards digital government.
Also, some other issues were identified regarding
other aspects of interoperability, like legal and
organizational, but since they were out of the focus of
this paper, they will be discussed in future published
work.
REFERENCES
Estonia X-Road. Open Digital Ecosystem (ODE) Case
study. (2020). Retrieved from https://opendigital
ecosystems.net/pdf/01-Estonia-Case-Study_vF.pdf
European Commission. (n.d.-a). About Core Public Service
Vocabulary Application Profile . Retrieved January 22,
2022, from https://joinup.ec.europa.eu/collection/
semantic-interoperability-community-semic/solution/
core-public-service-vocabulary-application-profile/
about
European Commission. (n.d.-b). Semantic Interoperability
Community (SEMIC) - Core Vocabularies. Retrieved
January 22, 2022, from https://joinup.ec.europa.eu/
collection/semantic-interoperability-community-
semic/core-vocabularies
European Commission. (2015). Base Registries.
OECD. (2014). Recommendation of the Council on Digital
Government Strategies. Paris. Retrieved from
https://legalinstruments.oecd.org/en/instruments/OEC
D-LEGAL-0406
OECD. (2019a). 5th OECD expert group meeting on open
government data: Building an open and connected
government. Paris. Retrieved from https://www.oecd.
org/governance/digital-government/5th-oecd-expert-
group-meeting-on-open-government-data-summary.
pdf
OECD. (2019b). Digital Government in Chile – A Strategy
to Enable Digital Transformation. OECD.
https://doi.org/https://doi.org/10.1787/f77157e4-en
OECD. (2020). Digital Government Index: 2019 results.
https://doi.org/https://doi.org/https://doi.org/10.1787/4
de9f5bb-en
The New European Interoperability Framework. (2017).
Retrieved January 23, 2022, from https://ec.europa.eu/
isa2/eif_en
United Nations. (2012). UN CCL. Retrieved March 14,
2022, from https://tfig.unece.org/contents/uncefact-
ccl.htm
World Bank Group. (2017). Policy Options for Reforming
the Business Entry Regime, Summary note.
World Bank Group. (2021). Assessment of Digital
Government to Business Services - Croatia Business
Environment Reform II. Zagreb, Croatia.
DATA 2022 - 11th International Conference on Data Science, Technology and Applications
344
