
Linguistic Feature-based Classification for Anger and Anticipation
using Machine Learning
Kalaimagal Ramakrishnan
1
, Vimala Balakrishnan
2
and Kumanan Govaichelvan
2
1
Faculty of Science and Engineering, University of Nottingham Malaysia, Malaysia
2
Faculty of Computer Science and Information Technology, University Malaya, 50603 Kuala Lumpur, Malaysia
Keywords: Natural Language Processing, Covid-19, Machine Learning, Youtube, Linguistic Features.
Abstract: Growing number of online discourses enables the development of emotion mining models using natural
language processing techniques. However, language diversity and cultural disparity alters the sentiment
orientation of words depending on the community and context. Therefore, this study investigates the impacts
of linguistic features, namely lexical and syntactic, in predicting the presence two emotions among Malaysian
YouTube users, anger and anticipation. Term Frequency–Inverse Document Frequency (TF-IDF), Unigrams,
Bigrams and Parts-of-Speech Tags were used as features to observe the classification performance. The
dataset used in this study contains 2500 YouTube comments by Malaysian users on 46 Covid-19 related
videos. Comments were extracted from three prominent Malaysian-centric English news channels: Channel
News Asia (CNA), The Star News, and New Strait Times, ranging from 16 March 2020 – 30 April 2020 (i.e.,
first lockdown phase). Random Forest, Support Vector Machine, Logistic Regression, Decision Tree, K-
Nearest Neighbour and Multinomial Naïve Bayes were the six classification algorithms tested, with results
indicating Support Vector Machine with TF-IDF provided the best performance, achieving accuracy of 76%
and 73% for anger and anticipation, respectively.
1 INTRODUCTION
The spread of the infectious respiratory syndrome,
COVID-19 has led to countries worldwide to adopt
and implement drastic precautionary measures: travel
bans, complete or partial lockdowns and stay-at-home
orders. Consequently, the severity of the disease
spread, and its consequences affected the global
human population from various aspects, including
economy, education, employment as well as physical
and mental wellbeing (Ganasegeran et al., 2020). In
par with other countries, the Malaysian government
implemented partial lockdown or known as
Movement Control Order (MCO) since 18 March
2020. The National Security Council was in-charge
of the MCO implementation, and occasional changes
were made in the conditions imposed to cope with the
pandemic. During this lockdown period,
conventional survey-based studies were done to
observe the mental health of the citizens (Abdullah et
al., 2021; Kassim et al., 2021; Tsan et al., 2020), with
findings indicating increased incidences of anxiety
and depression among Malaysians.
The use of social media spiked during the
COVID-19 pandemic, with users resorting to the
platform to seek and share information, provide
support for each other etc. Amidst this chaotic period,
social media platforms such as Facebook, Twitter and
YouTube became a necessity for human interaction,
sharing information and providing comfort in a time
of need, hence serving as an efficient tool in infusing
positive hope among the public (Chen et al., 2020;
Limaye et al., 2020). Most importantly, the
government agencies including the Ministry of
Health and National Security Council used social
media to constantly update the public with facts and
figures and to live-stream important announcements
on YouTube, Facebook, etc. As a matter of fact,
studies have reported a significant increase in the use
of YouTube among the public for reliable health-
related information (Azak et al., 2021).
During a crisis, it is important for governments
and other relevant agencies to monitor the public’s
conditions to obtain situational awareness, and this is
made possible through Artificial Intelligence (AI).
Specifically, machine and deep learning approaches
play pivotal roles in automating social media
monitoring and extracting information such as the
mental wellbeing of users (Chau et al., 2020;
Kumnunt & Sornil, 2020) and emotions
140
Ramakrishnan, K., Balakrishnan, V. and Govaichelvan, K.
Linguistic Feature-based Classification for Anger and Anticipation using Machine Learning.
DOI: 10.5220/0011289300003277
In Proceedings of the 3rd International Conference on Deep Learning Theory and Applications (DeLTA 2022), pages 140-147
ISBN: 978-989-758-584-5; ISSN: 2184-9277
Copyright
c
2022 by SCITEPRESS – Science and Technology Publications, Lda. All rights reserved

(Balakrishnan & Kaur, 2019). Existing studies on
automated detections using textual communication
have explored various features to improve the
prediction including sentiment (Singh et al., 2018)
and emotion (Balakrishnan & Kaur, 2019), which
could be determined through text analytics. Other
features include textual or linguistic features such as
number of words, number of adjectives, adverbs etc.,
however such studies are scant. To fill this gap, the
present study proposes to develop a machine learning
model to examine the impact of linguistic features on
comments containing two major emotions, that is,
anger and anticipation.
2 RELATED WORK
Emotion mining or detection models are pretrained
with words categorized based on models such as
Ekman’s 6 basic emotions (Fear, Anger, Joy,
Sadness, Disgust, and Surprise) and Plutchik’s 8
Primary Emotions (Joy, Trust, Fear, Surprise,
Sadness, Disgust, Anger, Anticipation). The role of
emotion mining has become significant in healthcare
as it establishes better understanding on disease
related sentiments or frustrations (Balakrishnan &
Kaur, 2019). In the context of COVID-19, emotions
were identified based on social media textual
communications. For instance, A study examined the
keyword-based emotion dynamics for tweets and
Weibo from February to May 2020 (Li et al., 2020).
The authors found an increasing trend of anger for
keywords like ‘China’, ‘Trump’ and ‘Lockdown’,
whereas worry was closely associated with words like
‘syndrome’, ‘infected’, ‘finance’, ‘family’ and
‘food’. Li et al. (2020) also observed that the presence
of angry text documents with the word ‘Trump’
increased over President Trump’s racist remarks on
Chinese citizens or him calling them as ‘ching
chongs’. It is to note that keyword-based models
might not work well when the sentiment orientation
of words change depending on the cultural and
contextual disparity (Kaity & Balakrishnan, 2020).
Meanwhile, with the advent of natural language
processing techniques and developments in the field
of linguistic theories, linguistic features are used to
improve the efficacy of emotion mining. Linguistic
features can be divided into several categories:
syntactic, lexical, semantic etc. For instance,
syntactic feature extraction method includes Parts-
of-Speech (POS) tagging, which gives weights to the
grammatical role of a word in a document, or N-
gram, addressing the association between one word
with the consecutive word. On the other hand, lexical
features such as word frequencies provide insights
into the patterns of word used and the
sentimental/emotional content of the text (Rajput et
al., 2020). Very few studies have explored linguistic
features and their associations with emotions. For
example, Kumar and colleagues (Kumar et al., 2020)
used POS and Unigram to classify emotions in textual
data with a Naïve Bayes (NB) model, with an
accuracy over 80%. Sharupa et al. (2020) reported an
accuracy of 72% using Multinomial Naive Bayes
(MNB) with POS and Unigram. The authors claimed
that many studies that employ linguistic features
merely study dominant emotions like happiness and
sadness, hence the need to explore more emotions.
Few studies were also found targeting non-
English text. For example, a Korean corpus was used
to train a Support Vector Machine (SVM) model to
categorize 10500 tweets into 25 emotions, with an F1
measure value of 0.91 using word bigrams with POS
trigram (Jung et al., 2017). Finally, a more recent
study from Saudi Arabia included 242,525 Arabic
tweets to infer public’s attitude towards the COVID-
19 pandemic. Testing with three machine learning
algorithms: SVM, K- Nearest Neighbours (KNN) and
Naïve Bayes, along with the N-gram feature
extraction technique, SVM with Bigram coupled with
Term Frequency–Inverse Document Frequency (TF-
IDF) resulted in the highest accuracy of 85%
(Aljameel et al., 2021). Table 1 showcases the list of
studies used as a guide to design our experiment.
Table 1: Summary of studies on emotion and linguistic
features.
Authors
Features
Analysed
Dataset Results
(Kumar
et al.,
2020)
POS-tag,
Unigram with
Bag-of-Words
Sentiment
140 tweets
into 4
emotions
NB+Unigram
= 82%
accuracy
(Jung
et al.,
2017)
character, word
count, n-grams,
POS-tags, and
emotion
keywords (EK)
10500 Tweets
into 25
emotions
SVM
F-measure =
90.90%
(Sharupa
et al.,
2020)
POS tagged
unigram,
Unigram,
Bigrams
Sentiment140
tweets into 4
emotions
MNB =
72.3%
accuracy
Linguistic Feature-based Classification for Anger and Anticipation using Machine Learning
141

3 METHODOLOGY
The data were gathered from YouTube during the
first three phases of lockdown in Malaysia (16 March
2020 – 30 April 2020), specifically targeting a few
English-centric media including News Straits Times,
Channel News Asia (CNA), and The Star. The
comments were scraped using Coberry.com, an open-
source YouTube comment exporting tool, which
documents the comments as an Excel file. The titles
of the videos were scrutinized prior to data collection.
Specifically, only videos containing words like
‘MCO’ and/or ‘Covid-19’ and ‘Malaysia’ as part of
the title were selected to ensure content- specificity.
About 46 videos fit the criteria, and 5372 comments
obtained from the selected videos. All the phases
illustrated in Figure 1 are elaborated in the following
sub-sections.
Figure 1: Experimental workflow.
3.1 Data Preparation
Phase one involves data cleaning and pre- processing.
Several criteria were used to clean the data, including
(i) removal of non-English and non- Malay (i.e., local
national language) comments, (ii) removal URLS,
spams etc., (iii) removal of short comments (i.e.,
fewer than four words), and (ii) removal of duplicate
entries. This resulted in 3876 usable comments from
the initial dataset. Truncated texts that were
colloquially used were normalized into their complete
form, to prepare the data for translation. For instance,
among Malay- language comments, the character ‘x’
indicates negation, (i.e., synonymous to ‘tidak’). As
for the English comments, ‘pm’ for prime minister,
‘govt’ for government, ‘hosp’ for hospital and ‘Msia’
for Malaysia were found. Irrelevant or special
characters (e.g., %, & etc.) were removed as they can
potentially have a negative effect on the performance
of the classification model and reduce accuracy
(Balakrishnan et al., 2021). All the Malay comments
were then translated to English using Google
Translator, and later verified by two language experts,
who also provided the corrected versions when the
translations were found to be inaccurate.
Example 1: Correctly translated texts:
Original : Semoga semua rakyat Malaysia
terhindar dari virus ini.Amin.
Google : May all Malaysians be spared from this
virus…Amin.
Example 2: Manually corrected translations:
Original : apa pasal pergi kumpul... pasal kau orang
Google : What about going to a gathering
Translated: .... about you people
Manually Why are you gathering… it is because
Corrected of you people.
About 2500 comments were then randomly
selected for labelling based on Plutchik’s 8 Primary
Emotions (i.e., Joy, Trust, Fear, Surprise, Sadness,
Disgust, Anger, Anticipation). If the emotions were
present, ‘1’ was used, otherwise, ‘0’ was used, to
label the eight emotions. Noteworthy, emotions are
feelings specific to a situation and its context
(Namaziandost et al., 2021), therefore three
Malaysian-based linguistic experts were recruited to
label the comments. The Cohen’s Kappa value was
0.91, hence showing a strong agreement between the
annotators. An analysis of the annotation revealed
anger (36%) and anticipation (38%) to be the most
3.2 Feature Extraction
A feature can be described as an individual
measurable property or dimensions from the selected
dataset for the machine learning algorithm to process
(Barnard & Opletal, 2020). Feature extraction is a
useful step in building a model as it removes
redundant and irrelevant data, thus contributes to
enhancing learning accuracy of the machine learning
model (Kumnunt & Sornil, 2020). Notably, studies
have observed that too much features, especially
when texts are vectorized, results in redundancy, thus,
degrades the performance of the machine learning
model (Gopalakrishnan et al., 2020).
This study focuses on two features, namely,
syntactic, and lexical features. Individual words in a
DeLTA 2022 - 3rd International Conference on Deep Learning Theory and Applications
142

sentence are referred to as lexical features. It can
either be the presence or the frequency distribution of
the words in a corpus. Determining word frequencies
in any document, for example gives a strong idea
about the patterns of word used and the sentimental
content of the text (Rajput et al., 2020). The lexical
features were extracted using the Term Frequency –
Inverse Document Frequency (TF-IDF) method,
which designates higher weights to words that are less
frequent in a corpus and considers the frequency of
occurrence within the document they are used. In
other words, words that are commonly present in all
documents are assigned smaller weights (Sarkar &
Jana, 2019). The Python-based Natural Language
Toolkit (NLTK) was used for tagging the syntax of
each word based on grammatical functions. The
words were tokenized, and POS was tagged
accordingly. Both the features were extracted using
Python on Jupyter Notebook, specifically using
modules such as NLTK, SPACY and SKLEARN
3.3 Classification Model
As the performance of the data classification is
dependent on the model and the data quality, it is
important to test multiple algorithms. In this study,
six algorithms were used in detecting the emotions
(i.e., anger and anticipation) using the linguistic
features, namely, Multinomial Naïve Bayes (MNB),
Logistic Regression (LR), K Nearest Neighbor
(KNN), Decision Tree (DT), Random Forest (RF) and
Support Vector Machines (SVM). Naïve Bayes is a
popular algorithm used for classifying textual
documents. It assumes independence between the
features. For example, in text classification, the text
is considered as sets of words however, independent
of each other or their location in the text. Therefore,
the probability function for individual text is obtained
from the multiplication of the probability of the words
and their occurrences relative to the text length (Kaur,
2021). There are several variants to NB, one of which
is MNB. The algorithm is deemed to be good for text
classification (Rezaeian & Novikova, 2020).
Contrarily, LR-based model measures the statistical
significance of each independent variable in relation
to its probability. It is a robust way of modelling
binomial outcome (Shah et al., 2020), which is the
presence or absence of emotions in this study. The
KNN algorithm focuses on making predictions based
on the similarity level, using spatial vectors to
compute the similarity. The class prediction is based
on the pre-determined numbers of K value, and the
difference is studied based on Euclidean distance. In
the case of text classification, the training texts are fed
as feature vectors. Hence, the class prediction of the
incoming text are decided based on the similarity
between texts (Shah et al., 2020). SVM is mostly used
for classification problems. This method is a
statistical classification approach based on the
maximization of the margin between in the instances
and the hyper-plane. It is referred to as a non-
probabilistic binary linear classifier, capable of
separating the classes by a large margin, thus can
handle infinite dimensional feature vectors. Studies
have recommended SVM to be the best text
classification method (Al Amrani et al., 2018).
DT is a stratifying method that segregates
observations into simpler regions to make
predictions. In this study, DT algorithm is applied as
previous studies on text classification have tested and
recorded improved detection (Bahassine et al., 2016;
Pranckevičius & Marcinkevičius, 2017; Shi et al.,
2010). Finally, RF is an ensemble learning method
which constructs a number of decision trees during
training, with varying subsets of the dataset, and
provides mode class of each tree as the output (Al
Amrani et al., 2018).
3.4 Experiment and Evaluation
All the models were developed using Python and
tested on Jupyter Notebook. The performance of the
models was evaluated based on several metrics,
Firstly, Accuracy is based on the number of correct
predictions divided by the total number of predictions
made. Secondly, the precision is based on the actual
‘true positives’ among all predicted positive values.
Then, the recall is the actual ‘true positives’ predicted
correctly from the total actual positive values. F1-
measure the harmonic mean of precision and recall
and the Area Under Curve (AUC) - the two-
dimensional area underneath the ROC curve,
providing an aggregate measure of performance
across all classification thresholds. Discrepancies
between these metrics suggests methods to improvise
the classification performance, thus it is useful to
have more than one metrics to evaluate the model’s
performance (Requena et al., 2020).
4 RESULTS AND DISCUSSION
4.1 Emotion Distribution
The corpus was labelled based on the presence of
emotions according to Plutchik’s 8 emotions. Figure
2 depicts the emotion distribution for the 2500
labelled comments, revealing anger (40%; N = 1007)
Linguistic Feature-based Classification for Anger and Anticipation using Machine Learning
143
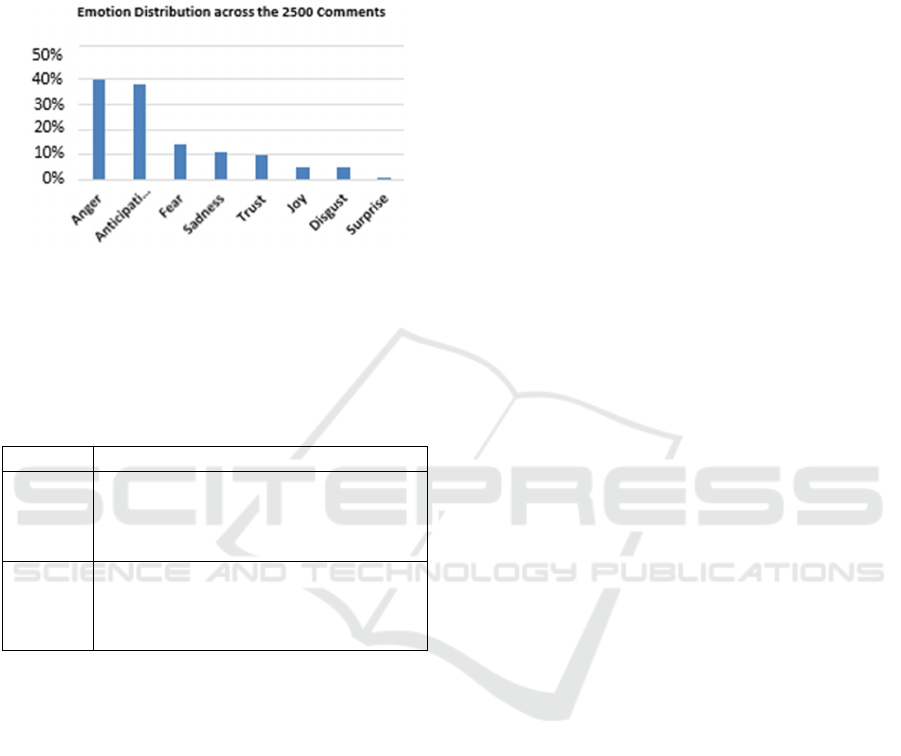
and anticipation (38%; N = 955) to be the two highly
expressed emotions among the YouTube users in this
study. This could be due to the uncertainty faced due
to Covid-19 outbreak coupled with political
instability within the country.
Figure 2: Emotion distributions based on Plutchik’s
Model.
Table 2 shows the top 15 words associated with each
of the emotions (arranged in highest number of
frequencies).
Table 2: Top 15 words for anger and anticipation.
Emotions Top 15 words
Anger people (274), China (214), government (159), Malaysia
(132), virus (117), like (110), please (102), still (101),
stupid (100), want (93), mask (91), home (86), go (83),
minister (81), many (71), time (68), get (66), country
(62), Malaysian (62), cases (62)
Anticipation Malaysia (184), people (117), good (117), stay (111),
virus (84), government (84), please (80), minister (76),
home (75), may (69), thank (67), like (66), hope (65),
country (64), cases (63), health (63), us (60), Malaysian
(59), Covid (58), well (58)
Anger is described as a psychosocial response to
subjective experience ranging from mild irritation to
extreme rage. Therefore, we can infer that the public
has expressed their anger towards the Chinese
government, political figures, and irritation due to the
delay in controlling the disease spread. Words like
‘China’, ‘government’, ‘stupid’, ‘still’, ‘time’,
‘minister’ are associated with anger in this corpus.
On the other hand, anticipation is the eagerness to
predict what comes next (Hodzik, 2013). Therefore,
words like ‘hope’, ‘thank’, ‘may’, ‘good’, ‘stay’ and
‘health’ indicate people’s expectation towards
resolving the crisis. For instance, Example 3 below
shows a user motivating fellow citizens to look
forward to an improved situation and cautions to
ensure older people’s safety. In Example 4, the user
expresses his/her concern due to the lockdown
situation. Both comments express anticipation as the
users expects actions from the decision-makers to
manage the crisis effectively.
Example 3:
When going gets tough, the tough gets going, Insya
Allah Malaysia overcomes this challenge only when
time comes. Keep the elderly in home and separate
from others. Importantly avoid casualty, this is the
time for the young ones to keep the elderlies safe.
Example 4:
Please consider private staffs is not enough. Please do
not extend we need money our savings are going to
finish. Do not torture us. Malaysians might commit
suicide or become mentally ill due to lockdown.
Words could be specific to certain emotions as
well. Notably, the word ‘mask’ is found to be
associated with anger. This could be associated with
reported incidents of counterfeit masks and
insufficient personal protective equipment (PPE) for
the general public, especially during the early stages
of the pandemic (Nienhaus & Hod, 2020). A sample
comment is provided as Example 5 below.
Example 5:
Even DIY is out of stock for masks! No more mask
available! Very hard for us to even buy food without
masks. The ministry reported that there are not
enough masks.
4.2 Impact of Linguistic Features on
Anger Classification
Table 3 shows the values of evaluation metrices for
the models experimented in predicting anger. It can
be observed that SVM (accuracy = 73%; F1- measure
= 62%) and LR (accuracy = 73%; F1- measure =
52%) outperformed other algorithms when all the
words were treated as unigrams, and vectorized using
TF-IDF. On the other hand, verbs and adjectives are
identified to be equally important features in aspect-
based sentiment analysis(Babu et al., 2020).
Therefore, the POS-tagging results show the
influence of nouns, verbs, and adjectives individually
and in combination for anger prediction. Other
combinations of features and algorithms did not
outperform the abovementioned two models.
Although not related to emotions, our findings are in
line with other studies that have showed SVM-TF-
IDF to produce the best results for text classifications
(Gupta & Baghel, 2018) For example, Gupta &
Baghel (2018) found best results were obtained using
SVM with TF-IDF and POS (accuracy = 94%; recall
= 91%; precision = 93%) based on 100,000
TripAdvisor comments.
NA (Nouns + Adjectives) features enabled RF and
DT to make better classifications compared to their
DeLTA 2022 - 3rd International Conference on Deep Learning Theory and Applications
144

respective baseline model. Contrarily, despite the
increase of MNB’s F1 measure 45% (NA) from 24%
(baseline), F1 measure below 50% indicates that
MNB is not suitable for this task (Derczynski et al.,
2012). This could be due to limited positive classes
resulting in class imbalance issue. However, as MNB
and KNN never attain F1 values above 50%
compared to other models, it can be inferred that these
two models are unlikely to be effective for this task.
Nevertheless, SVM remains the better performing
algorithm with NA features, achieving accuracy rate
of 73%, F1 of 60% and AUC of 77%. As observed in
a previous study, nouns and adjectives phrases
potentially contain key information to the sentiment
orientation of the words (Awan & Beg, 2021).
Therefore, the comparable performance of SVM-NA
with SVM-Baseline indicates that nouns and
adjectives are influential in detecting anger.
4.3 Impact of Linguistic Features on
Anticipation Classification
Table 4 shows the values of evaluation metrices for
the models experimented in predicting anticipation.
SVM emerged to be the best algorithm with the
highest accuracy rate at 76% followed by 75% for
LR. A similar trend in the performance of RF and DT
were also observed, when reduced features were fed
to the algorithm. It has been suggested that nouns
have higher weights than verbs due to its ability to
provide more information. This is because the
tendency to use nouns are more than verbs in a
sentence (Kieuvongngam et al., 2020). However, for
anticipation prediction, verbs alone enabled both RF
and DT to achieve F1 above 50%. Compared with
SVM-baseline, the best performing model, RF-Verb
provides the second-best classification based on all
three evaluation metrices (Accuracy = 73%, F1 =
53%, AUC = 75%).
Verbs refer to words that indicate an object’s or
person’s motion, action, belonging to a category or
quality, hence, contributing to the overall meaning of
the discourse (Fidyati & Rajandran, 2020). This helps
to classify comments that express expectations,
eagerness, and anticipation (Hodzik, 2013). It is also
noted that MNB’s F1 increased from 1% (baseline) to
22% (NA), however, the lack of robustness shows
that is not suitable for emotion classification with
vectorized words.
Table 3: Performance metrics for linguistic feature-based detection for anger.
Model
Features
MNB
LR KNN SVM DT RF
Acc. F1 AUC Acc. F1 AUC Acc. F1 AUC Acc. F1 AUC Acc. F1 AUC Acc. F1 AUC
Baseline .66 .24 .79 .73 .54
.82
.67 .41 .70
.73 .62
.80 .65 .53 .60 .69 .48 .77
Bigram .62 .28 .68
.68
.41 .68 .59 .40 .52 .67 .43
.69
.53
.45
.52 .64 .43 .66
N
.67 .35
.73 .68
.40 .73 .61 .30 .58 .66
.50
.71 .62 .49 .58 .66 .48 .71
A
.65 .31 .66 .63 .11 .62 .63 .36 .65 .54 .35 .58 .66 .56 .65
.68 .58 .73
V
.61 .19 .62 .60 .25 .63 .63 .37 .66 .56 .16 .47 .64
.53
.62
.65
.52
.69
NV .67 .35 .75 .68 .44
.75
.59 31 .54
.68 .54
.73 .62 .53 .61 .66 .50 .70
NA .71 .45 .78 .71 .49
.78
.63 .24 .56
.73 .60
.77 .67 .52 .65 .70 .51 .75
VA .67 .38 .70
.68
.42
.71
.62 .27 .57 .67
.50
.69 .63 .47 .60 .67 .47 .66
Note: Baseline = Unigram, N= Nouns only, A=Adjectives only, V= Verbs only, NV = Nouns + Verbs, NA = Nouns +
Adjectives, VA = Verbs + Adjectives.
Table 4: Performance metrics for linguistic feature-based detection for anticipation.
Model
Features
MNB
LR KNN SVM DT RF
Acc. F1 AUC Acc. F1 AUC Acc. F1 AUC Acc. F1 AUC Acc. F1 AUC Acc. F1 AUC
Baseline .70 .01 .75 .75 .43
.81
.73 .45 .67
.76 .56
.78 .67 .46 .61 .74 .38 .77
Bigrams .60 .12 .70 .63 .43
.72
.60 .44 .62
.66 .52
.71 .53 .42 .57 .62 .38 .70
N
.71 .21 .67 .71 .26
.70
.69 .20 .57
.71
.43 .69 .65 .39 .57 .71 .37 .67
A
.68 .04 .56 .70 .28 .68
.73
.40 .70 .64 .00 .52 .71 .51 .65 .71
.53 .73
V
.69 .06 .50 .68 .20 .66 .73 .41 .70 .67 .21 .41 .71
.54
.66
.73
.53
.75
NV .70 .18 .69 .72 .28
.73
.70 .11 .56
.72 .46
.70 .66 .41 .58 .72 .37 .69
NA .72 .22 .73
.73
.32 .75 .66 .21 .55 .72
.45
.73 .67 .43 .59 .73 .43 .71
VA .71 .20 .67
.72
.30
.68
.68 .25 .56 .70
.41
.66 .67 .38 .59 .69 .32 .65
Note: Baseline = Unigram, N= Nouns only, A=Adjectives only, V= Verbs only, NV = Nouns + Verbs, NA = Nouns +
Adjectives, VA = Verbs + Adjectives
Linguistic Feature-based Classification for Anger and Anticipation using Machine Learning
145

5 CONCLUSION
The present study developed linguistic feature- based
emotion detection (anger and anticipation) using
machine learning algorithms. Experiments conducted
using YouTube comments gathered during the initial
phase of Covid-19 lockdown in the country revealed
the role of POS features specific to anger and
anticipation prediction. Combinations of nouns and
adjectives improved the performance of RF for anger
prediction whereas verbs improved RF performance
for anticipation prediction. Overall, SVM + Unigram,
vectorized with TF-IDF yielded the best results in
predicting both anger and anticipation.
REFERENCES
Abdullah, M. F. I. L. B., Yusof, H. A., Shariff, N.
M., Hami, R., Nisman, N. F., & Law, K. S. (2021).
Depression and anxiety in the Malaysian urban
population and their association with demographic
characteristics, quality of life, and the emergence of the
COVID-19 pandemic. Current Psychology, 1-12.
Al Amrani, Y., Lazaar, M., & El Kadiri, K. E. (2018).
Random forest and support vector machine based
hybrid approach to sentiment analysis. Procedia
Computer Science, 127, 511-520.
Aljameel, S. S., Alabbad, D. A., Alzahrani, N. A., Alqarni,
S. M., Alamoudi, F. A., Babili, L. M., Aljaafary, S. K.,
& Alshamrani, F. M. (2021). A Sentiment Analysis
Approach to Predict an Individual’s Awareness of the
Precautionary Procedures to Prevent COVID-19
Outbreaks in Saudi Arabia. International Journal of
Environmental Research and Public Health 18(1), 218.
https://www.mdpi.com/1660- 4601/18/1/218
Awan, M. N., & Beg, M. O. (2021). Top-rank: a
topicalpostionrank for extraction and classification of
keyphrases in text. Computer Speech & Language, 65,
101116.
Azak, M., Şahin, K., Korkmaz, N., & Yıldız, S. (2021).
YouTube as a source of information about COVID-19
for children: Content quality, reliability, and audience
participation analysis. Journal of Pediatric Nursing.
Babu, M. M. Y., Reddy, P. V. P., & Bindu, C. S. (2020).
Aspect Category Polarity Detection Using Multi Class
Support Vector Machine With Lexicons Based Features
And Vector Based Features. situations, 7(11), 2020.
Bahassine, S., Madani, A., & Kissi, M. (2016). An
improved Chi-sqaure feature selection for Arabic text
classification using decision tree. In 11th International
Conference on Intelligent Systems: Theories and
Applications (SITA), 1-5.
Balakrishnan, V., Kaity, M., Rahim, H. A., & Ismail,
N. (2021). Social Media Analytics Using Sentiment
And Content Analyses On The 2018 Malaysia’s
General Election. Malaysian Journal of Computer
Science, 34(2), 171-183.
Balakrishnan, V., & Kaur, W. (2019). String-based
multinomial Naïve Bayes for emotion detection among
Facebook diabetes community. Procedia Computer
Science, 159, 30-37.
Barnard, A. S., & Opletal, G. (2020). Selecting Machine
Learning Models for Metallic Nanoparticles. Nano
Futures, 4(3), 035003.
Chau, M., Li, T. M., Wong, P. W., Xu, J. J., Yip, P. S., &
Chen, H. (2020). Finding People with Emotional
Distress in Online Social Media: A Design Combining
Machine Learning and Rule-Based Classification. MIS
Quarterly, 44(2).
Chen, Q., Min, C., Zhang, W., Wang, G., Ma, X., & Evans,
R. (2020). Unpacking the black box: How to promote
citizen engagement through government social media
during the COVID-19 crisis. Computers in Human
Behavior, 110, 106380.
Derczynski, L., Llorens, H., & Saquete, E. (2012).
Massively increasing TIMEX3 resources: a
transduction approach. arXiv preprint
arXiv:1203.5076.
Fidyati, L., & Rajandran, K. (2020). Representing The
Incumbent and The Contender in The 2019 Indonesian
Presidential Debates. Journal of Nusantara Studies
(JONUS), 5(2), 215-238.
Ganasegeran, K., Ch’ng, A. S. H., & Looi, I. (2020).
COVID-19 in Malaysia: Crucial measures in critical
times. Journal of Global Health, 10(2).
Gopalakrishnan, N., Krishnan, V., & Gopalakrishnan, V.
(2020). Ensemble feature selection to improve
classification accuracy in human activity recognition.
In Inventive Communication and Computational
Technologies (pp. 541-548). Springer.
Hodzik, E. (2013). Anticipation during simultaneous
interpreting from German into English: An
experimental approach. Quality in Interpreting:
Widening the Scope, 87.
Jung, Y., Park, K., Lee, T., Chae, J., & Jung, S. (2017,
2017/03/01). A corpus-based approach to classifying
emotions using Korean linguistic features. Cluster
Computing, 20(1), 583-595. https://doi.org/10.1007/
s10586-017-0777-8
Kaity, M., & Balakrishnan, V. (2020). Sentiment lexicons
and non-English languages: a survey. Knowledge and
Information Systems, 1-36.
Kassim, M. A. M., Pang, N. T. P., Mohamed, N. H.,Kamu,
A., Ho, C. M., Ayu, F., Rahim, S. A., Omar, A., &
Jeffree, M. S. (2021, 2021/01/07). Relationship
Between Fear of COVID-19, Psychopathology and
Sociodemographic Variables in Malaysian Population.
International Journal of Mental Health and Addiction.
https://doi.org/10.1007/s11469-020-0044-4
Kaur, R. (2021). Naive Bayes: A text classifier based on
machine learning. International Journal of Research
Publication and Reviews, 2, 260-266.
Kieuvongngam, V., Tan, B., & Niu, Y. (2020). Automatic
text summarization of covid-19 medical research
articles using bert and gpt-2. arXiv preprint
DeLTA 2022 - 3rd International Conference on Deep Learning Theory and Applications
146

arXiv:2006.01997. Kumar, E. R., Rao, A. R., & Nayak,
S. R. (2020).
Emotional Level Classification and Prediction of Tweets in
Twitter. In Emotion and Information Processing (pp.
161-169). Springer.
Kumnunt, B., & Sornil, O. (2020). Detection of Depression
in Thai Social Media Messages using Deep Learning.
In Proceedings of the 1st International Conference on
Deep Learning Theory and Applications - DeLTA 111-
118.
Li, X., Zhou, M., Wu, J., Yuan, A., Wu, F., & Li, J. (2020).
Analyzing COVID-19 on online social media: trends,
sentiments and emotions. arXiv preprint
arXiv:2005.14464.
Limaye, R. J., Sauer, M., Ali, J., Bernstein, J., Wahl, B.,
Barnhill, A., & Labrique, A. (2020). Building trust
while influencing online COVID-19 content in the
social media world. The Lancet Digital Health, 2(6),
e277-e278.
Namaziandost, E., Razmi, M. H., Heidari, S., & Tilwani, S.
A. (2021). A Contrastive Analysis of Emotional Terms
in Bed-Night Stories Across Two Languages: Does It
Affect Learners' Pragmatic Knowledge of Controlling
Emotions? Seeking Implications to Teach English To
EFL Learners. Journal of Psycholinguistic Research
50(3), 645-662.
Nienhaus, A., & Hod, R. (2020). COVID-19 among health
workers in Germany and Malaysia. International
journal of environmental research and public health,
17(13), 4881.
Pranckevičius, T., & Marcinkevičius, V. (2017).
Comparison of naive bayes, random forest, decision
tree, support vector machines, and logistic regression
classifiers for text reviews classification. Baltic Journal
of Modern Computing, 5(2), 221.
Rajput, N. K., Grover, B. A., & Rathi, V. K. (2020). Word
Frequency and Sentiment Analysis of Twitter Messages
During Coronavirus Pandemic. arXiv preprint
arXiv:2004.03925.
Requena, B., Cassani, G., Tagliabue, J., Greco, C., &
Lacasa, L. (2020). Shopper intent prediction from
clickstream e-commerce data with minimal browsing
information. Scientific reports, 10(1), 1-23.
Rezaeian, N., & Novikova, G. (2020). Persian text
classification using naive bayes algorithms and support
vector machine algorithm. Indonesian Journal of
Electrical Engineering and Informatics (IJEEI), 8(1),
178-188.
Sarkar, D., & Jana, P. (2019). Analyzing user activities
using vector space model in online social networks.
arXiv preprint arXiv:1910.05691.
Shah, K., Patel, H., Sanghvi, D., & Shah, M. (2020). A
comparative analysis of logistic regression, random
forest and KNN models for the text classification.
Augmented Human Research, 5(1), 1-16.
Sharupa, N. A., Rahman, M., Alvi, N., Raihan, M., Islam,
A., & Raihan, T. (2020). Emotion Detection of Twitter
Post using Multinomial Naive Bayes. In 11
th
International Conference on Computing,
Communication and Networking Technologies
(ICCCNT) 1-6.
Shi, L., Weng, M., Ma, X., & Xi, L. (2010). Rough set
based decision tree ensemble algorithm for text
classification. Journal of Computational Information
Systems, 6(1), 89-95.
Singh, N., Roy, N., & Gangopadhyay, A. (2018). Analyzing
the sentiment of crowd for improving the emergency
response services. In International Conference on Smart
Computing (SMARTCOMP) 1-8.
Tsan, S., Kamalanathan, A., Lee, C., Zakaria, S., & Wang,
C. (2020). A survey on burnout and depression risk
among anaesthetists during COVID ‐ 19: the tip of an
iceberg? Anaesthesia.
Linguistic Feature-based Classification for Anger and Anticipation using Machine Learning
147
