
Automated Video Edition for Synchronized Mobile Recordings of
Concerts
Albert Jim
´
enez
1 a
, Llu
´
ıs G
´
omez
2 b
and Joan Llobera
1 c
1
IZI C/casp 40 Ppal 1, 08010 Barcelona, Spain
2
Computer Vision Center, Campus UAB, Edifici O, 08193 Cerdanyola del Vall
`
es, Spain
Keywords:
Automated Video Edition, Computer Vision, Synchronized Recordings, Multi-camera Recordings, Camera
Selection, Attention Mechanism, Pointer Networks.
Abstract:
We propose a computer vision model that paves the road towards a system that automatically creates a video
of a live concert by combining multiple recordings of the audience. The automatic edition system divides
the edition problem in three parts: synchronize recordings with media streaming technology, selection of the
scene cut position, and the selection of the next shot among the different contributions using an attention-based
shot prediction model. We train the shot prediction model using camera transitions in professionally-edited
videos of concerts, and evaluate it with both an accuracy metric and a human judgement study. Results show
that our system selects the same video source as the ground truth in 38.8% of the cases when challenged
with a random number of possible sources ranging between 5 and 10. For the rest of the samples, subjective
preference among the selected image and the ground truth is at chance level for non-experts. Image editing
experts do reflect better-than-chance performance, when asked to predict the following shot selected.
1 INTRODUCTION
The abundance of mobile phone recordings in live
events creates an opportunity for a collaborative ap-
proach to video creation, where each member of the
audience records whatever fragments she wants to,
and an automated solution combines all the record-
ings to create a video showing the entire event from
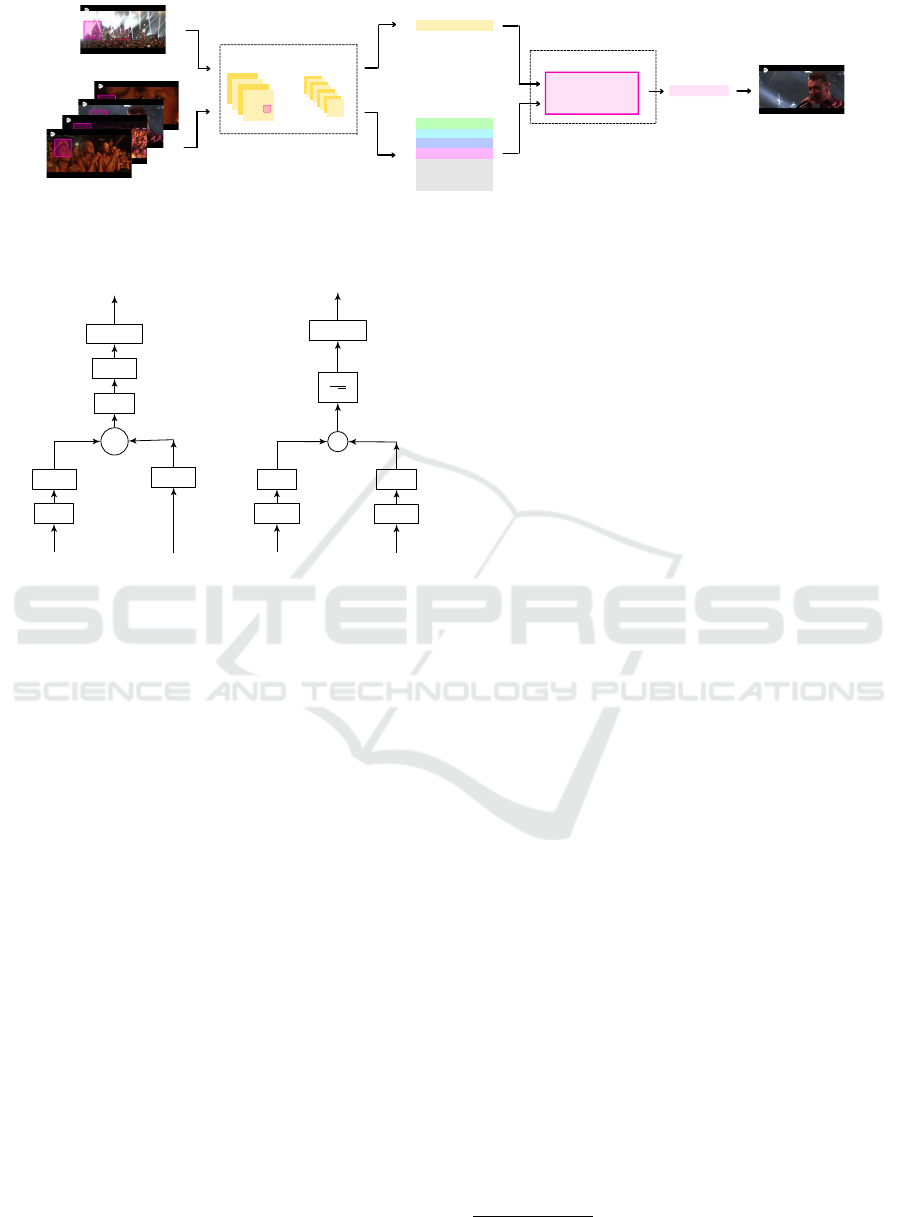
multiple angles and perspectives. Here we present a
computer vision model that paves the road towards an
automated system that combines the different video
recordings of an audience and the audio recorded
by the event organizer to create a common video
edit. More specifically, given a set of videos recorded
by different people and streamed synchronously to a
server, the computer vision model cuts among differ-
ent shots and selects the best cut transitions among the
options available (see Figure 1). The result is a video
that combines different viewpoints, but whose record-
ings are still synchronized with the audio recorded in
the event. Our solution separates the automatic edi-
tion problem in three parts: synchronize recordings
with media streaming technology, select the moment
a
https://orcid.org/0000-0002-3482-7589
b
https://orcid.org/0000-0003-1408-9803
c
https://orcid.org/0000-0002-9471-1334
Figure 1: Given a set of synchronised videos and cut posi-
tions (vertical lines), the proposed model chooses automat-
ically the next shot.
where there is a scene cut, and select the next shot
among the available contributions. In this paper we
focus on the later module: next shot prediction. We
present a model that learns to select the most suitable
camera from all the cameras available at any given
Jiménez, A., Gómez, L. and Llobera, J.
Automated Video Edition for Synchronized Mobile Recordings of Concerts.
DOI: 10.5220/0010847600003124
In Proceedings of the 17th International Joint Conference on Computer Vision, Imaging and Computer Graphics Theory and Applications (VISIGRAPP 2022) - Volume 4: VISAPP, pages
941-948
ISBN: 978-989-758-555-5; ISSN: 2184-4321
Copyright
c
2022 by SCITEPRESS – Science and Technology Publications, Lda. All rights reserved
941

time, inspired by Pointer Networks (Vinyals et al.,
2015). Contrary to previously published works on
automated video edition of multiple-camera concert
recordings (Laiola Guimaraes et al., 2011; Shrestha
et al., 2010), our model learns only from visual data
and does not rely on heuristic rules or manually anno-
tated meta-data.
The main contributions of this paper are: (1) a
novel computer vision model that, when given multi-
camera synchronized video streams, predicts the cam-
era selected in the next cut; (2) a framework to obtain
potentially unlimited training data for our model from
existing edited videos; (3) extensive experiments con-
ducted to demonstrate the validity of the proposed
model.
1
2 RELATED WORK
2.1 Automated Video Edition
Automated video edition in the context of multiple-
camera recordings has been studied previously.
(Laiola Guimaraes et al., 2011) proposed a semi-
automatic method based on video annotations and a
video selection algorithm aware of user preferences
and video authors. In (Shrestha et al., 2010), con-
cert mashup videos were generated by solving an op-
timization problem, maximizing the degree of fulfill-
ment of several cinematographic requirements such
as diversity or suitability of cut points from low-level
features. A similar social multi-camera setup was ad-
dressed by (Arev et al., 2014) in the sports domain.
Leveraging the insight that cameras focus their atten-
tion towards important content, they maximized the
coverage of important content while adopting cine-
matographic guidelines such as the avoidance of jump
cuts or the compliance of the 180-degree rule. These
approaches depend on priors, annotations or low-level
features and some require high computation capabili-
ties for longer videos.
Other automated editing methods are based on
complementary information that is provided along
with the videos, such as a transcript in dialogue-
driven or talking-head videos (Berthouzoz et al.,
2012; Fried et al., 2019; Leake et al., 2017), an oral
or written narration of the events (Truong et al., 2016;
Wang et al., 2019) or the music clip in a music-driven
video montage (Liao et al., 2015). It is not the case of
our proposed solution, in which the edition is solely
1
An example of video generated with this method
can be found at https://www.youtube.com/watch?v=
GaO3lzVZbF0&ab channel=IZIRecordingTogether
based on the video content. Also, some solutions
base the editions on pre-defined editing idioms that
the user can select (Leake et al., 2017; Liao et al.,
2015; Wu and Christie, 2015), as opposed to our data-
driven approach where stylistic choices are learned.
A few data-driven solutions have also been reported.
(Chen et al., 2018) propose a method for camera se-
lection in soccer broadcasting in which the impor-
tance of video sequences is predicted with a random
forest and C3D (convolutional 3-dimensional) fea-
tures. (Wu and Jhala, 2018) extract audio and human
pose features to automatically edit videos of corporate
meetings. A Long-Short Term Memory neural net-
work trained on features from professionally-edited
videos is then used to predict joint attention and make
edition decisions.
Opposed to the methods above, our solution de-
taches the shot duration and camera selection de-
cisions.Once the transition time is determined, the
most suitable camera is selected based on an at-
tention mechanism trained on professionally-edited
videos.Hence, in our novel approach each editing de-
cision is independent from previous footage.
2.2 Input Selection based on Pointer
Networks
A key element of our automated video editing sys-
tem is the ability to select the most suitable camera
from all the cameras available at any given time. For
this we use a pointer mechanism inspired by pointer
networks (Vinyals et al., 2015). Pointer networks are
sequence-to-sequence models, where each token in
the output sequence corresponds to a token at a cer-
tain position in the input sequence. The model selects
(points to) an input token through an attention mecha-
nism that models the probability distribution over the
input tokens.
Pointer networks have been previously used in a
variety of natural language processing and computer
vision tasks – such as document summarization (See
et al., 2017), neural machine translation (Gulcehre
et al., 2016), or scene text visual question answer-
ing (Singh et al., 2019; G
´
omez et al., 2020) In this
work we use a many-to-one architecture with a condi-
tional attention mechanism. The model selects one
of the many available inputs (cameras) conditioned
on the previous camera frame. Furthermore, we also
evaluate different types of attention (additive, multi-
plicative or scaled dot-product attention).
VISAPP 2022 - 17th International Conference on Computer Vision Theory and Applications
942
Current shot (t+shot_duration)
N candidate shots (t+shot_duration)
1 ≤ N ≤ 10
Current shot
Candidate shots
1 x n_features
N
10 - N
0 0 0 ... 0
0 0 0 ... 0
...
...
...
...
10 x n_features
Next shot prediction
Attention mechanism
0 0 1 0 0 0 ... 0
1 x 10
Prediction
(one-hot)
Current shot (t+shot_duration)
(...)
Feature Extraction - CNN
Figure 2: The next shot is predicted from the set of candidates at the transition time conditioned to the current shot.
f (I
q
)
f (I)
Tile
Dense
Dense
+
tanh
Dense
Softmax
p
att
f (I
q
)
f (I)
Dense
tanh
Dense
tanh
·
1
√
m
Softmax
p
att
(a) (b)
Figure 3: Computation graph of the attention mechanism
f
Att
for additive (a) and scaled dot-product (b) attention.
3 METHOD
Our solution is based on, first, using streaming tech-
nologies to capture the different camera recordings
with a common timeline. Then, we determine when
to cut and, finally what the next shot should be (see
Figure 2). In this article we focus exclusively on the
next-shot prediction module. The following-shot pre-
diction module selects the best candidate among all
available footage at that particular time instant. If no
other camera is available, the camera selected remains
the same. This strategy is similar to how a producer
would switch cameras in a live broadcast, and allows
for quick decisions based on a very limited amount of
images which can be done on the fly, with no need
to wait until the whole footage is available. Also, the
computation time grows linearly with the duration of
the final video, allowing to provide quick editions for
both short and long events.
3.1 Next Shot Prediction
To select what shot better follows the one that is cur-
rently shown we use an attention mechanism fed with
deep convolutional features obtained by processing
the current frame with a pretrained CNN, and keep-
ing the output of the last convolutional layer after
a Global Average Pooling. We used both an Xcep-
tion (Chollet, 2017) network pretrained on Imagenet
2
and a ResNet50 (He et al., 2016) pretrained on the
Places365 (Zhou et al., 2017) data set to produce fea-
ture vectors of dimensionality 2048. A comparison
of their performance when used alone and combined
can be found in the experiments section. Figure 3 il-
lustrates the computation graph of the attention mech-
anism that performs this task for two of the three at-
tention types we compared: additive, dot-product and
scaled dot-product. When we use additive attention,
we first tile the features of the current frame f (I
q
) to
match the dimensions of the candidate frame features
f (I) of shape 10×n
f eatures
, where 10 is the maximum
number of possible frame inputs during training and
n
f eatures
is the length of the feature vectors provided
by the pretrained CNN (2048 in our case). Second,
the tensors go through two different fully-connected
layers with m output units before being added and
activated with an hyperbolic tangent activation. The
resulting tensor goes through a final dense layer of
10 units and a softmax activation function to gener-
ate the output attention vector p
att
. This vector of
size 1 ×10 represents the probability of each candi-
date frame to succeed the reference one, and the cam-
era change is decided by sampling from this output
distribution, instead of taking argmax, in order to get
a more diverse and less ”loopy” behaviour from the
system. When we use either dot-product attention or
scaled dot-product attention, both the features from
the current frame f (I
q
) and candidate frames f (I) go
through a dense layer with m output neurons and an
hyperbolic tangent activation function. Then, the dot
product between the resulting tensors of size 10 ×m
and 1 × m respectively is calculated by stacking the
dot-product between each row of the first tensor and
the second tensor. For the case of scaled-dot prod-
uct, the resulting tensor of size 1 ×10 is scaled by
2
https://keras.io/api/applications/xception/
Automated Video Edition for Synchronized Mobile Recordings of Concerts
943

a scale factor
1
√
m
before applying a softmax activa-
tion to produce the output attention vector p
att
. This
is skipped in the case of dot-product, where no scale
factor is applied. We treat the number of neurons on
the hidden layers m of as a hyperparameter and tune it
with a grid-search, as reported in section 4.3. We also
observe that, when using Imagenet and Places365 fea-
tures in combination, we get better results by fusing
the features inside the model rather than just con-
catenating the feature vectors at the beginning. The
model takes the query features from both data sets
separately, learning different weights in the first dense
layer until both tensors are concatenated right before
the sum or dot-product step, depending on the atten-
tion type. The same applies to the features from the
candidate frames.
4 DATASET AND TRAINING
The ideal dataset to train our model would be a set
of images taken from different synchronized cameras.
Since we could not find such a data set for live con-
certs, we generated a data set that approximates this
ideal data set from edited live concert videos available
on YouTube.
4.1 Dataset Generation
First, we manually selected and downloaded 100 pro-
fessionally edited videos of live music performances
involving several cameras. The videos range from 2
to 102 minutes in length. The videos depict different
indoor and outdoor locations, different times of the
day, and different musical styles so that our attention
mechanism can learn to operate in different scenarios.
Second, we process the videos in two sub-steps:
1. We detect scene cuts in the videos and extract a
frame before and after each cut. The frame before
the transition is going to be the query in our atten-
tion mechanism, and we will call it current shot.
We consider the frame after the cut as the correct
prediction or ground truth annotation.
2. We randomly sample frames from the same video,
as well as from other videos to simulate the con-
tent of the other synchronized cameras that are
recording the concert. As they must not be se-
lected by our attention mechanism, we will name
them distractors.
At training time the ground truth was shuffled with
the distractors to form a set of images from which the
attention mechanism will have to choose one given
the current shot query. To extract the current shot and
the ground truth we used a simple threshold-based
scene change detector, PySceneDetect
3
(see Figure
4)The content-aware scene detector in PySceneDetect
finds areas where the difference between two subse-
quent frames exceeds the threshold value that is man-
ually set. Since using the default sensitivity threshold
of 30.0 did not provide good results for all videos,
when a significantly low number of transitions were
found, the threshold value was lowered; when a sig-
nificantly high number of transitions was found, we
manually checked for false detections and increased
the threshold until the number of false detections was
minimal, even if some real transitions were lost in the
process. Once a reliable list of transitions was gener-
ated for each video, we extracted the current shot and
ground truth with a simple rule: the current shot is the
image 5 frames before the transition, and the ground
truth is the image 5 frames after. This 5 frames mar-
gin allowed us to avoid smoother transitions, where a
shot faded into the next one as opposed to an imme-
diate cut.
Distractors simulate synchronized shots at the
time of the transition. They play an important role
in the training and evaluation of the model, since they
are the shots that the attention mechanism must learn
to not select. As our model is intended to work with
inputs of variable length, each pair of current shot and
ground truth frames were related to a variable number
K of distractors, ranging from a minimum of 4 to a
maximum of 9. For each shot, half of these distrac-
tors were random frames from the same video where
the current frame and the ground truth were extracted.
The remaining distractors come from random frames
of random videos other than the one of the current
frame and ground truth. We expected the distractors
extracted from random videos to be easier to discrim-
inate but also important, as we wanted the attention
mechanism to never choose videos with content in-
consistent with the event being recorded. In addition,
since all distractors were extracted from profession-
ally edited videos, the large majority correspond to
good quality images, both in terms of camera posi-
tion and of stability. To reflect the fact that in our
application scenario we expect to have low-quality
images, we applied a random combination of verti-
cal flip, image rotation and motion blur to a 10% of
the distractors. Rotations were bounded between −20
and 20 degrees. Motion blur was applied as a filter
either along the vertical, horizontal or diagonal direc-
tions, with a size of randomly set between 5 and 30.
To generate the distractors for a pair of current frame
and ground truth a feature vector was extracted for
each distractor and shuffled with the feature vector of
3
http://pyscenedetect-manual.readthedocs.io/
VISAPP 2022 - 17th International Conference on Computer Vision Theory and Applications
944

100 YouTube videos
Scene change detection
(PySceneDetect)
...
100 lists of transitions
(frame numbers)
f-5 -> current frame
f+5 -> next frame (GT)
For each transition save:
Figure 4: Extraction of the current frame and ground truth in the process of generating our data set.
the ground truth If the number of distractors K was
lower than 9, we added 9 −K zero vectors as padding
to provide the attention mechanism with an input of
constant size 10× n features.
4.2 Dataset Split
We split the 100 collected videos into three sets of 70,
10, and 20 for training, validation, and test respec-
tively. To keep the number of transitions balanced,
we ranked the videos by number of transitions, and
sampled uniformly the ordered video list to obtain the
validation and test sets. The remaining videos were
considered the training set.
Adding distractors to generate the input vectors
is handled differently in the training set, as opposed
to the validation and test sets. At training time, for
a given training sample, we pick a random number
of new distractors for each epoch, pooling them from
the set of pre-computed distractors. By doing so, the
model learns to choose the best shot among many
different options. As such, we increase the general-
ization power and reduce the chances of early over-
fitting. Opposite to this strategy, in the validation and
test sets we added a fixed random number of distrac-
tors to each sample. We also use the same combina-
tion of sample and distractors for all our experiments.
This is important to obtain evaluation metrics that do
not depend on random factors that may vary at each
iteration.
4.3 Training
We implemented our models using the Tensor-
flow[2.2.0] deep learning framework, and trained
them with a NVIDIA GeForce RTX 2070 SU-
PER. For each combination of features (Imagenet,
Places365, Imagenet+Places365) and attention type
(additive, multiplicative, scaled dot-product) we con-
ducted a grid search to optimize the validation accu-
racy by tuning the number of outputs of hidden lay-
ers (256, 512, 1024, 2048, 4096), the epochs (from
1 to 30), the Batch size (16, 32, 64, 128, 256), the
Optimizer (Adam, Nadam) and the Learning Rate (
0.0005, 0.001, 0.005).
5 EXPERIMENTS
To evaluate the performance of our next-frame pre-
diction model we perform two groups of experiments.
First, we evaluate the model using a standard accuracy
metric and compare it with several baselines. Second,
we perform a human judgement study to validate this
solution with subjective metrics.
Table 1: Accuracy comparison of different models using
random selection baselines, features pretrained on Ima-
geNet (IN), features pretrained on Places365 (PL) and fea-
tures pretrained on both IN and PL.
Method IN PL Acc.
Random-10 0.100
Random-7.5 0.133
Random-SameVideo 0.250
Additive attention 4 7 0.293
Multiplicative attention 4 7 0.283
Scaled dot-product attention 4 7 0.312
Additive attention 7 4 0.358
Multiplicative attention 7 4 0.366
Scaled dot-product attention 7 4 0.388
Additive attention 4 4 0.361
Multiplicative attention 4 4 0.346
Scaled dot-product attention 4 4 0.380
5.1 Accuracy Metrics
We evaluated our model with an accuracy metric as
in a standard classification task. We considered a pre-
diction correct when it matched the ground-truth, and
incorrect in any other case. We also included the fol-
lowing random and heuristic baselines:
• Random-10 the expected accuracy of a model
that selects one of the 10 inputs frames at random.
Automated Video Edition for Synchronized Mobile Recordings of Concerts
945

Current Shot GT Distractors
Figure 5: Test samples + distractors. On top the Current Shot and GT represent the images before and after a transition.
Bottom, the Current Shot and GT are not images before and after a transition.
• Random-7.5 the accuracy of randomly selecting
one of the input frames that are not part of zero-
padding. In average there are 7.5 non-zero inputs
in our test set (see section 4.1).
• Random-SameVideo same as above but in this
case randomly selecting a frame from the same
video as the reference frame (query).
Table 1 shows a comparison of the obtained accu-
racies with these baselines and different variations of
our model. In particular, we compare three different
scoring functions for the attention mechanism (addi-
tive, multiplicative, and scaled dot product attention)
using pretrained visual features on two different data
sets (ImageNet and Places365). Our model’s perfor-
mance is above the defined baselines for any combi-
nation of features and attention type. It can be seen,
however, that using pretrained features on Places365
represents a substantial improvement of at least 0.06
in accuracy with respect to using ImageNet features,
while the combination of both does not lead to an im-
provement of the model’s performance. Scaled dot-
product attention, on the other hand, leads to the high-
est accuracy for any of the given features with a mar-
gin of at least 0.019. Hence, the attention mecha-
nism that provides the best results is the one that uses
scaled dot-product attention and pretrained features
on Places365; with an accuracy of 0.388, the model
achieved this performance with a Batch Size of 128,
Nadam optimizer, a Learning Rate of 0.0005, hidden
layers of size m = 2048 and 15 epochs. It is also well
above any of the three baseline values.
5.2 Human Judgement Study
Accuracy metrics have a clear drawback for our ob-
jective: they do not take into account the subjective
nature of the task. Given the same query and set of
inputs, different editors may not agree in which is
the best next frame choice. To evaluate the quality
of our best model (scaled dot-product attention us-
ing pretrained features on Places365) in a more re-
alistic way we complemented the results with a hu-
man judgement study. Subjects were presented with a
query image (current frame) from the test set and two
options for the next shot: one option was the ground
truth frame and the other option was the prediction of
our model. They were asked to select the best option
following these exact instructions: In this task you
will see a reference image from a live music video,
your job is to select which of the two images below
(A or B) you think is better as a transition (after the
reference image) for a good scene cut. The two op-
tions (ground-truth and prediction) were randomly as-
signed to option A or B.
The study was conducted with a random subset
of 540 examples from the test set, excluding the ex-
amples in which our model prediction matched the
ground-truth. The rationale for this design was to
assess if the distractors selected by our system were
also perceived as ambiguous by humans, or rather the
criteria used by the trained system was very differ-
ent from subjective judgements. To measure the reli-
ability of the responses from human subjects, we also
added 60 control examples in which one of the op-
tions was a random image from the Places365 data
set. We used two groups for this subjective study:
1. Professional Workers with a level of Master com-
petence in Amazon Mechanical Turk(AMT), paid
0.05$ per response. In this group we collected 5
answers for each example.
2. A group of Creative Professionals in the fields of
video edition and graphical design, recruited as
volunteers among our group of acquaintances. In
this group we collected a single answer for each
example.
Both groups did the task in the AMT framework.
A total of 32 AMT Workers and 4 Creative Profes-
sionals participated. For the AMT group, the ratio of
correct answers in the control set was 0.993, and the
average time dedicated per assignment was 1 minute
and 44 seconds. For the Creative group, the ratio of
correct answers in the control set was 1, and the av-
erage time dedicated per assignment was 28 seconds.
AMT workers preferred the predicted frame (opposed
to the GT) in 47, 4% of the cases. When analyzed
with majority voting, the predicted frame preference
VISAPP 2022 - 17th International Conference on Computer Vision Theory and Applications
946
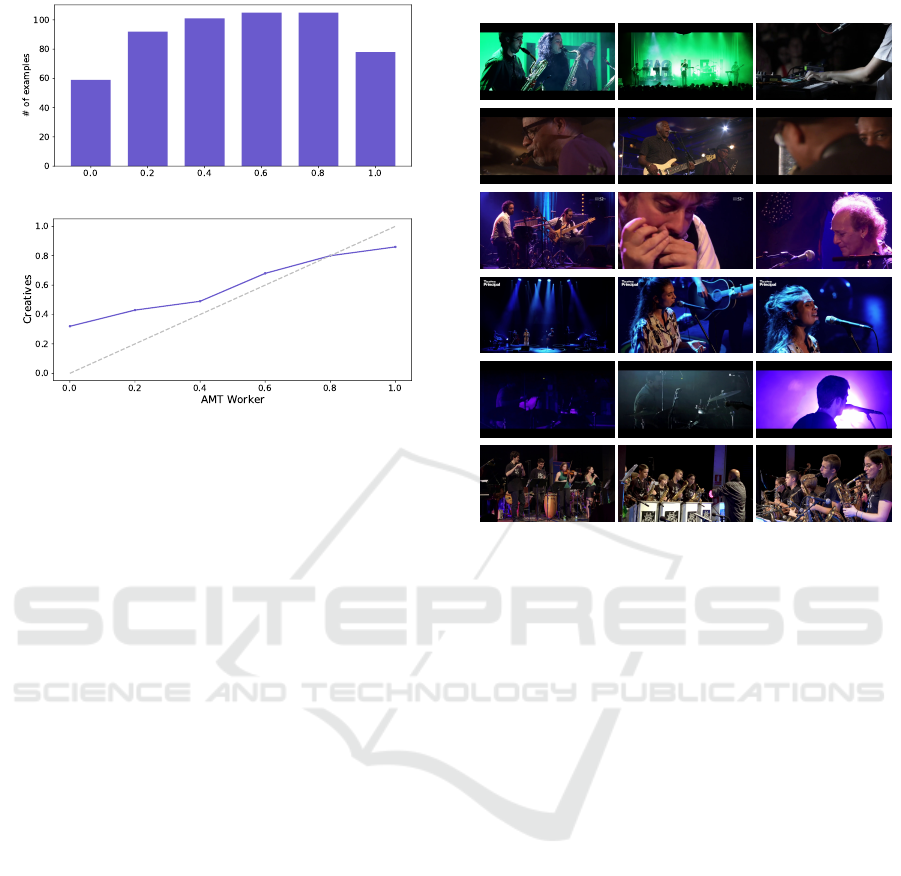
(a) Histogram of images as preferred by AMT Workers.
(b) Relation between responses of AMT Workers and Cre-
atives. The dotted line of slope 1 is used as a reference.
Figure 6: Subjective preferences of AMT workers per re-
sponse accuracy. Accuracy is considered per group: accu-
racy of 1 occurs when the 5 responses of AMT Workers se-
lected the ground truth option. Accuracy of 0 occurs when
all responses selected the predicted frame.
was 46.67%. Professionals selected our prediction in
38.89% of the examples. Figure 6a shows the dis-
tribution of the collected answers for the 540 exam-
ples. We appreciate that in 59 of the examples all 5
workers selected the frame predicted by our model in-
stead of the ground-truth frame (5 pred vs. 0 GT).
Figure 6b shows the relation between the accuracy
of AMT Workers and Creatives at selecting the GT
frame, reflecting a strong correlation between the cri-
teria of AMT Workers and Creative Professionals.
To further understand why Subjects clearly di-
verge from ground truth, we look into the images that
belong to each of the accuracy ratios. Figure 7 shows
a example of the images presented to the subjects for
each possible response that we obtained, hand-picked
to try to be representative of the group.
6 DISCUSSION
Accuracy tests show that our prediction model per-
forms significantly better than chance. There is room
for improvement, though: when we look into pairs
where Subjects always preferred the GT over the Pre-
dicted image (see Figure 7, top two rows) the reason
for Subjects to prefer the GT clearly seems that the
Predicted image is of poor quality or does not follow
the reference image as well as the GT image does.
Reference GT Prediction
Figure 7: Results of the human-judgement study. One ex-
ample shown for each possible outcome. Top is 0 predicted
vs 5 ground truth, below is 1 vs 4, until at the bottom which
shows an example of 5 predicted vs 0 ground truth
However, taken globally, subjective tests confirm
that when the Ground Truth and the Predicted image
do not match human subjects (or, at least, AMT Work-
ers) have an overall confusion rate of 47, 4%. The fact
that the majority preference is very close to this value
(46.67%) also suggests there is a quite wide consen-
sus on this fact (i.e., this ratio is not biased by one
rogue subject). It is also true that the Predicted im-
ages that AMT Workers choose instead of the Ground
Truth are significantly correlated with the preferences
of Creative Professionals (Figure 6b ). From this per-
spective, it would seem that for human subjects our
automated method cannot be distinguished from the
ground truth.
Further analysis, though, nuances this response,
and we believe the reason is because not all distractors
are created equal. If Subjects were not able to differ-
entiate between Ground Truth and Predicted images
for any example, most images would be in the cen-
tral bins in Figure 6a. In those cases the responses
of AWT Workers and of Creative Professionals match
the most. It also seems that in these cases the GT
and the Predicted image indeed are very similar (See
central rows in Figure 7). However, the distribution
across bins in Figure 6a is rather uniform. The highest
divergence in responses occurs in the leftmost bins,
Automated Video Edition for Synchronized Mobile Recordings of Concerts
947

where Creative Professionals select the GT more of-
ten than AMT Workers. The examples in the two bot-
tom rows of Figure 7) suggest that AMT Workers di-
verge from GT based on consistency of color or im-
age composition. And overall, the global responses of
Creative Professionals are biased towards the Ground
Truth (38.89% versus 47, 4%). We believe these two
discrepancies can be best explained due to a differ-
ence in criterion, for particular cases: in examples
when one of the two options shows a similar cam-
era angle and content as the reference image AMT
Workers tend to select it, while Creative Professionals
usually choose the one that provides more diversity of
shots.
Further work exploring automatic viewpoint anal-
ysis should be done to clarify this possibility, and use
it to improve the next-shot prediction module. Fur-
ther work should also explore whether the combina-
tion of the shot-duration and the next-shot prediction
produces results that are more or less consistent with
subjective preferences. Further directions to explore
are to take advantage of features from the audio for
both modules, as well as to enrich the shot selection
process.
In conclusion, subjective and objective metrics
provide evidence that our next-shot prediction mod-
ule performs reasonable predictions, quite consistent
with the criteria of both AMT Workers and Creative
Professionals. We also showed that the accuracy met-
ric alone is not reliable, subjective metrics must also
be considered.
REFERENCES
Arev, I., Park, H. S., Sheikh, Y., Hodgins, J., and Shamir,
A. (2014). Automatic editing of footage from multi-
ple social cameras. ACM Transactions on Graphics
(TOG), 33(4):1–11.
Berthouzoz, F., Li, W., and Agrawala, M. (2012). Tools for
placing cuts and transitions in interview video. ACM
Transactions on Graphics (TOG), 31(4):1–8.
Chen, J., Meng, L., and Little, J. J. (2018). Camera se-
lection for broadcasting soccer games. In 2018 IEEE
Winter Conference on Applications of Computer Vi-
sion (WACV), pages 427–435. IEEE.
Chollet, F. (2017). Xception: Deep learning with depthwise
separable convolutions. In Proceedings of the IEEE
conference on computer vision and pattern recogni-
tion, pages 1251–1258.
Fried, O., Tewari, A., Zollh
¨
ofer, M., Finkelstein, A.,
Shechtman, E., Goldman, D. B., Genova, K., Jin, Z.,
Theobalt, C., and Agrawala, M. (2019). Text-based
editing of talking-head video. ACM Transactions on
Graphics (TOG), 38(4):1–14.
G
´
omez, L., Biten, A. F., Tito, R., Mafla, A., Rusi
˜
nol, M.,
Valveny, E., and Karatzas, D. (2020). Multimodal grid
features and cell pointers for scene text visual question
answering. arXiv preprint arXiv:2006.00923.
Gulcehre, C., Ahn, S., Nallapati, R., Zhou, B., and Bengio,
Y. (2016). Pointing the unknown words. In Proceed-
ings of the 54th Annual Meeting of the Association for
Computational Linguistics (Volume 1: Long Papers),
pages 140–149.
He, K., Zhang, X., Ren, S., and Sun, J. (2016). Deep resid-
ual learning for image recognition. In Proceedings of
the IEEE conference on computer vision and pattern
recognition, pages 770–778.
Laiola Guimaraes, R., Cesar, P., Bulterman, D. C., Zsom-
bori, V., and Kegel, I. (2011). Creating personalized
memories from social events: community-based sup-
port for multi-camera recordings of school concerts.
In Proceedings of the 19th ACM international confer-
ence on Multimedia, pages 303–312.
Leake, M., Davis, A., Truong, A., and Agrawala, M.
(2017). Computational video editing for dialogue-
driven scenes. ACM Trans. Graph., 36(4):130–1.
Liao, Z., Yu, Y., Gong, B., and Cheng, L. (2015). Au-
deosynth: music-driven video montage. ACM Trans-
actions on Graphics (TOG), 34(4):1–10.
See, A., Liu, P. J., and Manning, C. D. (2017). Get to
the point: Summarization with pointer-generator net-
works. In Proceedings of the 55th Annual Meeting
of the Association for Computational Linguistics (Vol-
ume 1: Long Papers), pages 1073–1083.
Shrestha, P., de With, P. H., Weda, H., Barbieri, M., and
Aarts, E. H. (2010). Automatic mashup generation
from multiple-camera concert recordings. In Pro-
ceedings of the 18th ACM international conference on
Multimedia, pages 541–550.
Singh, A., Natarajan, V., Shah, M., Jiang, Y., Chen, X.,
Batra, D., Parikh, D., and Rohrbach, M. (2019). To-
wards vqa models that can read. In Proceedings of the
IEEE/CVF Conference on Computer Vision and Pat-
tern Recognition, pages 8317–8326.
Truong, A., Berthouzoz, F., Li, W., and Agrawala, M.
(2016). Quickcut: An interactive tool for editing nar-
rated video. In Proceedings of the 29th Annual Sym-
posium on User Interface Software and Technology,
pages 497–507.
Vinyals, O., Fortunato, M., and Jaitly, N. (2015). Pointer
networks. arXiv preprint arXiv:1506.03134.
Wang, M., Yang, G.-W., Hu, S.-M., Yau, S.-T., and
Shamir, A. (2019). Write-a-video: computational
video montage from themed text. ACM Trans. Graph.,
38(6):177–1.
Wu, H.-Y. and Christie, M. (2015). Stylistic patterns for
generating cinematographic sequences. In 4th Work-
shop on Intelligent Cinematography and Editing Co-
Located w/Eurographics 2015.
Wu, H.-Y. and Jhala, A. (2018). A joint attention model for
automated editing. In INT/WICED@ AIIDE.
Zhou, B., Lapedriza, A., Khosla, A., Oliva, A., and Tor-
ralba, A. (2017). Places: A 10 million image database
for scene recognition. IEEE Transactions on Pattern
Analysis and Machine Intelligence.
VISAPP 2022 - 17th International Conference on Computer Vision Theory and Applications
948
