
Adversarial Evasion Attacks to Deep Neural Networks in ECR Models
Shota Nemoto
1
, Subhash Rajapaksha
2
and Despoina Perouli
2
1
Case Western Reserve University, 10900 Euclid Avenue, Cleveland, Ohio, U.S.A.
2
Marquette University, 1250 West Wisconsin Avenue, Milwaukee, Wisconsin, U.S.A.
Keywords:
Neural Networks, Adversarial Examples, Evasion Attacks, Security, Electrocardiogram, ECR.
Abstract:
Evasion attacks produce adversarial examples by adding human imperceptible perturbations and causing a
machine learning model to label the input incorrectly. These black box attacks do not require knowledge of
the internal workings of the model or access to inputs. Although such adversarial attacks have been shown to
be successful in image classification problems, they have not been adequately explored in health care models.
In this paper, we produce adversarial examples based on successful algorithms in the literature and attack a
deep neural network that classifies heart rhythms in electrocardiograms (ECGs). Several batches of adversarial
examples were produced, with each batch having a different limit on the number of queries. The adversarial
ECGs with the median distance to their original counterparts were found to have slight but noticeable per-
turbations when compared side-by-side with the original. However, the adversarial ECGs with the minimum
distance in the batches were practically indistinguishable from the originals.
1 INTRODUCTION
Machine learning and neural networks in particu-
lar are capable of approximating complex functions,
which allows them to accomplish traditionally diffi-
cult tasks in fields such as natural language process-
ing and computer vision. Additional advances such
as the rectified linear activation function and residual
networks allow much deeper and more complex net-
works to be trained by helping to avoid the problem
of vanishing gradients and slow training processes.
In healthcare, neural networks could be used to di-
agnose diseases in patients bringing more automation
in checkups. Ideally, they can help save time while re-
ducing monetary costs related to the number of med-
ical personnel required to examine test results.
Before widespread use of machine learning tech-
niques in healthcare, security concerns must be ad-
dressed as a number of sophisticated attacks on neural
networks are being produced. For example, dataset
poisoning refers to attacks where an adversary tam-
pers with the training dataset in order to compromise
the final model’s performance or even add a “back-
door” into a network (Yao et al., 2019). The back-
door is a trigger that forces the network to always
make a certain decision when it is present. How-
ever, these attacks require the adversary to have ac-
cess to the training data of the model. In terms of pri-
vacy, certain attacks can attempt to obtain data from
the training set using the model’s output predictions,
or infer a particular property about the entire train-
ing set. These attacks are known as model inversion
attacks (Yang et al., 2019). Finally, more practical
attacks can take a correctly classified input and add
human imperceptible perturbations that alter the la-
bel the model ends up applying to the input. These
attacks are known as evasion attacks and the inputs
with imperceptible perturbations added are known as
adversarial examples.
The practicality of evasion attacks comes from re-
cent studies on adversarial examples which demon-
strate that it is possible to perform a black-box attack
on neural networks. This means that no tampering
needs to be done to the training data, and no informa-
tion about the training data is necessary at all. The ad-
versary also does not need to know the internals of the
model’s architecture, such as how many layers there
are, if there are pooling convolutional layers, if there
are residual blocks, etc. Black-box attacks only re-
quire the final output scores of the model or the final
decision that was made.
In this paper, we examine whether a black-box
evasion attack could successfully create an adversar-
ial example to a neural network intended for use in
healthcare. The evasion attack algorithm is Hop-
SkipJumpAttack (Chen et al., 2020) and the chosen
Nemoto, S., Rajapaksha, S. and Perouli, D.
Adversarial Evasion Attacks to Deep Neural Networks in ECR Models.
DOI: 10.5220/0010848700003123
In Proceedings of the 15th International Joint Conference on Biomedical Engineering Systems and Technologies (BIOSTEC 2022) - Volume 5: HEALTHINF, pages 135-141
ISBN: 978-989-758-552-4; ISSN: 2184-4305
Copyright
c
2022 by SCITEPRESS – Science and Technology Publications, Lda. All rights reserved
135

network to be attacked is a deep neural network de-
signed to classify heart rhythms using electrocardio-
grams (Hannun et al., 2019).
2 RELATED WORK
Adversarial examples, initially introduced in the con-
text of computer vision, are images or other input vec-
tors containing perturbations that alter the label as-
signed to them by a target classifier from their true
label. These perturbations do not alter a human’s
original classification of the image and are often con-
sidered imperceptible. Introduced in 2014 (Szegedy
et al., 2014), a number of different methods for creat-
ing adversarial examples have arisen in recent years.
The original attack used the L-BFGS optimization
method to minimize a cost function. This cost func-
tion represents the distance of the adversarial example
to the original input vector and if its outputted label
differs from the true label. The L-BFGS optimization
method requires the ability to calculate the gradient
of the cost function, or how much the cost function
changes with respect to each element of the input vec-
tor. An advantage of the L-BFGS method is that it
does not require calculations of the second derivative,
or the Hessian matrix, of the cost function. Methods
like this are known as quasi-Newton methods and can
save a large number of calculations.
A second, faster attack known as the Fast Gra-
dient Sign Method was introduced the following
year (Goodfellow et al., 2015). It only used the sign
from the gradient and a chosen step size to update
the adversarial image. These first adversarial exam-
ples are known as white-box attacks and require full
knowledge of the internal workings of the network.
The practicality of these attacks is limited since they
require knowledge of the derivative of the cost func-
tion with respect to each input and thus full knowl-
edge of the network architecture.
The core issue that research on black-box attacks
addresses is the estimation of a network’s gradient
from only the input and output vectors. One of the
first black-box attacks (Papernot et al., 2017), where
the adversary has no knowledge of the internals of the
network, creates a substitute network using a training
set of images labelled by the target network. Then,
white-box adversarial attacks are used to generate ad-
versarial examples on the substitute network. These
examples have been found to be capable of fooling
the target network, thus proving the viability of trans-
fer attacks.
Another black-box adversarial attack relies on the
scores or probabilities the model assigns to the input
image. The attack (Narodytska and Kasiviswanathan,
2017) uses the scores to numerically approximate the
gradient of the network, then finds a subset of pixels
to perturb in order to place the adversarial example in
one of the network’s “blind spots”. However, this can
also be thought of as a partial knowledge attack, since
the adversary may not always get access to the full list
of probabilities and scores for inputs, but only to the
final decision.
A more recent class of attacks are decision-based
adversarial attacks, which rely solely on the final out-
put or the highest probability labels predicted by the
classifier. These are the most practical attacks, as
most publicly available classifiers will only give users
a single, final decision. One decision-based attack
known as Boundary Attack (Brendel et al., 2018)
starts with a large adversarial perturbation. This per-
turbation is then minimized while still remaining ad-
versarial, essentially estimating the location of the
boundary between an adversarial input and a correctly
labelled input, then finding the closest point on that
boundary to the original image.
Building off of Boundary Attack, Chen et al.
(Chen et al., 2020) introduced an improvement to
boundary attack that uses a new technique to esti-
mate the gradient and requires fewer queries to the
model. This attack was named Boundary Attack++
or HopSkipJumpAttack. A reduction in the number
of queries is important as publicly available models
may have some cost associated with each query, such
as a time or monetary cost. Thus, practical evasion
attacks in the future will likely need to reduce the re-
quired number of queries as much as possible or else
they reduce their probability of success.
Another aspect of these evasion attacks is that they
have all mostly been tested in the computer vision
field. Very little research on evasion attacks has at-
tempted to attack models unrelated to image recogni-
tion. One study (Zhao et al., 2019) applied adversarial
examples to object recognition and found that, while
the attack was successful, object detectors posed an
extra challenge. Object detectors had to accomplish
two tasks: predicting the existence of an object as
well as the label of the object. Their inputs were
also typically video feeds instead of image vectors,
so constantly changing backgrounds, distances, view-
ing angles, and illumination added to the difficulty of
creating adversarial examples. This seems to imply
that it may not be a given that all neural networks
are vulnerable to evasion attacks. It is possible that
some applications of neural networks may be natu-
rally more robust to adversarial examples. This paper
seeks to investigate whether ECG models are vulner-
able to evasion attacks.
HEALTHINF 2022 - 15th International Conference on Health Informatics
136

3 HOP SKIP JUMP ATTACK
Our goal is to implement an evasion attack algorithm
called HopSkipJumpAttack (Chen et al., 2020) and
apply it to a deep neural network developed to classify
electrocardiograms. We then evaluate the success of
the resulting adversarial examples by measuring their
distances to the original electrocardiograms. In this
section we summarize the HopSkipJumpAttack algo-
rithm (Chen et al., 2020).
HopSkipJumpAttack focuses on being query ef-
ficient, as accessing publicly available models might
have some cost associated with each query. The cost
could be monetary, time, risk of arousing suspicion,
etc. At its core, HopSkipJumpAttack follows the ma-
jor steps listed below and illustrated in Figure 1.
1. An adversarial example is initialized using a sam-
ple image from the target class. The class must be
different from the original, else the solution will
be trivial.
2. The boundary between adversarial images and
correctly classified images is then estimated using
binary search on a spectrum of blended images of
the original and current adversarial images.
3. The gradient at the boundary is estimated using a
weighted sum of random perturbations.
4. A step size for the current iteration is calculated,
and a perturbation is added to the current adver-
sarial example using the estimated gradient direc-
tion and the step size.
5. The process is repeated using the current adver-
sarial example in the binary search.
Figure 1: Visualization of Hop Skip Jump Attack in a 2D
space as shown in (Chen et al., 2020). The blue region is
the space where an image is given the adversarial label by
the classifier. The red region is where an image is given
any non-adversarial label. The first image shows a bound-
ary search between the current adversarial example and the
original image. The second image shows the gradient esti-
mate at the boundary. The third image shows an appropri-
ate step size being calculated. The fourth image shows the
boundary search for the next iteration.
Throughout HopSkipJumpAttack, an indicator
function is used. This indicator function will take an
input image, then output 1 if the adversary’s desired
outcome is achieved and 0 otherwise. If the attack is
untargeted, the desired outcome is for the image to be
classified as any class other than the correct one. If
the attack is targeted, the desired outcome is for the
image to be classified as the target class.
Estimating the boundary uses two images, one that
is classified as the target class and the original image.
Blending these, a spectrum between the two is cre-
ated, where images have varying proportions of the
adversarial and original image specified by a param-
eter α ∈ [0, 1]. When using L
2
distance, the images
on the spectrum can be created using the following
equation:
αx
∗
+ (1 −α)x (1)
The equation can be thought of as projecting a
point x onto a sphere of radius α centered at x
∗
. In
this case, x and x
∗
are input vectors to a neural net-
work.
A region on this spectrum is classified as the origi-
nal class, and a region on this spectrum is classified as
the target class. The boundary between these two re-
gions is estimated using binary search. The boundary
image is taken as the current adversarial image.
At the boundary, a batch of random unit vectors
is sampled. These unit vectors are individually added
to the adversarial image creating new adversarial im-
ages. Then, an indicator function is evaluated for each
of these perturbed images. The size of these ran-
dom perturbations is a function of the dimension of
the space and the distance of the current image to the
original. The average of these indicator values is then
saved as the baseline value. A normalizing constant
proportional to the batch size is also calculated. For
each vector, a coefficient is calculated by subtracting
the baseline from their indicator value. This is done
in order to reduce the variance in the estimate. Then,
a weighted sum of the unit vectors is taken, with their
corresponding coefficients as their weighting. Finally,
the normalizing constant is applied.
The step size is designed to become smaller as
more iterations are completed in order to prevent
overshooting the minimum. It is also a function of the
distance of the current adversarial image to the origi-
nal image. However, if the calculated step size yields
a non- adversarial image, the step size is divided by
factors of 2 until it does produce an adversarial im-
age. The function to calculate the step size is shown
below:
ξ
t
=
||x
t
−x
∗
||
p
√
t
(2)
where p is the norm order (2 or infinite).
Adversarial Evasion Attacks to Deep Neural Networks in ECR Models
137

4 ELECTROCARDIODIAGRAM
MODEL
Electrocardiodiagrams (ECGs) are recordings of the
electrical signals in a person’s heart. They are used
to detect abnormal heart rhythms, known as arryth-
mias, in patients. Hannun et al (Hannun et al., 2019)
developed a deep neural network (DNN) for classify-
ing 10 different classes of arrythmias, normal sinus
rhythms, and noise from these ECGs. This model
achieved an area under the Receiver Operating Char-
acteristic (ROC) curve of 0.97 for all but one class,
and an area of 0.91 for the last class. The model
makes these classifications using only the raw ECG
data, and does not use any other patient information.
The model architecture consists of 16 residual blocks
with two convolutional layers per block. The resid-
ual blocks help speed up the training and optimization
process for such a deep network.
To demonstrate the generalizability of their net-
work, Hannun et al. applied their network to the
2017 PhysioNet Computing in Cardiology Challenge
dataset, which required classification of ECGs into
four different classes:
• Normal Sinus Rhythm
• Atrial Fibrillation
• Other
• Noisy
When applied to the PhysioNet public dataset,
the network had a class average F
1
score of 0.83,
which was among the best performers in the chal-
lenge. The F
1
score measures the test’s ac-
curacy by calculating the harmonic mean of its
precision (
numberO fCorrectlyLabelledPositives
totalNumberO f PositiveLabels
) and recall
(
numberO fCorrectlyLabelledPositives
totalNumberO f TruePositiveElements
).
5 METHODS
We replicated the DNN model for identifying arryth-
mias in ECGs (Hannun et al., 2019) and applied the
HopSkipJumpAttack (Chen et al., 2020) to it. The
code for the DNN was pulled from the corresponding
repository (https://github.com/awni/ecg), and the
dataset of ECGs used for training and evaluation
of the DNN were pulled from the PhysioNet 2017
website (https://physionet.org/content/challenge-
2017/1.0.0/). The model being attacked had about
91% accuracy. To keep the environment consis-
tent with the environment used for the DNN, the
HopSkipJumpAttack was implemented in Python
2.7 on a Linux system (Ubuntu 18.04 on Windows
Subsystem for Linux 2). The distance metric used for
this paper was the Euclidean norm, or L
2
norm. The
initial batch size was chosen to be 100 random unit
vectors, generated by sampling a uniform random
distribution using the NumPy library. The attack
algorithm was also implemented to halt and return
the current adversarial ECG, if the model query limit
would be exceeded during an iteration.
ECGs for the original and target sample in
the HopSkipJumpAttack algorithm were chosen uni-
formly randomly from the PhysioNet dataset, and se-
lected so that they would have differing labels as-
signed to them by the DNN. Original and Target pairs
were chosen in batches of approximately 100, with
each batch having a different query limit. The cho-
sen query limits were 2500, 5000, 10000, and 15000
queries.
6 RESULTS
The distances of the produced adversarial examples to
their original counterpart ECGs are shown in Table 1.
The trend of distances as the number of queries used
increases is shown in Figure 2.
Table 1: L
2
Distances of Adversarial Examples.
Queries Sample Size Mean Median Min
2500 88 53.3 42.8 6.4
5000 97 53.3 40.0 5.5
10000 19 43.9 24.0 3.8
15000 92 27.0 19.7 1.7
Figure 2: L
2
distances between adversarial examples and
original ECGs as a function of model queries. The bottom
blue line plots the median distances of each batch. The top
orange line plots the mean distances of each batch.
The minimum distance examples produced appear
to be practically indistinguishable with the human eye
as shown in Figures 3 and 4. The L
2
distance be-
tween the original and adversarial ECG is less than
10. The median examples in the batches that used
HEALTHINF 2022 - 15th International Conference on Health Informatics
138
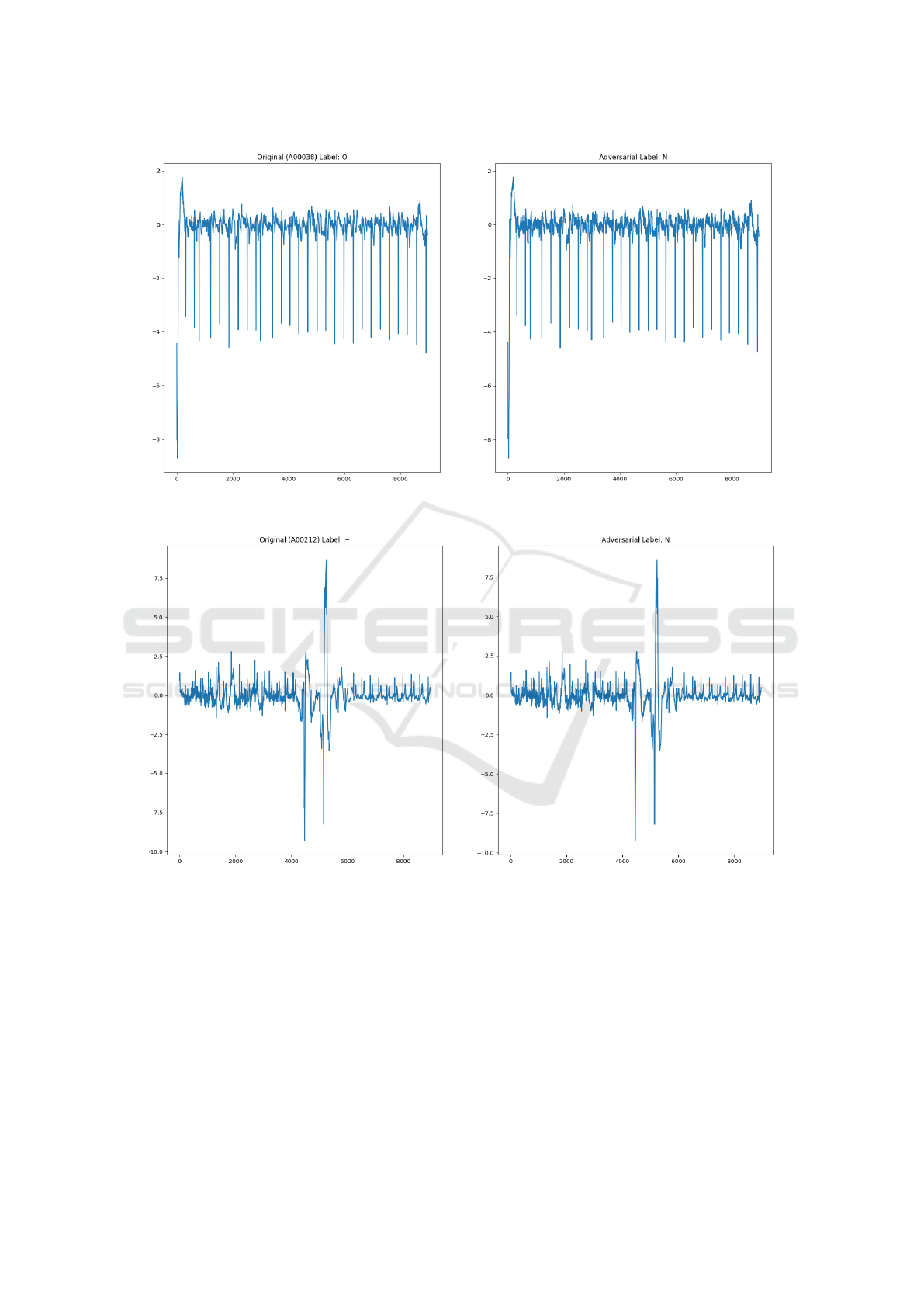
Figure 3: Minimum distance adversarial example for 10000 queries. The original ECG on the left was labeled as “Other
Arrhythmia”. The adversarial ECG on the right was labeled as “Normal Sinus Rhythm”.
Figure 4: Minimum distance adversarial example for 15000 queries. The original ECG on the left was labeled as “Too Noisy”.
The adversarial ECG on the right was labeled as “Normal Sinus Rhythm”.
2500 and 5000 queries have some noticeable pertur-
bations when compared side-by-side as shown in Fig-
ures 3 and 4. In the median cases for the 10000 and
15000 query batches, the noise could be written off as
simple noise, and would likely not be easily notice-
able unless compared while directly adjacent.
7 CONCLUSION
If no defenses against adversarial attacks are utilized
and a model is made publicly available so that making
thousands of queries is possible, an evasion attack will
be able create an adversarial ECG indistinguishable
from an original ECG by a human eye. As for the ad-
versarial examples with L
2
distances greater than 10,
it is uncertain if they would be able to go unnoticed if
not compared side-by-side with the original. The total
Adversarial Evasion Attacks to Deep Neural Networks in ECR Models
139
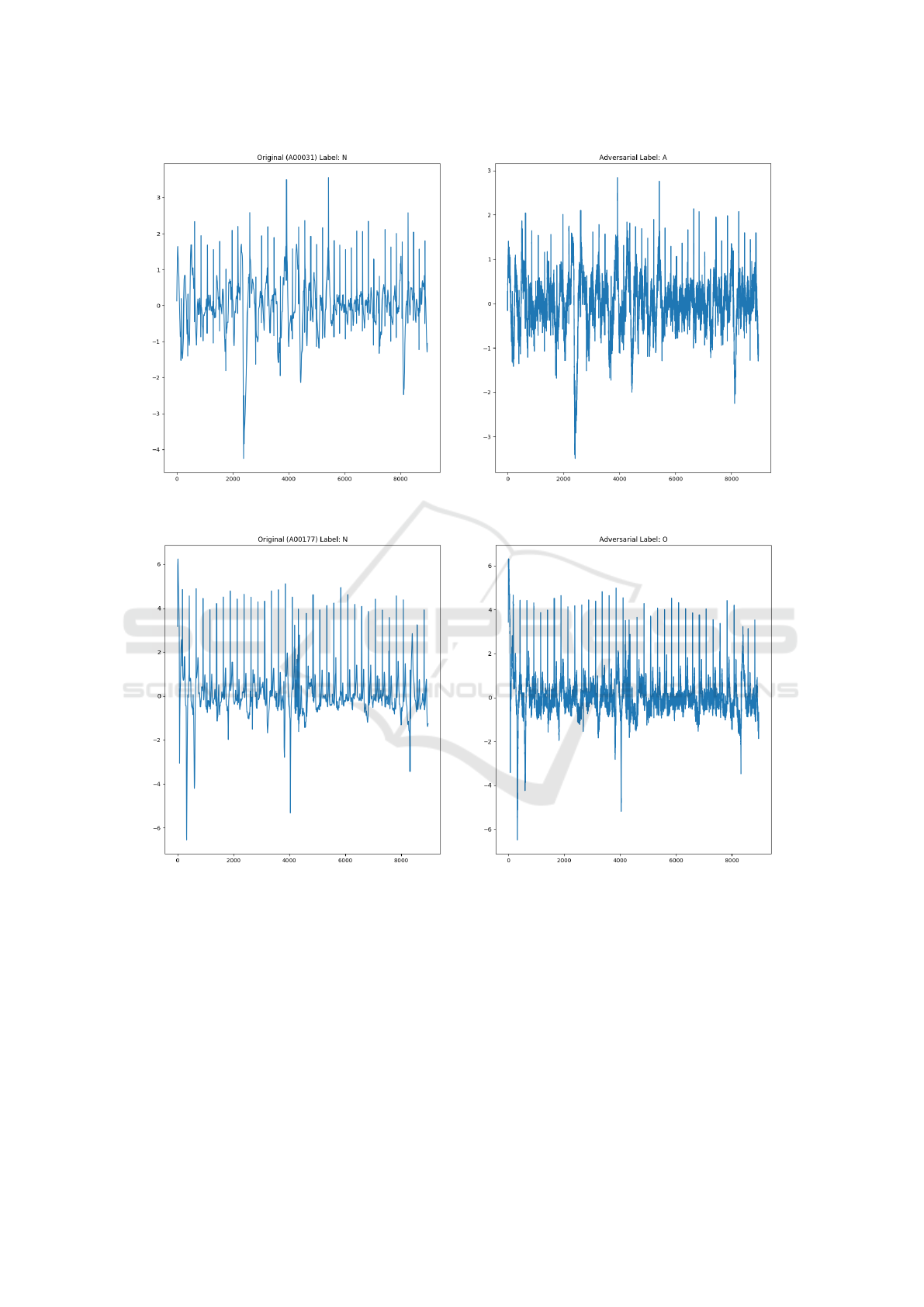
Figure 5: Median distance adversarial example for 10000 queries. The original ECG on the left was labeled as “Normal Sinus
Rhythm”. The adversarial ECG on the right was labeled as “Atrial Fibrillation”.
Figure 6: Median distance adversarial example for 15000 queries. The original ECG on the left was labeled as “Normal Sinus
Rhythm”. The adversarial ECG on the right was labeled as “Other Arrhythmia”.
results indicate that healthcare models can be vulner-
able to evasion attacks. Thus, even if neural networks
used in healthcare manage to obtain accuracy, preci-
sion, and recall greater than 0.99, they should not be
taken as a complete replacement for an opinion from
a medical professional until adequate defenses against
adversarial attacks, such as evasion attacks, are imple-
mented.
A possible method for defending against evasion
attacks would be monitoring or controlling access
to the model. HopSkipJumpAttack is very efficient
in number of queries, but the experiments run by
Chen et al (Chen et al., 2020) show that their at-
tacks against most models required upwards of one
thousand queries to generate a single adversarial ex-
ample. Policies that control access to the model
could perhaps require some patient identification and
limit the frequency of queries per patient or possibly
add a monetary requirement. However, such poli-
cies should not become so prohibitive such that pa-
tients in need are unable to access the model, as that
would defeat the original purpose of making access to
HEALTHINF 2022 - 15th International Conference on Health Informatics
140

an expert-level diagnosis widely available. This be-
comes a much larger concern if a monetary require-
ment is added.
8 FUTURE WORK
It will be helpful to consult a panel of expert cardi-
ologists to evaluate the success of these attacks and
determine if they would be noticed by professionals.
Additionally, it may be possible that certain classes of
arrhythmias are easier to target and create adversar-
ial examples of. In the same vein, certain samples of
a target class may serve as a better target sample to
initialize the HopSkipJumpAttack algorithm with.
It is also worth investigating possible defenses
against black-box evasion attacks. One option would
be to add the correctly labelled adversarial examples
to the training set in order to reduce the sensitivity
of the model to these perturbations. A second option
would be to limit the number of model queries per-
mitted per user; even though HopSkipJumpAttack is
a query-efficient algorithm, generating human imper-
ceptible adversarial examples still requires thousands
of queries. Defense mechanisms should take into ac-
count that malicious actors could use multiple user
accounts to gain access to bypass protections.
Finally, adversarial attacks such as Hop-
SkipJumpAttack should be applied to more models
in healthcare.
ACKNOWLEDGEMENTS
Thanks to Dr. Debbie Perouli for guiding and serving
as the mentor for this project. Additional thanks to Dr.
Praveen Madiraju and Dr. Dennis Brylow for running
the Research Experience for Undergraduates program
at Marquette University.
This material is based upon work supported by the
National Science Foundation under Grant #1950826.
REFERENCES
Brendel, W., Rauber, J., and Bethge, M. (2018). Decision-
based adversarial attacks: Reliable attacks against
black-box machine learning models.
Chen, J., Jordan, M. I., and Wainwright, M. J. (2020). Hop-
skipjumpattack: A query-efficient decision-based at-
tack.
Goodfellow, I. J., Shlens, J., and Szegedy, C. (2015). Ex-
plaining and harnessing adversarial examples.
Hannun, A. Y., Rajpurkar, P., Haghpanahi, M., Tison, G. H.,
Bourn, C., Turakhia, M. P., and Ng, A. Y. (2019).
Cardiologist-level arrhythmia detection and classifi-
cation in ambulatory electrocardiograms using a deep
neural network. Nature medicine, 25(1):65–69.
Narodytska, N. and Kasiviswanathan, S. (2017). Sim-
ple black-box adversarial attacks on deep neural net-
works. In 2017 IEEE Conference on Computer Vision
and Pattern Recognition Workshops (CVPRW), pages
1310–1318.
Papernot, N., McDaniel, P., Goodfellow, I., Jha, S., Celik,
Z. B., and Swami, A. (2017). Practical black-box at-
tacks against machine learning.
Szegedy, C., Zaremba, W., Sutskever, I., Bruna, J., Erhan,
D., Goodfellow, I., and Fergus, R. (2014). Intriguing
properties of neural networks.
Yang, Z., Zhang, J., Chang, E.-C., and Liang, Z. (2019).
Neural network inversion in adversarial setting via
background knowledge alignment. In Proceedings of
the 2019 ACM SIGSAC Conference on Computer and
Communications Security, CCS ’19, page 225–240,
New York, NY, USA. Association for Computing Ma-
chinery.
Yao, Y., Li, H., Zheng, H., and Zhao, B. Y. (2019). La-
tent backdoor attacks on deep neural networks. In
Proceedings of the 2019 ACM SIGSAC Conference on
Computer and Communications Security, CCS ’19,
page 2041–2055, New York, NY, USA. Association
for Computing Machinery.
Zhao, Y., Zhu, H., Liang, R., Shen, Q., Zhang, S., and Chen,
K. (2019). Seeing isn’t believing: Towards more ro-
bust adversarial attack against real world object detec-
tors. In Proceedings of the 2019 ACM SIGSAC Con-
ference on Computer and Communications Security,
CCS ’19, page 1989–2004, New York, NY, USA. As-
sociation for Computing Machinery.
Adversarial Evasion Attacks to Deep Neural Networks in ECR Models
141
