
Research on E-Commerce Human Resource Innovation Management
in the Era of Big Data
Xiaoyi Yuan and Yu Chen
Chongqing College of Architecture and Technology, Chongqing, China
Keywords: Big Data Technology, E-Commerce Human Resource Management, Innovation.
Abstract: Through the use of big data mining technology, big data analysis technology, cloud computing technology
and Web technology, combined with the problems of e-commerce human resources management to build e-
commerce human resources innovation management system. The system has the function modules of updating
traditional concepts, improving human management and deepening data management. It not only
comprehensively optimizes the human resource management system, but also reflects the performance of big
data related technologies incisively and vividly. In addition, it also solves the problems existing in the
traditional e-commerce human resource management, realizes the intelligent management of e-commerce
human resource, and provides a strong support for the further development of e-commerce human resource
management.
1 INTRODUCTION
In the era of big data, e-commerce related industries
are expanding on a large scale, showing the following
phenomena: The total number of employees of
enterprises keeps increasing, while the number of
human resource management departments does not
increase, which is easy to form the contradiction
between the increase of workload and the control cost
of human resources; At present, most of the
employees in the enterprise belong to the post-90s
age group. There is a huge gap between the career
outlook and values of the post-90s employees and the
concept of the previous employees, and the high
turnover of employees, which increases the workload
of human resource management and also brings
challenges to human resource management. At
present, enterprises generally require college degree
or above, and the comprehensive quality of
employees should also be listed in the recruitment
requirements. For example, employees should not
only know the relevant knowledge of the company's
business, but also have the professional technology of
the post. The author thinks that by using big data
technology to construct the electronic commerce
application data platform, to solve the traditional
electronic commerce above problems existing in
human resource management, staff in a timely
manner to change ideas, into the new management
mode, and then predict the employee situation and
make decisions in time, in addition, both reach the
purpose of saving resources, and realize the effective
implementation of management.
2 OVERVIEW OF E-COMMERCE
HUMAN RESOURCE
MANAGEMENT
2.1 Contents of E-Commerce Human
Resource Management
Human resources refers to doing work by
communicating with people. It requires managers to
have the ability of coordination, integration,
judgment and imagination. Human resource
management refers to the management of internal and
external human resources of an enterprise through
recruitment, screening, training and other forms, so as
to meet the current and future development needs and
maximize the function of human resource
management while ensuring the completion of the
target. It can be divided into six parts, human resource
planning, recruitment and allocation, training and
development, performance management,
906
Yuan, X. and Chen, Y.
Research on E-Commerce Human Resource Innovation Management in the Era of Big Data.
DOI: 10.5220/0011357700003440
In Proceedings of the International Conference on Big Data Economy and Digital Management (BDEDM 2022), pages 906-911
ISBN: 978-989-758-593-7
Copyright
c
2022 by SCITEPRESS – Science and Technology Publications, Lda. All rights reserved

compensation and welfare management and labor
relations management. However, there are some
problems in traditional manpower management, such
as old concept, old model and poor forecast.
2.2 Problems in E-Commerce Human
Resource Management
2.2.1 Outdated Concepts and High Costs
According to the survey, 22 percent of e-commerce
executives have some knowledge of big data and e-
commerce, 20 percent say they have heard of it, and
the rest are in a state of never heard of it. It can be
seen that the concept of human resource management
in e-commerce is still at the beginning, and the
emergence of new technologies is not understood.
Electronic commerce cost of human resource
management involves the acquisition, development
and utilization of human resources, departure and
safeguard the basic rights and interests of investment,
because with the development of the enterprise,
number of employees are on the increase, causing the
rise in the cost of human resource management, such
as the human resources department in obtaining a
large number of personnel information, to produce
recruitment costs, investigation cost. In a word, in the
era of big data, the concept of human resource
management has not been updated with the changing
times, and the cost is high.
2.2.2 Obsolete Mode and Difficult
Management
Electronic commerce human resource management
model obsolete, resulting in the implementation of
management work more difficult. For example, the
technical system of an e-commerce website is an
internal software system. In terms of human resource
management, the website has internal training and
recruitment, but there is no efficient information
management system. The outdated human resource
management mode makes it difficult for the human
resources department to evaluate the quality and
performance of employees and manage them
effectively from a comprehensive perspective.
(
Wang, 2016
)
2.2.3 Lack of Prediction and
Recruitment Difficulties
According to the survey, although an e-commerce
website has a set of its own platforms, such as
recruitment and training, the platform can only carry
out general statistical analysis, and there are still
deficiencies in intelligent recommendatory,
forecasting the trend of enterprise talent, predicting
the development curve of employees in the
enterprise, and the turnover tendency of potential
employees. This makes it difficult for enterprises to
forecast comprehensively and recruit people. (
Wang,
2017
)
To sum up, e-commerce human resource
management has the above three problems, which
need to be solved by big data technology, so as to
exert the functions of e-commerce human resource
management to the utmost.
3 BIG DATA TECHNOLOGY
According to the latest authoritative statistics, by
2021, the global big data market has reached 80
billion US dollars, with an average annual growth rate
of 15.37%. In the last two years, the development
trend of China's big data industry has been on the rise,
and with the strong support of national policies and
continuous capital investment, the scale of big data
will continue to grow in the next few years, but its
growth trend will gradually slow down.
Big data refers to massive amounts of data.
Specifically, big data refers to the use of conventional
tools to capture, manage and process data sets,
requiring efficient modes to process data sets. There
are many kinds of big data technologies, which are
mainly divided into five parts: data acquisition and
preprocessing, data storage, data cleaning, data
analysis and query, and data visualization. (3) The
framework diagram of basic big data processing
technology is shown in Figure 1.
The significance of big data lies in data mining
valuable data information and predictions. First, data
mines valuable data information. Big data is not only
the storage and processing of massive data, but also
the data mining. For many enterprises, using big data
technology to mine the potential value in data is the
key to the core competitiveness of enterprises.
Second, prediction. Data itself is a summary and
summary of past and present data, which does not
provide directional guidance. However, a new
thinking model that can predict the future
development of an enterprise can be established by
understanding the way of thinking in the past. [4]
Research on E-Commerce Human Resource Innovation Management in the Era of Big Data
907
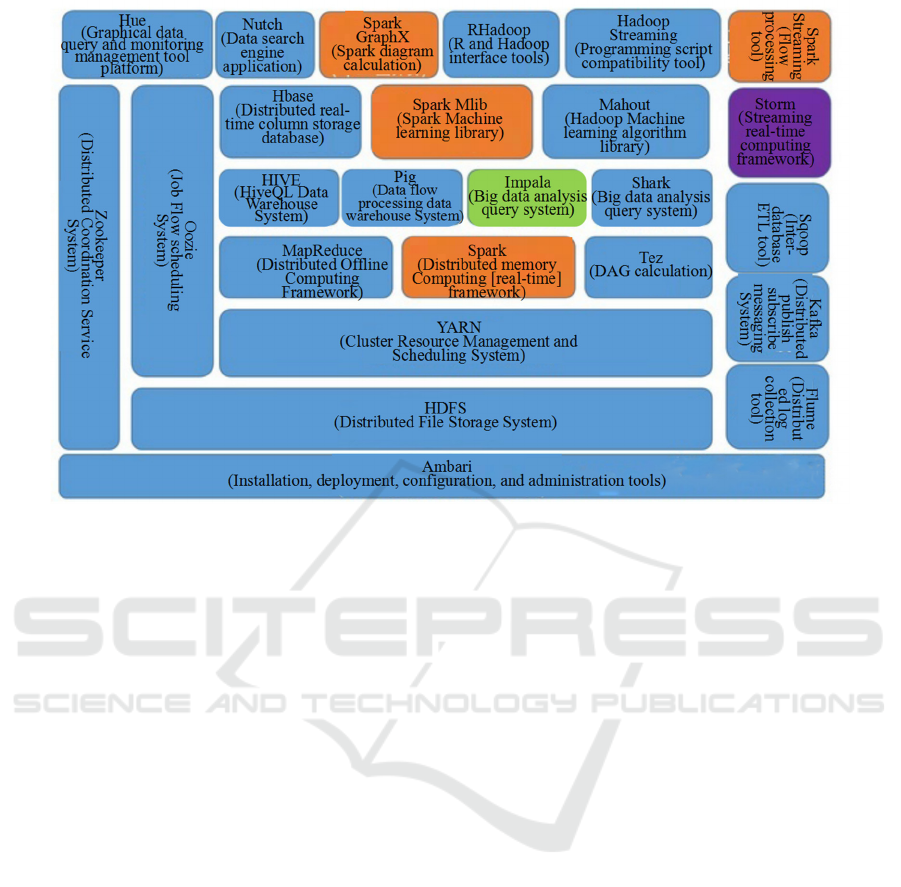
Figure 1: Basic technical framework of big data processing.
This paper focuses on data mining and analysis in
big data technology. The function of data mining
technology is to mine the development and potential
problems of employees in the enterprise. Data
analysis technology is to analyze the data, managers
make corresponding decisions. Big data technology
will be very thorough analysis of employee data
information, so as to realize the recruitment of
intelligent recommendation talents, online self-
service learning system, and then e-commerce human
resource management can achieve efficient allocation
of human resources, human cost control, intelligent
recruitment management and other goals.
4 DESIGN AND
IMPLEMENTATION
4.1 Overall Architecture Design
The specific management processes involved in e-
commerce human resource management include
recruitment management, training management,
performance management, compensation and welfare
management, guidance management and promotion
management. The author will take recruitment
management, training management and guidance
management as examples to build an e-commerce
application big data platform, as shown in Figure 2.
The platform is built by using Web technology, big
data technology and cloud computing. Users through
the site and use the network to the platform, through
the transition before the old ideas, set up new concept,
with the time development by deepening data
management, improve human resources management
to achieve effective decisions, in the process need to
be applied to the big data base technology to realize
data management and decision-making, using cloud
computing technology to realize the custom design of
platform function module, through the use of barrage
technology to achieve specific functions. The
platform consists of e-commerce application of big
data processes and human resource management
involved in the content. The setting of the platform is
not only conducive to the efficient management of
employees by the human resources department, but
also conducive to the overall development of the
enterprise planning.
BDEDM 2022 - The International Conference on Big Data Economy and Digital Management
908
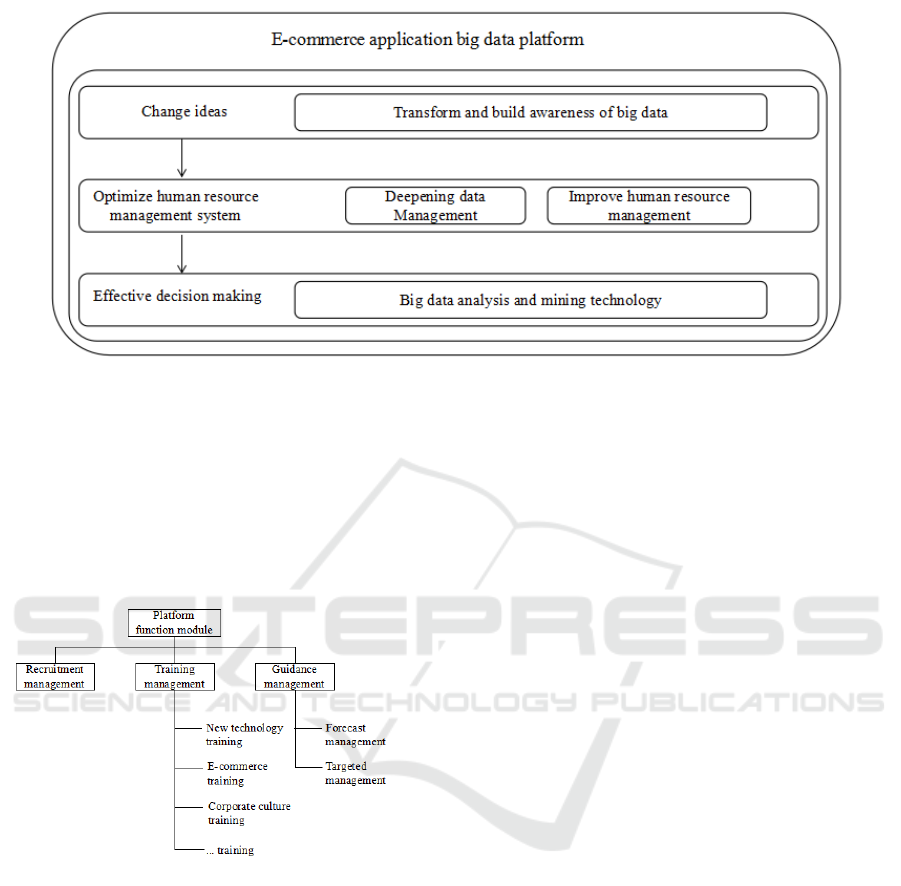
Figure 2: E-commerce application big data platform.
4.2 Detailed Functional Design
This part focuses on the introduction of methods and
technologies applied to recruitment management,
training management and guidance management in e-
commerce application big data platform. The specific
functional modules are shown in Figure 3.
Figure 3: Platform functional modules.
4.2.1 Recruitment Management
Hiring is more three-dimensional. The big data tool
Flume is used to collect the data of candidates in the
network, and Sqoop and HDFS are used to transmit
and store the data. Mapreduce and Spark are used to
calculate and clean the data. Hive tools are used to
analyze and query the analyzed data, and then use
specific formulas to calculate the job expectation and
the quality of candidates. Finally got the job
expectations and post match Numbers, again through
the matching degree of the intelligent screening, you
just need to make an appointment with the matching
degree is high talent, it saves in the recruitment
resume filtering, online first try, so as to improve the
recruitment efficiency, reduce the cost of hiring,
further enhance the efficiency and effectiveness of
the decision.
4.2.2 Training Management
Training management involves new technology
training, e-commerce knowledge training, enterprise
culture training and so on. After entering the training
management module of the platform, users can learn
various trainings in the module. After learning,
employees have a certain understanding of e-
commerce business, new technology big data,
enterprise culture and so on.
The specific training in the module is divided into
zero basic knowledge introduction course, learning
and subdivision course, easy learning of question
bank and knowledge application course content. In
the first three parts of the course, the information to
be used is uploaded to the platform through network
technology, and the platform identifies the difficulty
of the content and divides the types according to the
subsequent procedures. This function not only
provides learning materials for employees, but also
deepens their understanding of corporate culture.
After learning the first three parts of the course, the
user enters the fourth part of the course, knowledge
application. This part is divided into three parts,
which are application case base, case explanation and
technical discussion. The information involved in this
part is also obtained through uploading, and the
technical discussion part uses the bullet screen
technology. The feature of this part is that even if
there is no application case and case explanation
study, the study of the technical discussion part will
Research on E-Commerce Human Resource Innovation Management in the Era of Big Data
909

also make users receive a lot of goods, such as special
knowledge point explanation. Through this part of
learning, users will have a more thorough
understanding of their knowledge in new technology
and e-commerce, and gradually understand the
unknown areas in the process of learning knowledge,
so that users can not only realize learning, but also
timely reflection.
During the training, you need to create a shared
database, upload resources to the platform using the
cloud computing technology, and form a collection of
different types of storage devices using functions
such as the distributed file system to implement cloud
storage. Including enterprise internal information
sharing and external information sharing.
Information sharing is responsible for cataloging,
publishing, storing and retrieving data. For example,
enterprise internal information sharing, the first
display is the data catalog, the specific content
includes department planning, technology sharing,
department training. After the information is
published, it is stored and users can query the content
they want to know through retrieval. Through
network data sharing, employees can have a better
understanding of the internal development of the
enterprise, and their own positioning is also very
clear, and the goal of common progress of employees.
(
Zong, 2012
)
After training, employees will enhance their
understanding of new technology and e-commerce,
and improve their knowledge application ability.
4.2.3 Guidance and Management
Guided management is the e-commerce human
resource managers after forecasting the employees,
and then combined with all aspects of the employees
to carry out targeted guidance, so as to achieve
accurate prediction, efficient decision-making goals,
and then to achieve efficient management. This part
is divided into two parts, one is the prediction part,
the other is the targeted guidance part.
Predictions. The forecast is divided into four
parts. First, database data analysis. Database data
analysis is to preprocess the original data. Flume is
used to collect original data, Sqoop is used to transmit
data, and the data is stored in HDFS. Mapreduce and
Spark are used to calculate and clean data, and the
analyzed data is performed by Hive. Second, state
data analysis. Status data analysis is to re-analyze the
analyzed data, but this analysis needs specific
algorithms to realize the analysis of the future
development direction, such as the entry rate,
turnover rate, internal turnover rate. Third, operation
trend forecast. Operation trend prediction is to
monitor the data information existing in the operation
process. Fourth, predictive warnings. After
monitoring and analysis, the data of abnormal state
predicted by trend will be sent to the platform
manager, who will inform relevant personnel or deal
with it directly. This part enables the enterprise to
predict the development trend, development trend
and potential turnover tendency of employees, so as
to prepare for the targeted guidance in the next step.
Targeted guidance. Targeted guidance is designed
according to the age, position, demand, performance,
salary, welfare and other aspects of employees. This
part makes use of the basic technology of big data,
that is, by using Flume tool to collect employee data
information, and then through Sqoop transmission
and HDFS storage, the data is calculated and cleaned.
In this process, you need to use the Mapreduce tool,
which uses Map to preprocess data, screen out the
data to be used, and group the data. Then, use the
Reduce tool to calculate the data using custom
calculation methods and summarize the data. After
collecting the data, use Hive to analyze the cleaned
data, and use Echarts to display the data results.
Managers give targeted guidance to employees
according to the results of previous prediction and
present data display. For example, different ways are
adopted to motivate employees of different ages to
work efficiently according to their different work
requirements.
4.3 Technical Support
4.3.1 Big Data Technology
The big data technologies used in this document are
basic technologies, such as Flume, Sqoop, HDFS,
Mapreduce, Spark, Hive, and Echarts. These basic
technologies are used in each part of the process of
collecting, storing, calculating and cleaning raw data,
analyzing and querying, and applying results. And
these technologies all have the characteristics of
simple operation, fast operation, large scale, high
security, and the tools used in the data visualization
link display diversification. Through the use of this
technology, the data management is intelligent, and
the data obtained is the expected data, in addition, the
data results displayed have diversity, both can be
represented by dynamic graph, and can be displayed
in other static ways.
BDEDM 2022 - The International Conference on Big Data Economy and Digital Management
910

4.3.2 The Cloud
Cloud computing is the product of deep integration of
traditional computer and network technologies, such
as distributed computing, parallel computing,
network storage, virtualization. The advantages of
cloud computing are large scale, virtualization,
scalability, strong computing and storage capabilities,
and high security. The use of this technology will
greatly reduce costs and improve efficiency. Cloud
computing services include IaaS, PaaS, SaaS. IaaS is
infrastructure service, PaaS is platform as a service,
and SaaS is software as a service. In this paper, SaaS
is used. SaaS is to enter the application platform
through the browser, but the platform needs to be
designed under the software based on the Web. The
advantage of SaaS is that the manager can customize
the design of software modules in the application
platform.
4.3.3 Barrage Technology
Bullet screen technology is realized by
superimposing three View interfaces, which are video
interface, bullet screen viewing interface and bullet
screen operation interface. Query methods such as
Toggle, animate. Toggle is a function used to design
the effects of bullets and animate to create custom
animations.
5 CONCLUSIONS
E-commerce human resource management
application platform is designed for the problems
existing in traditional e-commerce human resource
management. The design of the platform not only
solves the corresponding problems, but also realizes
the intelligent and efficient management of staff and
recruitment. It not only meets the needs of employee
development, but also encourages employees to
constantly improve themselves and work efficiently.
It has become the development direction of e-
commerce human resource management to acquire
and analyze data with the help of advanced
technology platforms, and the research data in this
direction will be more refined and visualized. In
addition, the analysis tools used will be more
simplified and diversified.
REFERENCES
How to understand big data. Baidu encyclopedia. See
https://zhuanlan.zhihu.com/p/369700766.
Read the big data stack. Baidu encyclopedia. See
https://my.oschina.net/alicoder/blog/3217055.
Wang Jiaren. (2016) Innovation of modern Enterprise
HUMAN resource Management based on "Internet +"
and big data Era. Heilongjiang Science.
Wang Yuanyuan. (2017) Research on Human resource
Management of Internet Enterprises in the Era of Big
Data -- A case study of JCTS Company. Minzu
University of China.
Zong Shiqiang. (2012) Networked Data Sharing Based on
Virtual View. Command Information System and
Technology.
Research on E-Commerce Human Resource Innovation Management in the Era of Big Data
911
