
An Ontology-based Possibilistic Framework for Extracting Relevant
Terms from Job Advertisements
Albeiro Espinal
1,2 a
, Yannnis Haralambous
1 b
, Dominique Bedart
2
and John Puentes
1
1
IMT Atlantique, Lab-STICC, CNRS UMR 6285, Brest, France
2
DSI Global Services, Le Plessis Robinson, France
Keywords:
Recruitment Process, Relevant Term Extraction, Recruiter’s Behavior Modeling, Textual Relevance Marker,
Ontology of Job Offer, Cognitive Uncertainty Measure, Ontology-based Belief-Desire-Intention Architecture.
Abstract:
In a traditional recruitment process, large amounts of resumes and job postings are often handled manually,
which is very time-consuming. Existing machine learning techniques for automatic resume ranking lack accu-
racy in accessing relevant information in job offers, which is crucially needed in order to ensure the pertinence
of resumes. We present a context-driven possibilistic framework for extracting such information from job
postings, in the form of relevant terms. In our process, after considering the recruiters’ specific organiza-
tional context, we analyze their term relevance evaluation strategies in job advertisements. By interviewing
a group of recruiters and analyzing their behavior, we have derived a first set of textual relevance markers.
Existing term-extraction methods from the literature were also applied to extract such textual relevance mark-
ers. We have evaluated all markers using cognitive uncertainty measures and we have integrated them into
an ontology-based Belief-Desire-Intention architecture. Doing this, we have improved the F1 score and recall
measures of existing state-of-the-art term extraction approaches by 20% and 29% respectively. Besides, our
framework is open-ended: it is possible to add new textual markers at any time as nodes of a fuzzy decision
tree, the calculation of which depends on the context and domain of job offers.
1 INTRODUCTION
In a recruitment process, recruiters interact with two
essential documents: Curricula Vitae (CV) and Job
Advertisements (JA). The former are documents sent
by applicants to communicate their qualifications,
while the latter are often written by recruiters to de-
fine the particular requirements of a new job opening
(Cabrera-Diego et al., 2019). In general, recruiters
are the main actors involved in managing these docu-
ments (Breaugh, 2013). They consider the pertinence
of each applicant’s CV and the requirements of the
JA. Based on this comparison, they select the most
relevant applicants to be contacted initially. This pro-
cedure is known as the “screening phase” (Cabrera-
Diego et al., 2019).
A screening phase becomes significantly complex
and time-consuming when recruiters need to evalu-
ate a large number of CVs and JAs (Cabrera-Diego
et al., 2019). This phenomenon is indeed globally ex-
perienced by multiple recruitment offices (Zhao et al.,
2021). To reduce such workload, machine learning
a
https://orcid.org/0000-0002-1907-3424
b
https://orcid.org/0000-0003-1443-6115
methods have been proposed for automatically rank-
ing applicants’ CVs depending on the content of a JA.
However, these methods do not achieve the expected
identification of relevant information expressed in the
JA. As a result, CVs are often ranked according to
background information, unrelated to the given JA.
To understand and overcome this limitation, we
studied the way recruiters evaluate information rel-
evance in JAs. The study of recruiters’ expertise is
essential, since they develop strategies to identify the
most relevant requirements of job positions.
As a first step in the modeling of the recruiter’s
cognitive process we chose to start with a very basic
linguistic stratum, namely the one of terms (Frantzi
et al., 2002; Cram and Daille, 2016). Therefore we
identify “relevant terms” in the JA, which the recruiter
expects to find in the CV. Of course, chances are the
terms used in the CV may be different, but they inter-
act with the relevant ones through a semantic network,
therefore an ontology is necessary to access a network
of similarities between terms.
To identify relevant terms we define the notion of
textual markers, that is: text features on various lin-
guistic strata that can be used for relevance evalua-
tion. The main contribution of our study is to provide
Espinal, A., Haralambous, Y., Bedart, D. and Puentes, J.
An Ontology-based Possibilistic Framework for Extracting Relevant Terms from Job Advertisements.
DOI: 10.5220/0011521700003332
In Proceedings of the 14th International Joint Conference on Computational Intelligence (IJCCI 2022), pages 163-174
ISBN: 978-989-758-611-8; ISSN: 2184-3236
Copyright © 2023 by SCITEPRESS – Science and Technology Publications, Lda. Under CC license (CC BY-NC-ND 4.0)
163

an ontology-based possibilistic framework to define
and evaluate textual markers associated to informa-
tion relevance in JAs. This framework is sufficiently
large to encompass the various recruiters’ strategies
and viewpoints. We also show how the organizational
context, as represented by the recruiters, can be ex-
ploited for automating and improving the extraction
of relevant information from JAs.
This article is organized as follows. Section 2
describes the state of the art. We summarize some
key principles of the proposed framework in Sec-
tion 3. The set of JA textual markers derived from
the recruiters’ perceptions and strategies is presented
in Section 4. Experimental results and discussion,
along with conclusions and perspectives are presented
in Sections 5, 6 and 7, respectively.
2 STATE OF THE ART
In general, the automated ranking of resumes in re-
lation to the content of a JA consists of three main
steps, namely, pre-processing, representation, and
ranking. Pre-processing includes text extraction from
documents in digital format, like .pdf, .doc, or .txt
files, followed by segmentation and semantic an-
notation of sections (Cabrera-Diego et al., 2019).
Moreover, noise reduction is necessary to identify
and remove stop words, as well as special sym-
bols (Roy et al., 2020). Thereafter, by means of
ontology-based (C¸ elik, 2016), document-embedding-
based (Zhu et al., 2018), or word-count-based tech-
niques (Cabrera-Diego et al., 2019), representations
of CVs and JAs are defined, their contents are com-
pared applying similarity metrics (Guo et al., 2016),
and a ranking of resumes is obtained.
Various approaches have been proposed to deter-
mine ranking. For instance, recruiters’ feedback has
been combined with the evaluation of a relevance al-
gorithm (Kessler et al., 2012) (Cabrera-Diego et al.,
2019). Other techniques, centered on word embed-
ding, used ranking methods based on neural net-
works such as CNNs, LSTMs, RNNs, and DNNs
(Deng et al., 2018). Attention-based models were
also defined to rank resumes with respect to JAs
(Zhao et al., 2021) (Wang et al., 2021). Furthermore,
joint embeddings were specified, in order to deter-
mine a common semantic space and compute cosine
similarities of CVs and JAs (Zhu et al., 2018).
The process of ranking applicants’ resumes en-
compasses a fundamental step, rarely studied in the
literature, namely the task of explicitly identifying the
most relevant information expressed in a JA, in order
to rank the corresponding resumes. This question of
explicit information extraction from JA has been ap-
proached under the perspective of document indexing,
at the document representation stage. Making use of
an n-gram and a graph representation of each docu-
ment, the RAKE (Rapid Automatic Keyword Extrac-
tion) (Rose et al., 2010) algorithm computes terms’
frequency and degree, to identify the most relevant
document terms. The YAKE! (Yet Another Keyword
Extraction) algorithm (Campos et al., 2018) uses tex-
tual and statistical features to detect the most pertinent
information expressed in documents. A parallel com-
bination of textual and graph-based statistical features
is used by the FRAKE (Fusional Real-Time Keyword
Extraction) algorithm (Zehtab-Salmasi et al., 2021)
for the same purpose. Finally, (Dagli et al., 2021)
studied the viability of topical and BERT (Bidirec-
tional Encoder Representations from Transformers)
models for identifying the most relevant information
in JAs.
Identifying the most relevant information in JAs is
essential to ensure the pertinence of an automatic re-
sumes ranking process. Yet, from the recruiter’s point
of view, relevant information in a JA is not equiva-
lent to extracted information for document indexing.
Additionally, existing studies in the field of document
indexing do not consider the organizational context of
JA processing. This point is critical since the under-
representation of the organizational context limits sig-
nificantly over time the application of machine learn-
ing methods (Martin Jr. et al., 2020).
In this study, we aim to improve the task of iden-
tifying automatically the most relevant information in
JAs, by giving a central role to the representation of
the organizational context. This context is a strong
component of the recruiters expertise, since their be-
havior is considerably influenced by the dynamics
and needs of each enterprise (Breaugh, 2013). The
ontology-based possibilistic framework that we pro-
pose intends to leverage organizational context inte-
gration, through the analysis of recruiters’ strategies
and viewpoints, for deriving context-driven textual
markers of information relevance in JAs.
3 FRAMEWORK DESCRIPTION
Our framework is structured in three axes: The first
axis analyses what is relevant for recruiters in JAs.
We specify the organizational context of the docu-
ments and derive textual markers of information rel-
evance. These markers are represented by an ontol-
ogy. The second axis evaluates the pertinence of the
markers from a recruiters’ perspective. To this end,
a fuzzy decision tree is constructed to identify unde-
FCTA 2022 - 14th International Conference on Fuzzy Computation Theory and Applications
164

tected relationships between markers. These relation-
ships become new markers associated to information
relevance in a JA. As for the third axis, it determines
the best textual markers in a possibilistic agent archi-
tecture.
3.1 Definitions
Recruiters and job applicants write JAs and CVs re-
spectively, with a single goal: to express the set of
professional skills that they need or offer (Zhao et al.,
2021). A professional skill can be defined as the mo-
bilization of knowledge, know-how, and interpersonal
abilities to achieve the goals of a professional activity
(Le Vrang et al., 2014). A professional activity can be
defined as a series of related tasks, requiring special
knowledge and skills (Kiselyova et al., 2021).
A recruitment process is a sequence of steps un-
dertaken to identify, engage, and retain the best appli-
cant for a specific job position. With the help of field
experts, recruiters identify the set of skills for a new
job opening. The main needs are then expressed in a
JA. Applicants respond to the JA by sending their re-
sumes, which are manually evaluated by recruiters in
order to determine whether or not the content of the
resumes meets the JA requirements (Cabrera-Diego
et al., 2019).
The screening phase demands the recruiter to gain
knowledge of the organizational context in order to
achieve successful results (Roy et al., 2020). Follow-
ing this phase, the most suitable profiles are contacted
on a personal basis in order to gain insight into their
experience and skills. Finally, recruiters conduct face-
to-face interviews with the top-ranked candidates.
3.2 Organizational Context and
Recruiters’ Strategies
In this section, we provide further details about the
protocol that we propose for extracting and construct-
ing textual features from recruiters’ strategies and
viewpoints. In general, a recruitment process takes
place in the organizational context of an enterprise.
We represent the organizational context of our do-
main, adapting an existing definition of societal con-
text (Martin Jr. et al., 2020). Accordingly, the orga-
nizational context surrounding JAs is represented by
identifying the main social actors, artifacts, actions
on artifacts, and enterprise processes, associated with
this type of document. Those aspects of the organi-
zational context can significantly influence the life-
cycle of CVs and JAs in the hiring processes. As a
consequence, the representation of the organizational
context is a fundamental preliminary step. Our ap-
proach makes use of the UNC-method, which was
defined for representing organizational contexts (Za-
pata Jaramillo and Arango Isaza, 2009), as:
1. The organizational context representation is con-
structed together with recruiters from preliminary
interviews (Zapata Jaramillo and Arango Isaza,
2009). Pre-conceptual schema and domain mod-
els are applied to identify and model the main
contextual concepts and their relationships. From
these representations, a mother-ontology is di-
rectly derived. This ontology covers the main con-
cepts associated with JAs and the particular orga-
nizational context where these documents are pro-
cessed.
2. Based on these diagrams, recruiters goals related
to the life-cycle of JAs in the recruitment pro-
cesses, are identified and represented in a hierar-
chical structure.
3. Process diagrams (Zapata Jaramillo and
Arango Isaza, 2009) represent models of en-
terprise processes related to JAs.
4. Using a fishbone chart, the relationships between
organizational problems related to JAs and their
causes are also represented.
5. As suggested by (Zapata Jaramillo and
Arango Isaza, 2009), all the previous dia-
grams are combined in a Process Explanatory
Table in order to unify the representation of the
organizational context.
6. From this representation and the derived ontology,
the analysis of recruiters perceptions and strate-
gies about information relevance in JAs is carried
out.
7. Recruiters proceed to annotate relevant informa-
tion in JA documents, handled in different recruit-
ment processes. As recruiters read and annotate
the most relevant information in JAs, each an-
notation is observed and described in detail, ap-
plying the controlled language proposed by (Zap-
ata Jaramillo and Arango Isaza, 2009).
8. Our approach identifies and classifies common
and transverse recruiters’ behaviors when anno-
tating documents into two categories: explicit
ones (such as selecting a term) and implicit ones
(such as refraining from selecting of a term).
Transverse annotation behaviors are described by
semantic rules. The mother-ontology conceived
in step (1) is used to model the concepts and rela-
tions required by each rule. These semantic rules
are textual markers of information relevance in
JAs.
An Ontology-based Possibilistic Framework for Extracting Relevant Terms from Job Advertisements
165

9. Cognitive uncertainty associated to derived tex-
tual markers is estimated by computing an am-
biguity measure, as defined in (Yuan and Shaw,
1995). In Section 4, we formalize the process of
evaluating textual markers.
10. Relevance markers with an ambiguity level less
than or equal to an ambiguity threshold are se-
lected and implemented in an ontology-based pos-
sibilistic agent architecture to simulate recruiters’
behaviors. Relations between markers are anal-
ysed by calculating a fuzzy decision tree (Yuan
and Shaw, 1995). In this tree, each marker is con-
sidered as a decision node. The least ambiguous
relations derived from this tree are identified as
new relevance markers in the agent’s architecture,
in order to improve its deliberation process of in-
formation relevance in JAs.
3.3 Ontological Resources
As a fundamental part of our framework, a mother-
ontology contains the main concepts and relations
inherent to the specific context of JAs. This on-
tology is complemented by integrating existing on-
tologies related to the specific organizational context.
In our case, we integrated the following sources of
knowledge. The internal ontology of DSI Group, a
French consulting firm. It contains over 36,000 pro-
fessional skills, lexically represented in French lan-
guage. By complementing it with international on-
tologies like ESCO (Le Vrang et al., 2014), we also
reconstructed ontologies that underpin professional
skills frameworks such as O*NET
1
, CIGREF
2
, and
ROME
3
, based on text-to-RDF-triple transformations
(Somodevilla Garc
´
ıa et al., 2018).
Additionally, we built an ontology based on
14,000 anonymous CVs and 2,000s JAs, in a semi-
automatic manner, by applying ontology learning
techniques (Alfonso-Hermelo et al., 2019). Specif-
ically, we extracted and processed the professional
skills’ sections of these documents. Then, we inte-
grated all ontologies to the mother-ontology by us-
ing a hybrid approach based on transformer models
(BERT), a terminological variation analysis (Cram
and Daille, 2016), and ontology quality metrics (Mc
Gurk et al., 2017). In Figure. 1, we present an upper-
view of the resulting ontology.
1
https://www.onetonline.org/
2
https://www.cigref.fr/
3
https://www.pole-emploi.fr/employeur/vos-
recrutements/le-rome-et-les-fiches-metiers.html
3.4 Beliefs, Desires and Intentions
Architecture of the Agent
According to multiple empirical studies, ”...hu-
mans’ semantic inferences are uncertain and context-
sensitive...” (Pavlick and Kwiatkowski, 2019). The
same principle can be applied to the process of ex-
tracting relevant terms from JAs. In fact, recruiters
semantically infer relevant terms by reading the JA’s
text, ”...[assuming] common human understanding of
language [and] common background knowledge...”
(Pavlick and Kwiatkowski, 2019). Consequently, we
propose a possibilistic architecture to incorporate hu-
man semantic reasoning and its associated uncertainty
for enhancing the automatic extraction of relevant
terms.
Specifically, this architecture (Da Costa Pereira
and Tettamanzi, 2010) is based on what has been de-
fined as the agent’s beliefs, desires, and intentions
paradigm, linked to modeling of variables applying
possibility (Figure. 2).
The module of beliefs is composed by two sub-
modules. The first one consists of a distribution of
trust degrees τ, which represents a trust level that
the agent assigns to its sources φ. In our context,
there are three categories of sources: JAs, ontologi-
cal resources, and textual markers of information rel-
evance. We define trust degrees through quality met-
rics, in order to detect possible inconsistencies, as
malformed JA texts, ontology conformity issues (Mc
Gurk et al., 2017), or ambiguous textual relevance
markers. Each trust degree is associated to a toler-
ance threshold β
j
. A source with a trust degree τ
j
below a given tolerance threshold β
j
will be rejected
by the agent.
The second sub-module makes use of a possibil-
ity distribution π, which represents the agent’s be-
liefs B. Each term is characterized by a possibility
distribution formed by the levels of relevance (possi-
bility degrees) provided by each marker. This possi-
bility distribution induces a measure of possibility Π
(Da Costa Pereira and Tettamanzi, 2010). It shows to
what extent a term is pertinent. Then, the possibility
measure is associated to its dual necessity measure N
(Da Costa Pereira and Tettamanzi, 2010). The latter
can be interpreted as to what extent it is impossible
not to conclude that a term is relevant. Note that pos-
sibility degrees of beliefs are limited to the trust de-
gree of their respective information about knowledge
sources. A belief modification operator ∗ is defined
for this purpose (Da Costa Pereira and Tettamanzi,
2010).
The second agent’s component is the module of
desires, represented by an utility distribution (for-
FCTA 2022 - 14th International Conference on Fuzzy Computation Theory and Applications
166
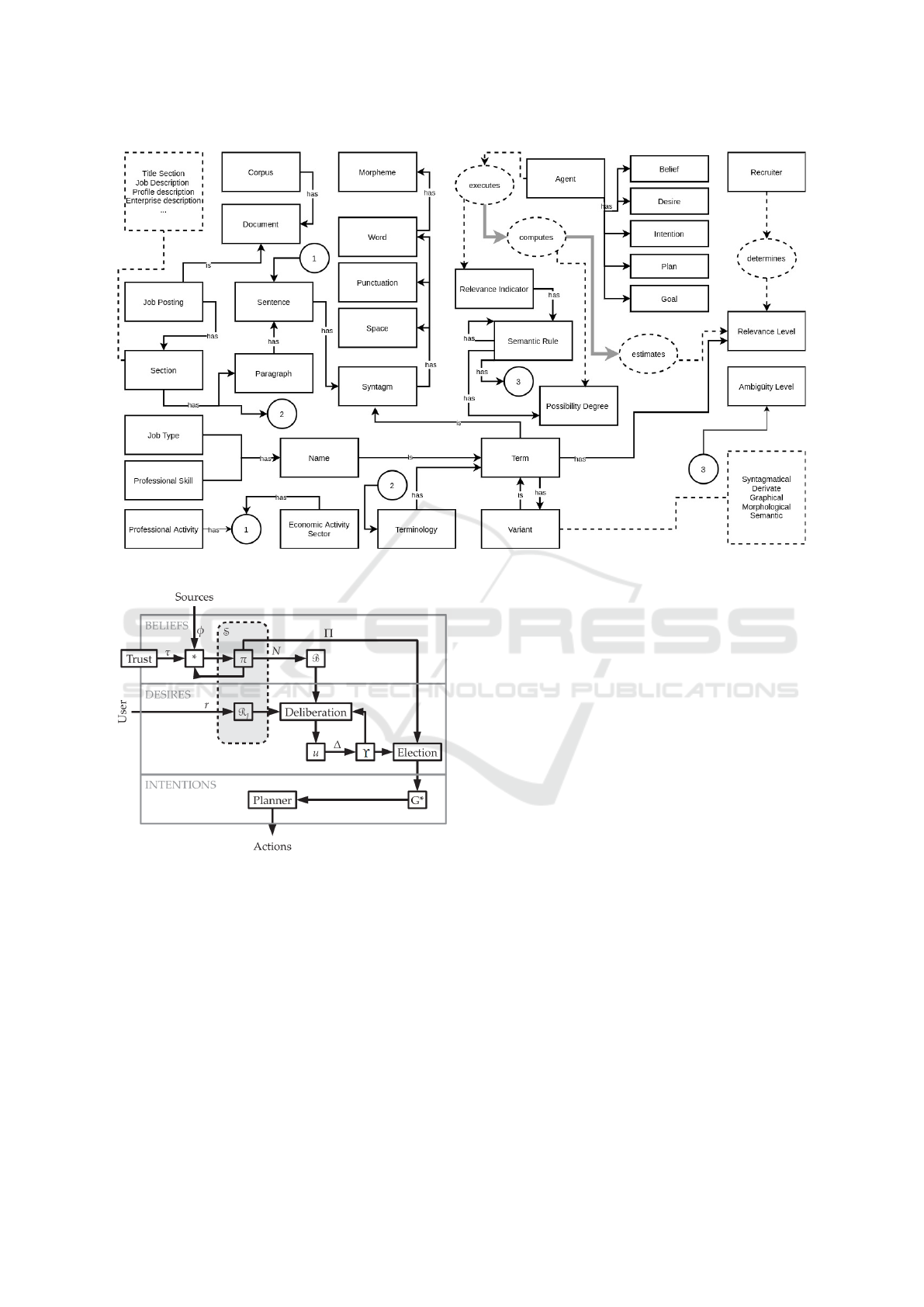
Figure 1: Upper-view of the mother-ontology created from the context representation.
Figure 2: Basic architecture of the dynamic BDI agent
(Da Costa Pereira and Tettamanzi, 2010).
mally a possibility distribution), which indicates
whether or not the use of a textual relevance marker
is convenient according to the current agent’s be-
liefs, desires, and desire-generation rules. Desire-
generation rules R
J
are logical conditions expressing
dependence relationships between beliefs and desires
(Da Costa Pereira and Tettamanzi, 2010). The eval-
uation of desire-generation rules allows the agent to
estimate to what extent ∆ it is justified to make use of
each marker. Textual markers associated to positive
degrees become justified desires ϒ.
The third agent’s component, namely intentions,
consists of actions that the agent decides to execute
based on its current beliefs, justified desires, and
goals. A plan outlines the sequence of actions to be
taken. In our context, these actions refer to natural
language processing methods that are necessary to au-
tomatically extract the relevant terms from JAs.
4 TEXTUAL MARKERS
The algorithm YAKE! (Campos et al., 2018) already
uses textual markers, but defined in an informal way.
In this section we will formally define the notion of
textual marker in a way that it is compatible with
YAKE! textual markers, as well as with textual mark-
ers actually used by recruiters.
4.1 Preliminary Definitions
According to (Cram and Daille, 2016), a term is “a
functional class of lexical units used in discourse”. In
our context, terms are identified based on their ter-
mhood (Frantzi et al., 2002), measured by using the
weirdness ratio (Cram and Daille, 2016).
Terms are extracted by applying the most frequent
morpho-syntactic patterns to multiple specialized cor-
pora (Cram and Daille, 2016). Nearly all of them cor-
respond to nominal phrases.
Let d
i
be a JA belonging to a corpus C and T
d
i
=
An Ontology-based Possibilistic Framework for Extracting Relevant Terms from Job Advertisements
167

{t
1
,t
2
,.. .,t
n
} the set of terms of d
i
.
Let R
d
i
⊆ T
d
i
be the set of most relevant terms in
d
i
. Each term t
i
∈ R
d
i
is considered as relevant under
a possibility degree α
t
i
.
Let A
d
i
= {a
1
,a
2
,.. .,a
m
} be the set of sections of
d
i
(job description, profile details, etc). Each section
a
i
can be represented by a subset of terms from T
d
i
. A
term can belong to multiple sections.
Let E
d
i
= {e
1
,e
2
,. .., e
p
} be a set of qualifying ad-
jectives and nouns that are linked to a subset of terms
in T
d
i
by syntax dependencies.
Let O = {o
1
,o
2
,. .., o
s
} be a set of ontologies
(as the one presented in Section 3). Let c
o
s
=
{c
s,1
,c
s,2
,. .., c
s,k
} be the set of concepts of ontology
o
s
and T
c
j
= {t
j,1
,t
j,2
,. ..,t
j,l
} the set of terms lexi-
cally representing concept c
j
in a given language.
The mother-ontology O contains, among other
concepts, the structure of a textual document: sec-
tions, paragraphs, sentences, syntagms, terms, words,
morphemes, etc.
4.2 Definitions of Markers
In this section, textual markers #1 to #10 have been
obtained by monitoring the behavior of expert re-
cruiters and by interacting with them. Textual mark-
ers #11 to #16 correspond to those of the YAKE! term
extraction approach.
4.2.1 Textual Marker #1: Presence of
Professional Skills or Job Types in Title
Sections
“In the event that a term in the title matches one of
the terms used to represent professional skills or job
types, then it can potentially be considered as rele-
vant.”
Let a
1
∈ A
d
i
be the title section of d
i
. Let t
a1
=
{t
1
,t
2
,. ..,t
u
} be the set of terms contained in a
1
. T
c
j
is the set of terms lexically representing a professional
skill or job type concept c
j
in the ontology o
s
. We
request that:
∀t
k
∃c
j
[c
j
∈ o
s
∧t
k
∈ T
c
j
∧t
k
∈ t
a1
] → t
k
∈ R
d
i
, (1)
with a possibility degree α
t
k,1
∈ [0, 1].
4.2.2 Textual Marker #2: Terms Representing
Professional Skills in a Job Description
Section or Profile Description Section
In general, a term used to represent a professional
skill in a job description section or in a profile de-
scription section is more likely to be chosen as a rele-
vant term. Let s
2
and s
3
be the sets of terms in the job
description section and the profile description section,
respectively. Set t
k
∈ T
d
i
. Let T
c
j
be the set of terms
representing a professional skill concept c
j
in the on-
tology o
s
. We request that:
∀t
k
∃c
j
((t
k
∈ s
2
∨t
k
∈ s
3
) ∧t
k
∈ T
c
j
) → t
k
∈ R
d
i
, (2)
with a possibility degree α
t
k,2
∈ [0, 1].
4.2.3 Textual Marker #3: Relevance of Job
Posting Sections
“Recruiters will choose with a higher possibility de-
gree terms used in the title, job description, and pro-
file description sections, rather than terms belonging
to other sections (company description, contract de-
tails, etc).”
This marker is not redundant with markers #1 and
#2, since we do not request terms to be professional
skills. Let S = s
1
∪ s
2
∪ s
3
⊆ T
d
i
, where: s
1
is the set
of terms of the title section; s
2
is the set of terms of
the job description section; and s
3
is the set of terms
of the profile description section.
Let t
m
∈ T
d
i
∩ S. Then, we request that:
∀t
m
∀t
n
(t
m
∈ T
d
i
∧t
n
/∈ S) → (P(t
m
∈ R
d
i
) > P(t
n
∈ R
d
i
)),
(3)
with a possibility degree α
t
k,3
∈ [0,1]. P(t
∗
∈ R
d
i
) de-
notes the possibility of t
∗
being chosen as a relevant
term.
4.2.4 Textual Marker #4: Terms Dependent on
Pertinence Expressions
“A term that bears a syntax dependency with a syn-
tagm of the JA is more likely to be chosen as a rele-
vant term.”
• Let t
k
∈ T
d
i
∩ T
c
j
for some c
j
.
• We define a “pertinent expression” e
m
as a syn-
tagm used by the recruiter who wrote the JA (i.e.,
you master C#, good knowledge of cloud com-
puting). Let us suppose that e
m
is syntactically
dependent with t
i
. More specifically, let t
k
be a
qualifying adjective or a noun modifier directly
dependent with e
m
. Then, we request that:
∀t
k
∃e
m
(t
k
∈ T
d
i
∧e
m
∈ E
d
i
∧is
dependent(t
k
,e
m
))
→ t
k
∈ R
d
i
, (4)
with a possibility degree α
t
k,4
∈ [0, 1].
4.2.5 Textual Marker #5: Terms Used in Traces
of Professional Activities Descriptions
“It will be more likely for a term representing a pro-
fessional concept to be considered as relevant when
a job description explicitly describes an interaction
with this concept.”
We define a trace of a professional activity de-
scription as a sentence in a job posting, describing a
worker’s action on an object. Be b
j
∈ d
i
a trace of
a professional activity description represented by the
FCTA 2022 - 14th International Conference on Fuzzy Computation Theory and Applications
168

set of terms T
b
j
. We request that b
j
contains at least
one verb and one dependent object. We assert that the
terms t
k
representing these objects will have a greater
possibility degree of being chosen as relevant. There-
fore:
∀t
k
(t
k
∈ T
b
j
∧ is object(t
k
,b
j
)) → t
k
∈ R
d
i
, (5)
with a possibility degree α
t
k,5
∈ [0, 1].
4.2.6 Textual Marker #6: Terms Representing
High Risk Professional Skills/Activities
This marker intends to provide more relevance to
terms representing professional skills or activities for
which an employee’s mistake can significantly de-
grade the company’s economic activity. Value 0 in-
dicates that a potential mistake will not have a sub-
stantial impact on the economic activity, while value 1
indicates that an error on this skill or activity will have
a strong impact.
Depending upon the unique context of each enter-
prise, this textual marker allows the agent to adapt its
own behavior to meet the specific needs of each job
opening.
Let M be an ontology that contains the set of pro-
fessional skills and activities of a given company. M
contains a set of concepts c
M
= {c
M,1
,c
M,2
,. .., c
M,k
}.
The recruiter manually assigns a risk level ε
c
M,k
∈
[0,1] to each professional skill or activity.
Let s
j
be a term in a job posting d
i
representing
a professional skill or activity in M. Among the con-
cepts associated to s
j
, let c
M,l
be the concept with the
maximal risk level. If this risk level is greater than
a threshold β
c
M,l
, then s
j
is chosen as a relevant term
and:
∀s
j
∃c
M,l
(s
j
∈ T
d
i
∧ c
M,l
∈ M ∧ s
j
∈ T
c
M,l
∧ is greater than(ε
c
M,l
,β
c
M,l
) → s
j
∈ R
d
i
, (6)
with possibility degree α
s
j,6
∈ [0, 1]
4.2.7 Textual Marker #7: Actions Expressed in
Management JAs
It is also important for recruiters to identify the type
of actions required by management JAs. For instance,
some jobs focus on team management, while others
include accountability activities or even development
tasks. This is because management jobs can be quite
diverse.
Be d
i
a management job posting. The agent de-
tects management JAs based on a Latent Dirichlet Al-
location model, trained on 14,000 curricula vitae. Let
t
k
be a verbal term of d
i
. If t
k
belongs to the trace of a
professional activity f
j
and corresponds to the head of
its syntactic tree, then it potentially is a relevant term.
We define this marker as:
∀t
k
∃ f
j
( f
j
∈ d
i
∧t
k
∈ f
j
∧ is management(d
i
)∧
is verb(t
k
) ∧ is head of(t
k
, f
j
)) → t
k
∈ R
d
i
, (7)
with a possibility degree α
t
k,7
∈ [0, 1].
4.2.8 Textual Marker #8: BERT Semantic
Similarity of Professional Skills
“Specific terms used to represent professional skills
that are semantically close (in the sense of BERT) to
already discovered relevant terms, will be considered
relevant.”
Let t
1
∈ R
d
i
and t
2
∈ T
d
i
. We define the specificity
function (Cram and Daille, 2016) of a term f (t) as its
relative frequency in a specific corpus C
s
, divided by
its relative frequency in a multi-language corpus C
L
.
Furthermore, we define g(t
1
,t
2
) as the BERT se-
mantic similarity between two terms. We used a
SBERT model pre-trained on the Wikipedia corpus
(Reimers and Gurevych, 2019) to derive semantically
meaning from complex terms. This model was fine-
tuned on the professional skill standards CIGREF, e-
CF, c2i, and ROME, being formalized as follows:
∀t
1
∀t
2
(t
1
∈ R
d
i
∧ g(t
1
,t
2
) > 0) → t
2
∈ R
d
i
, (8)
with a possibility degree defined by the normalized
equation :
α
t
2
,8
= ∥(1 − α
t
1
) ∗ g(t
1
,t
2
) ∗ f (t
2
))∥. (9)
4.2.9 Textual Marker #9: Relevance of the
Economic Activity Sector
“Terms referring to an economic activity sector re-
quired by a job posting (e.g., finance, banks, aeronau-
tics, etc.) will be chosen as potentially relevant.”
This implies that:
∀t
k
(t
k
∈ T
d
i
∧ is sector requirement(t
k
)) → t
k
∈ R
d
i
,
(10)
with a possibility degree α
t
k,9
∈ [0, 1].
Economic activity sectors are identified by align-
ing job posting terms and economic activity concept
labels, provided by ESCO, O*NET, ROME, and CI-
GREF standards.
4.2.10 Textual Marker #10: Professional Skill
Prerequisites
Let there be a prerequisite relation between two pro-
fessional skills c
1
and c
2
as given in an ontology o
i
.
Relations of this type can be obtained from ontolo-
gies such as ESCO. If c
2
is a prerequisite of c
1
and c
1
is considered as relevant (under a certain possibility
degree) then c
2
inherits the possibility degree of c
1
.
∀t
1
∀t
2
∃c
1
∃c
2
(c
1
∈ o
i
∧c
2
∈ o
i
∧t
1
∈ T
c
1
∧t
2
∈ T
c
2
∧
is prerequisite(c
1
,c
2
) ∧t
1
∈ R
d
i
) → t
2
∈ R
d
i
, (11)
An Ontology-based Possibilistic Framework for Extracting Relevant Terms from Job Advertisements
169

with a possibility degree α
t
k,10
∈ [0,1]. This possibil-
ity degree is equal to the possibility degree of t
1
∈ R
d
i
.
4.2.11 Textual Marker #11: YAKE! Casing
Upper-cased terms tend to be more relevant. In
our context, this YAKE! marker is related to the re-
cruiters’ behavior, as they tend to capitalize terms per-
taining to professional skills:
∀t
k
(t
k
∈ T
d
i
∧ is upper cased(t
k
)) → t
k
∈ R
d
i
(12)
We define the possibility degree of this rule based
on the normalized YAKE! equation:
α
t
k,11
(t
k
) =
max(TF(U(t
k
),TF(A(t
k
))
ln(TF(t
k
))
, (13)
where TF(U (t
k
)) is the number of times that t
k
ap-
pears uppercased, TF(A(t
k
)) is the number of occur-
rences of t
k
as an acronym (for details see (Campos
et al., 2018)) and TF(t
k
) is the term frequency.
4.2.12 Textual Marker #12: YAKE! Term
Position
The hypothesis of this marker is that terms appearing
at the beginning of the document tend to be more rel-
evant.
∀t
k
(t
k
∈ T
d
i
∧ is position marker activated(t
k
))
→ t
k
∈ R
d
i
, (14)
with a possibility degree given by the following nor-
malized YAKE! equation:
α
t
12
(t
k
) = ∥ ln(ln(3 + Median(Sent(t
k
))))∥, (15)
where Sent(t
k
) is the set of positions of the sentences
containing t
k
.
4.2.13 Textual Marker #13: YAKE! Term
Frequency Normalization
The most commonly used terms are more relevant.
Hence:
∀t
k
(t
k
∈ T
d
i
∧ is frequency marker activated(t
k
))
→ t
k
∈ R
d
i
, (16)
with a possibility degree given by the following nor-
malized equation proposed by YAKE!:
α
t
k,13
(t
k
) =
TF(t
k
)
MeanTF + σ
, (17)
where TF(t
k
) is the number of occurrences of t
k
,
which is balanced by the mean and standard deviation
of frequency.
4.2.14 Textual Marker #14: YAKE! Term
Relatedness to Context
This YAKE! marker is based on the following hypoth-
esis: “The higher the number of different terms that
co-occur with a candidate term t on both sides, the
least significant term t will be”:
∀t
k
(t
k
∈ T
d
i
∧ is relatednes activated(t
k
)) → t
k
∈ R
d
i
,
(18)
with a possibility degree obtained from the normal-
ized YAKE! equation:
α
t
k,14
=
1 + (DL + DR···) ∗
TF(t
k
)
maxTF
, (19)
where
DL[DR] =
|A
t,w
|
∑
k∈A
t,w
CoOccur
t,k
. (20)
|A
t,w
| corresponds to the number of different terms in
a window of size w and TF is the term frequency.
4.2.15 Textual Marker #15: YAKE! Different
Sentences
“A term will be more relevant depending on how often
it is used within different sentences,” represented as:
∀t
k
(t
k
∈ T
d
i
∧ is sentences marker activated(t
k
))
→ t
k
∈ R
d
i
, (21)
with a possibility degree obtained from the normal-
ized equation:
α
t
k,15
=
SF(t
k
)
#Sentences
, (22)
where SF(t
k
) is the number of sentences containing t
k
and #Sentences is the total number of sentences of d
i
.
4.2.16 Textual Marker #16: YAKE! Overall
Score
We include the global relevance score proposed by
YAKE! which is based on markers #11, #12, #13, #14,
and #15 (Campos et al., 2018). Let t
k
∈ d
i
. A term is
considered as “partially relevant” if it’s predicted as
such by the overall score:
∀t
k
(t
k
∈ T
d
i
∧ is predicted by yake(t
k
)) → t
k
∈ R
d
i
,
(23)
with a possibility degree α
t
k,16
∈ [0, 1].
4.3 Evaluation of Relevance Markers
According to (Yuan and Shaw, 1995), “a classification
task can be viewed as a rational action that a decision
maker will take in consistency with his or her knowl-
edge”. In our case, the recruiter’s task of annotating
relevant terms is associated with uncertainties, which
have been measured in the literature through ambigu-
ity measures (Yuan and Shaw, 1995). Based on ambi-
guity estimation, we propose a protocol for evaluating
the pertinence of relevance markers.
FCTA 2022 - 14th International Conference on Fuzzy Computation Theory and Applications
170

4.3.1 Protocol Formalization
Let U = {t} be the set of terms of a given JA. Let
C be a fuzzy set representing the recruiter perceived
levels of term relevance in a JA. C is represented by
the membership function µ
C
, which maps recruiters’
annotations into C. C is constituted by two fuzzy sub-
sets: the subset C
1
of relevant term levels and the sub-
set C
2
of non relevant term levels. Both fuzzy cat-
egories are represented by triangular functions. We
will call R (resp. R
1
,R
2
) the subset of C (resp. C
1
,C
2
)
obtained from the fuzzification of recruiters annota-
tions on the JA.
Each JA term t can be described by a set of rele-
vance markers I
k
, obtained from recruiters strategies
and viewpoints. We denote A(t) = {I
1
,I
2
,. .., I
k
}.
Each relevance marker provides a degree of pos-
sibility for a term to be selected as relevant. The next
step involves fuzzifying these possibility degrees by
applying a membership function µ
I
k
. Although µ
I
k
was built in an equivalent manner as µ
C
, the specific
codomain of each marker I
k
was taken into account.
We interpret the result of this fuzzification process as
an evidence E
k
.
After fuzzifying I
k
and the recruiters’ annotations,
we evaluate the possibility of describing the fuzzi-
fied recruiters’ annotations R based on the evidence
E
k
obtained from I
k
. More specifically, we evaluate
the ambiguity level of the following rule: If E
k
Then
R. To do it, a subsethood measure between the ev-
idence E
k
and the experts’ classification R has been
proposed (Yuan and Shaw, 1995). In our context, as
a substitute for subsethood, we use the Hamming dis-
tance between fuzzy sets to reflect more explicitly to
what extent recruiter’s knowledge R approximates E
k
:
S(E
k
,R) =
∑
t∈U
µ
I
k
(t) − µ
R
(t)
. (24)
The Hamming distance measures the degree to
which a term is relevant or not, based on the avail-
able evidence E
k
. Applying this distance, we define
the possibility π of classifying a term as relevant (R
1
)
or non relevant (R
2
), in relation to recruiter’s strate-
gies and viewpoints as:
π(R
i
| E
k
) =
S(E
k
,R
i
)
max(S(E
k
,R
1
),S(E
k
,R
2
))
. (25)
Possibility is intrinsically related to the concept of
ambiguity (Yuan and Shaw, 1995). Based on E
k
, the
more likely we are to deduce that a term is relevant or
not, the less ambiguity there is. From π(R | E
k
), we
estimate the ambiguity level associated to marker I
k
,
or equivalently, to the evidence E
k
as:
G(E
k
) = g(π(R|E
k
)) =
n
∑
i=1
(π
∗
i
− π
∗
i+1
)ln(i), (26)
where π
∗
= {π
∗
1
,π
∗
2
,. .., π
∗
n
} is the possibility distribu-
tion π(R | E
k
) permuted and sorted so that π
∗
i
≥ π
∗
i+1
for i ∈ {1, .. ., n} and π
∗
n+1
= 0. In our case, n = 2 as
we evaluate ambiguity when deciding whether a term
is relevant (R
1
) or not (R
2
) based on I
k
.
This ambiguity function G indicates to what de-
gree it can be inferred that a term is pertinent or not,
depending on the relevance marker I
k
. A value of
0 means that there is no ambiguity and a value of
ln(n) represents the maximal ambiguity level (Yuan
and Shaw, 1995).
Since A = {I
1
,I
2
,, ... ,, I
k
} is the set of relevance
markers, based on the least ambiguous markers with
an ambiguity level below or equal to a threshold σ,
we train a fuzzy decision tree (Yuan and Shaw, 1995).
We replace the classical information entropy mea-
sure with the previously presented ambiguity metric.
As proposed by (Yuan and Shaw, 1995), the path of
branches from the roots to the leaves is converted to
simplified logical rules. These new rules represent
logical relations between markers associated to in-
formation relevance. The least ambiguous ones are
added as new sources of information in the agent ar-
chitecture. This allows us to enrich the deliberation of
the agent. The process of building the fuzzy decision
tree is an important step in evaluating the pertinence
of markers. A fuzzy decision tree can be used for
discovering unseen relationships between them, and
also for automating the classification task of relevant
terms’ prediction.
5 EXPERIMENTAL RESULTS
We evaluated the proposed framework in the setting
of the recruitment office of DSI Group. We inter-
viewed four recruiters, which we refer to in this study
as A, B, C, and D. These recruiters spent multiple
days or even weeks leading recruitment processes and
managing their associated JAs, exchanging on a daily
basis with management and technical experts. In
other words, they gained an in-depth understanding of
the most fundamental needs of their JA by acquiring
high levels of contextual knowledge.
Based on preliminary interviews with these re-
cruiters, the organizational context surrounding the
JAs was represented. Then, we interviewed an ex-
pert recruiter (recruiter A) in order to identify which
job requirements were most relevant to the managed
JAs. During this interview, we asked the recruiter the
following question about five JAs: what are the re-
quirements expressed in this JA that you would not
accept a candidate without?
According to personal viewpoints and knowledge,
An Ontology-based Possibilistic Framework for Extracting Relevant Terms from Job Advertisements
171
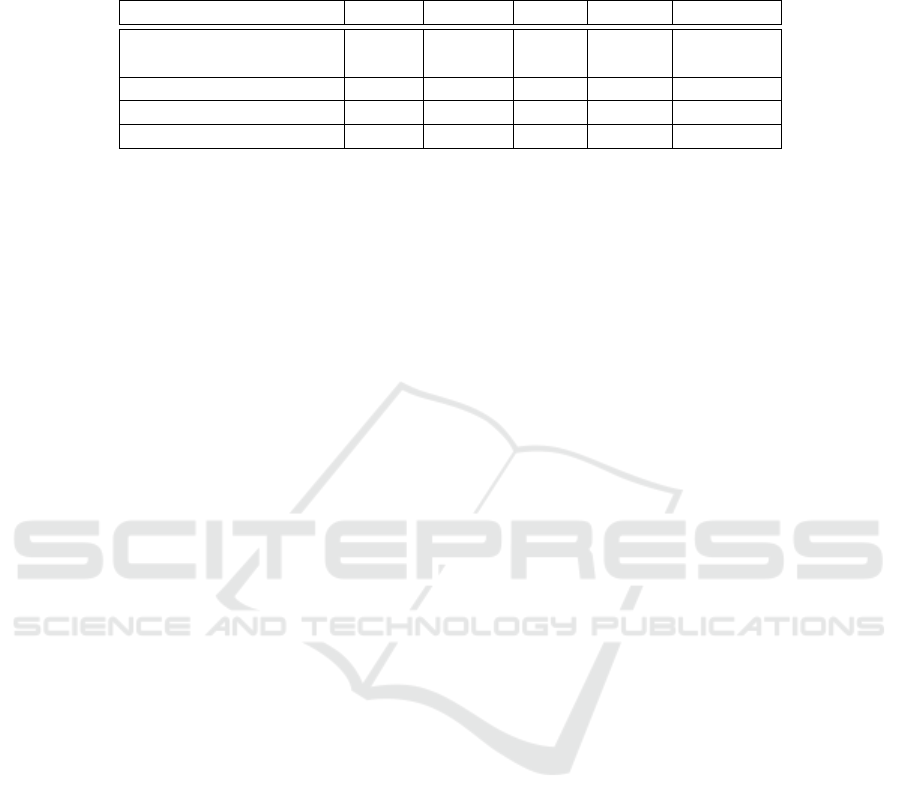
Table 1: Experimental results. Precision, recall, and F1-score levels of each method on 20 job advertisements applying RAKE
(Rose et al., 2010), FRAKE (Zehtab-Salmasi et al., 2021), BERT topics approach (Dagli et al., 2021), YAKE! (Campos et al.,
2018), and our Agent.
Metric/Method RAKE FRAKE BERT YAKE! Our Agent
Recall@N, Precision@N
F1-Score@N
4
0.02 0.09 0.17 0.10 0.38
Recall@2N 0.08 0.17 0.20 0.27 0.56
Precision@2N 0.04 0.08 0.10 0.13 0.28
F1-Score@2N 0.05 0.11 0.14 0.18 0.38
this recruiter marked a set of terms that represented
the most essential requirements of each JA. The ma-
jority of annotated terms corresponded to professional
skills. A small number of terms related to locations or
key aspects of previous responsibilities. The recruiter
annotated a minimum of 4 terms and a maximum of
10 terms per JA. In this specific application case, JAs
had, in average, 100 terms.
By applying our framework, we derived textual
markers of information relevance associated to the
recruiter strategies and viewpoints. These markers
were formalized, implemented, and became the cor-
nerstone of a BDI agent. We evaluated the validity
and reproducibility of this agent on 20 recruitment
processes managed by recruiters B, C and D. This
process was executed as follows:
• We asked recruiters B, C and D to annotate the
most relevant information expressed in the set of
JAs associated to their recruitment processes.
• We compared their annotations in relation to the
most relevant terms predicted by the agent derived
from recruiter A’s strategies and viewpoints.
• We compared the performance of the proposed
agent to state of the art term extraction meth-
ods. We used precision@K, recall@K and F1-
score@K metrics to asses the suitability of each
model, in predicting the top N and top 2N most
relevant terms of each annotated JA (where N rep-
resents the number of terms annotated by the re-
cruiter on each document).
Even if theoretically our approach should be com-
pared to other approaches specifically designed for
JAs, we discarded that aim for two reasons. To the
best of our knowledge, currently there are not auto-
mated and open source methods for extracting specif-
ically relevant information from JA. Also, there are no
public JA corpora annotated for the extraction of rele-
vant information. For these reasons, we compared our
approach to the performance of domain-independent
state of the art term extraction methods. In their re-
spective papers, these approaches were evaluated on
annotated academic documents, news texts, and sci-
entific articles (Campos et al., 2018). Therefore, this
is the first time that they are evaluated on JAs.
Table 1 presents the results of our experiments.
As indicated by the metrics, our algorithm’s results
are significantly better than the other four algorithms.
Particularly, compared to the best results of those al-
gorithms (most of them from YAKE!), our approach
improvements vary from 15% to 29%, being 56% for
Recall@2N the highest performance.
Regarding the performance of the BDI agent,
three aspects of its behavior were essential for achiev-
ing and preserving a superior F1-Score at @N and
@2N. Firstly, context-driven markers associated with
lower levels of ambiguity, significantly influence the
extraction process of the agent. For instance, markers
#1, #4 and #5 have usually been sufficient per se for
determining whether a term (under the conditions of
each marker) is relevant or not. Secondly, context-
driven markers with medium ambiguity levels tend
to reduce their associated cognitive uncertainty, when
used together with other markers. Thirdly, we ob-
served that the inclusion of cognitive uncertainty mea-
sures to determine trust degrees, allowed the agent
to control the relative ambiguity associated to some
markers as #12.
Finally, our results reflect the complexity of ex-
tracting relevant terms from short documents such as
JAs. Work on YAKE! had already evidenced this is-
sue on corpora made up of short length documents.
Various corpora were involved in their work, e.g.,
WWW, KDD and pak2018 (Campos et al., 2018). In
our case, YAKE! has a similar behavior (18%) when
compared to its reported maximal of 17.2% for these
datasets of short documents. On the other hand, a
maximal F1-Score@2N of 5% and 14% for RAKE
(n-gram) and BERT (embeddings) respectively, could
be attributed to the inadequacy of document repre-
sentations to reproduce the concepts of an organiza-
tional context. In fact, the n-gram approach tends to
underrepresent terms, while the embedding approach
may not be aligned with the inherent knowledge of a
given organizational context, even after a fine-tuning
process. It also appears that the FRAKE algorithm
FCTA 2022 - 14th International Conference on Fuzzy Computation Theory and Applications
172

is limited by the short length of JAs, given that it is
centered on statistical graph-based markers. Accord-
ing to these elements, with a maximal F1-Score of
38%, the performance of our approach illustrates that
context-driven markers can complement relevance in-
formation extraction in JAs, by integrating knowl-
edge of the specific organizational context, from a re-
cruiter’s perspective.
6 DISCUSSION
The automatic extraction of relevant terms from JAs
is a complex task that has been rarely studied, despite
its key role to determine the ranking of CVs during
the screening phase of recruitment. We propose an
approach that relies on a multisource ontology and a
possibilistic framework, utilized by a dynamic BDI
agent model, to analyze simple rules that define 16
textual markers. Given the current lack of specific
approaches for this task, we compared our approach
to the closest related techniques, i.e., automatic term
extraction approaches for document indexing. Out
of 16 textual markers, we defined 10 markers upon
an expert recruiter’s strategies and viewpoints, while
6 were integrated from the YAKE! algorithm. Re-
sults show that the defined BDI agent performs better
than automatic term extraction algorithms, in extract-
ing relevant information from JAs. Obtained perfor-
mances suggest that representing the organizational
context of JAs, in terms of recruiter’s strategies and
viewpoints, is likely to improve the identification of
information relevance, beyond relevant terms.
Also, we observed that our implementation is
likely to detect more coherent sets of relevant terms
than other approaches. Given that the agent extracts
terms following a terminological analysis (Frantzi
et al., 2002; Cram and Daille, 2016), it detects com-
plex terms often chosen as relevant by recruiters. Be-
sides, we observed that some textual representations,
such as the one proposed by RAKE (Rose et al.,
2010), underrepresent complex terms, reducing pre-
dictability considerably.
An overview of results reveals that performance
measures of all algorithms, except Recall@2N of our
algorithm, are below the expected baseline perfor-
mance. This can be explained by the fact that statisti-
cal markers on which are based the works of (Campos
et al., 2018) (Rose et al., 2010) (Zehtab-Salmasi et al.,
2021) are insufficient to determine appropriately term
relevance in JAs. Our results show that context-based
qualitative relevance markers are essential for achiev-
ing a better F1-score, given that they are independent
of the JA’s size. E.g., it is not unusual to find JAs
where the extent of the enterprise description is large
compared to the job description. As a consequence,
statistical markers tend to give a higher score to terms
from the former section that aren’t necessary to de-
scribe essential job requirements.
After performing combinatorial analysis of tex-
tual markers, we found that the agent gets a bet-
ter F1-score by executing textual markers as follows.
The first step is to generate a population of beliefs
about terms relevance, using independent markers
with lower ambiguity levels. For instance, marker #1
based on titles contents or marker #6 focused on fi-
nancial impact of professional skills/activities. Then,
dependent markers with low ambiguity levels (such as
#10) can be applied in order to reinforce the current
population’s beliefs about terms relevance.
7 CONCLUSION AND
PERSPECTIVES
Multiple analyses and resources are necessary to au-
tomatize a recruitment process. While a rich ontology
is essential to cover the wide spectrum of professional
qualifications, skills, and experience, the study of JAs
permits to identify relevant terms intended to facilitate
CV ranking. Additionally, the ambiguity of employed
language must also be taken into account. Since sta-
tistical parameters do not provide optimal representa-
tions of relevant document terms in a JA, we propose
to correlate human decisions with identified textual
markers. This approach relies strongly on termino-
logical analysis and hypotheses formulated after ob-
serving how recruiters work. Our results indicate that
the terminological analysis is a fundamental step for
improving the linguistic quality and contextual rele-
vance of information extraction from JAs. Our frame-
work has therefore the potential to assess the rele-
vance of text markers within specific contexts, and to
be adapted to the evolving organizational context of
each company.
Further work is still required to confirm the var-
ious insights that have been identified, in particular
concerning recruiters’ way of working when match-
ing JAs and CVs, as well as the relevance of other
models to represent the semantic space of relevant
terms. A larger corpus and more recruiters will be
necessary to evaluate whether the applicability of tex-
tual relevance markers can be affected by variations
in the organizational context. Compatible automatic
approaches to identify relevant terms in CVs to match
JAs are foreseen, integrating the recruiter’s expertise.
Other machine learning models will be defined look-
ing for a more precise representation of the intrin-
An Ontology-based Possibilistic Framework for Extracting Relevant Terms from Job Advertisements
173

sic and extrinsic relationships between the concepts
constituting a specific organizational context in which
JAs are processed.
REFERENCES
Alfonso-Hermelo, D., Langlais, P., and Bourg, L. (2019).
Automatically Learning a Human-Resource Ontology
from Professional Social-Network Data. In Canadian
AI 2019: Advances in Artificial Intelligence, volume
11489 of LNAI, pages 132–145. Springer.
Breaugh, J. A. (2013). Employee Recruitment. Annual Re-
view of Psychology, 64:389–416.
Cabrera-Diego, L. A., El-B
´
eze, M., Torres-Moreno, J. M.,
and Durette, B. (2019). Ranking r
´
esum
´
es automati-
cally using only r
´
esum
´
es: A method free of job offers.
Expert Systems with Applications, 123:91–107.
Campos, R., Mangaravite, V., Pasquali, A., Jorge, A. M.,
Nunes, C., and Jatowt, A. (2018). YAKE! Collection-
Independent Automatic Keyword Extractor. In Ad-
vances in Information Retrieval, pages 806–810.
Springer.
C¸ elik, D. (2016). Towards a semantic-based information
extraction system for matching r
´
esum
´
es to job open-
ings. Turkish Journal of Electrical Engineering and
Computer Sciences, 24(1):141–159.
Cram, D. and Daille, B. (2016). Terminology extraction
with term variant detection. In Proceedings of ACL-
2016 system demonstrations, pages 13–18.
Da Costa Pereira, C. and Tettamanzi, A. G. B. (2010). An
integrated possibilistic framework for goal generation
in cognitive agents. In Proceedings of the 9th Interna-
tional Conference on Autonomous Agents and Multia-
gent Systems: Volume 1, pages 1239––1246.
Dagli, R., Shaikh, A. M., Mahdi, H., and Nanivadekar, S.
(2021). Job Descriptions Keyword Extraction using
Attention based Deep Learning Models with BERT.
In 3rd International Congress on Human-Computer
Interaction, Optimization and Robotic Applications
(HORA), pages 1–6.
Deng, Y., Lei, H., Li, X., and Lin, Y. (2018). An im-
proved deep neural network model for job matching.
In 2018 International Conference on Artificial Intelli-
gence and Big Data (ICAIBD), pages 106–112.
Frantzi, K. T., Ananiadou, S., and Tsujii, J. (2002). The
C-value/NC-value Method of Automatic Recognition
for Multi-word Terms. Research and Advanced Tech-
nology for Digital Libraries, 1513:585 – 604.
Guo, S., Alamudun, F., and Hammond, T. (2016).
R
´
esuMatcher: A personalized r
´
esum
´
e-job matching
system. Expert Systems with Applications, 60:169–
182.
Kessler, R., B
´
echet, N., Roche, M., Torres-Moreno, J. M.,
and El-B
`
eze, M. (2012). A hybrid approach to manag-
ing job offers and candidates. Information Processing
and Management, 48(6):1124–1135.
Kiselyova, E. I., Koroshchenko, K. R., and Robson, G.
(2021). Legal Horizons Content of the Job Descrip-
tion: Features and Areas of Concern. Legal Horizons,
14(2):63–69.
Le Vrang, M., Papantoniou, A., Pauwels, E., Fannes, P.,
Vandensteen, D., and De Smedt, J. (2014). ESCO:
Boosting job matching in Europe with semantic inter-
operability. Computer, 47(10):57–64.
Martin Jr., D., Prabhakaran, V., Kuhlberg, J., Smart, A.,
and Isaac, W. S. (2020). Extending the Machine
Learning Abstraction Boundary: A Complex Sys-
tems Approach to Incorporate Societal Context. arXiv
2006.09663.
Mc Gurk, S., Abela, C., and Debattista, J. (2017). To-
wards Ontology Quality Assessment. http://ceur-ws.
org/Vol-1824/ldq paper 2.pdf.
Pavlick, E. and Kwiatkowski, T. (2019). Inherent disagree-
ments in human textual inferences. Transactions of
the Association for Computational Linguistics, 7:677–
694.
Reimers, N. and Gurevych, I. (2019). Sentence-BERT: Sen-
tence Embeddings using Siamese BERT-Networks.
In Proceedings of the 2019 Conference on Empiri-
cal Methods in Natural Language Processing, pages
3982–3992. Association for Computational Linguis-
tics.
Rose, S., Engel, D., Cramer, N., and Cowley, W. (2010).
Automatic Keyword Extraction from Individual Docu-
ments, chapter 1, pages 1–20. John Wiley and Sons.
Roy, P. K., Chowdhary, S. S., and Bhatia, R. (2020). A Ma-
chine Learning approach for automation of Resume
Recommendation system. Procedia Computer Sci-
ence, 167:2318–2327.
Somodevilla Garc
´
ıa, M., Vilari
˜
no Ayala, D., Pineda, I., So-
modevilla Garc
´
ıa, M., Vilari
˜
no Ayala, D., and Pineda,
I. (2018). An Overview of Ontology Learning Tasks.
Computaci
´
on y Sistemas, 22(1):137–146.
Wang, X., Jiang, Z., and Peng, L. (2021). A Deep-Learning-
Inspired Person-Job Matching Model Based on Sen-
tence Vectors and Subject-Term Graphs. Complexity,
2021:1–11.
Yuan, Y. and Shaw, M. J. (1995). Induction of fuzzy deci-
sion trees. Fuzzy Sets and Systems, 69(2):125–139.
Zapata Jaramillo, C. M. and Arango Isaza, F. (2009). The
UNC-method: a problem-based software develop-
ment method. Ingenier
´
ıa e Investigaci
´
on, 29:69–75.
Zehtab-Salmasi, A., Feizi-Derakhshi, M.-R., and Balafar,
M.-A. (2021). FRAKE: Fusional Real-time Auto-
matic Keyword Extraction. arXiv 2104.04830.
Zhao, J., Wang, J., Sigdel, M., Zhang, B., Hoang, P., Liu,
M., and Korayem, M. (2021). Embedding-based Rec-
ommender System for Job to Candidate Matching on
Scale. arXiv 2107.00221v1.
Zhu, C., Zhu, H., Xie, F., Ding, P., Xiong, H., Ma, C., and
Li, P. (2018). Person-Job Fit: Adapting the Right Tal-
ent for the Right Job with Joint Representation Learn-
ing. ACM Transactions on Management Information
Systems, 9:1–17.
FCTA 2022 - 14th International Conference on Fuzzy Computation Theory and Applications
174
