
Cooking Reviews Segmentation and Classification based on
Deep Learning and Named Entity Detection
Randa Benkhelifa
1a
and Nasria Bouhyaoui
2,1 b
1
Laboratoire de L'intelligence Artificielle et des Technologies de L’information, Université Kasdi Merbah,
Route de Ghardaia BP.511, 30 000, Ouargla, Algeria
2
Ecole Normale Supérieure de Ouargla, Ouargla, Algeria
Keywords: Text Segmentation, Text Classification, Online Social Network, YouTube, Cooking, Named Entity Detection,
Sentiment Analysis.
Abstract: YouTube is one of the most used online social networking (OSN) websites for exchanging recipes. It allows
uploading them, searching for, downloading, as well as rating and reviewing them. Sentiment analysis for
food and cooking recipes comments is to identify what people think about such cooking recipe video through
users’ comments. Nowadays, users’ give their opinion not only about recipes; they also evaluate the cook
through their comments, where a cook’s reputation can affect the users' opinion about his cooking recipes.
Frequently, when a cook has a good reputation, his recipes receive a great success by people, and vice versa.
In this paper, we propose a new approach that deal with the sentiment classification of cooking reviews.
Firstly, we examine the benefit of performing named entity detection and conjunctions on our corpus for text
segmentation in order to divide the comment on segments concerning the cook and segments concerning the
recipe. Next, we make two sentiment classifications (about the cook and about the recipe). Finally, we
incorporate the polarity of the cook sentiment classification in the recipe sentiment classification in order to
analyse the effect of the opinion about the cook on the performance of the categorization of the shared cooking
recipes comments in OSNs.
1 INTRODUCTION
Today, social networks such as Facebook, Twitter
and YouTube have become an essential element in
our daily life. Indeed, they are increasingly used to
convey messages and ideas through generating tons
of data on users and their interactions. The
importance of this data is that it contains a good
fraction of opinionated posts. Analyzing these posts
can reveal how users feel about certain topics, or
issues, events, products, people, recipes, etc.
Sentiment analysis is the field that allows the
treatment of users’ emotions and feeling. The
sentiment analysis is the process of determining
whether a piece of subjective writing is positive or
negative.
YouTube is a public video-sharing website where
people can share their experience and opinions in
order to maintain social relationships. One of the most
a
https://orcid.org/0000-0002-5577-4332
b
https://orcid.org/0000-0002-9810-3061
popular videos is the cooking videos, where, people
can upload, search for, download, as well as rate and
review recipes. Sentiment analysis of food recipe
comments is to identify what do people think about
such cooking recipe video through user’s comments
(positive or negative comments), where it is
interesting to predict their ratings automatically
(Benkhelifa and Laallam, 2018).
Frequently, the user does not give his/her opinion
only to evaluate the recipe; the user also gives his/her
opinion to evaluate the chef or the cook who prepared
this recipe. Sometimes, the judgment attributed to the
person who cook effects the opinion about the
cooking recipe.
Several papers over the years studied users’
opinions based on the textual content shared by them
in online social networks. The majority of the
previews works (Benkhelifa and Laallam, 2018). The
authors (Benkhelifa, et al., 2019) have focused on the
Benkhelifa, R. and Bouhyaoui, N.
Cooking Reviews Segmentation and Classification based on Deep Learning and Named Entity Detection.
DOI: 10.5220/0011542300003318
In Proceedings of the 18th International Conference on Web Information Systems and Technologies (WEBIST 2022), pages 337-343
ISBN: 978-989-758-613-2; ISSN: 2184-3252
Copyright
c
2022 by SCITEPRESS – Science and Technology Publications, Lda. All rights reserved
337

comments about the recipe ignoring user's opinion
about the cook, which can play an important role in
user opinion about the recipe.
In order to be able to process every part of opinion
separately; a part concerning the recipe and a part
concerning the cook, it is necessary to split the review
on segments. Text segmentation is a method of
splitting a document into smaller parts (Pak and Teh,
2018). This study is interested in only two types of
entities, which are person and recipe. Concerning
Person entity detection, lot of methods can be used to
annotate them. To the best of our knowledge, there is
no previous research concerning Recipe entities
detection. Therefore, we have created a list that
contains a great number of words concerning Recipe
NE such as (recipe, food, ingredient, vegetables,
cake, meat, meal, calorie, etc.).
In this paper, we propose a new approach, which
segment the review social text into two parts: the part
talking about recipe and the part talking about the
cook. We examine the benefit of performing named
entity recognition (NER) to an English corpus used
for text segmentation. Next, we build two sentiment
classifications, one for the recipe and the other for the
cook. After that, we study the effects of incorporating
the polarity of cook sentiment classification in recipes
sentiment classification. Finally, the experiments
show the impact of incorporating the opinion about
the cook on the performance of the categorization of
the shared cooking recipes comments in OSNs.
The remainder of this paper is as follows. In
section 2, the related works are discussed. In section
3, we present our methodology including our
proposed approach. The section 4 represents the
details of the results applied to the dataset extracted
from YouTube, and finally, we present a conclusion
and perspectives in section 5..
2 RELATED WORKS
Online social networking has become a part of the
daily routine of a huge number of persons (Benkhelifa
and Bouhyaoui, 2021). Comments in social media has
reached a great interest in several works on opinion
mining and sentiment analysis.
2.1 Text Segmentation
Text segmentation is a traditional NLP task, which is
widely used in text processing phase. It allows to
automatically partitioning text into coherent
segments or units. Each segment has its relevant
significance. Those units can be categorized as word
(Wu et al., 2007), (Liu and Chen, 2015), (Xia et al.,
2009) and (Zhang et al., 2021), sentence (El-Shayeb
et al., 2007), (Zhu et al., 2009), (Benkhelifa, et al.,
2019) and (Wicks and Post, , 2021), topic (Fragkou,
2013), (Ehsan and Shakey, 2016), (Memon et al.,
2021), (Lo et al., 2021), (Koshorek et al., 2018) and
(Maraj et al., 2021) or any information unit depending
on the text analysis task. The authors in (Memon et
al., 2021) have proposed a new topic-modelling-
based ensemble clustering approach, inducing the
combination of text segmentation and text clustering.
They have presented a cutting of a document into
segments (i.e. sub-documents), wherein each sub-
document is associated with exactly one sub-topic.
The work in (Lo et al., 2021), the authors have built
supervised neural text segmentation model in the
educational domain. A novel supervised training
procedure with a pre-labeled text corpus along with
an improved neural Deep Learning model for
improved predictions has been proposed in (Maraj et
al., 2021).
Recently, in text segmentation, many works such
as (Koshorek et al., 2018) and (Maraj et al., 2021)
have focused on supervised methods, which this is
formulated as a supervised learning problem
(Koshorek et al., 2018). The supervised methods have
solved two main drawbacks of the unsupervised
algorithms, which are the difficulty of specializing for
a given domain and in most cases, the unsupervised
methods do not naturally deal with multi-scale issues.
In addition, sentiment analysis has used text
segmentation in order to identify the polarity of each
segment. The authors in (Zhu et al., 2009) and
(Benkhelifa, et al., 2019) have used segmentation in
their model to identify multiple polarities and aspects
within one sentence. A novel method for aspect based
sentiment analysis, with an adaptation of LDA
Sentence Segmentation algorithm for product aspect
extraction has been proposed in (Ozyurt and Akcayol,
2021).
One of the essential and basic tasks of information
extraction and NLP is named entity recognition
(NER). Hence, the term ‘Named Entity’, is now
commonly used in NLP (Ramzi et al., 2017). NER is
the task of extracting, locating and classifying named
entities in a given piece of text. The named entity can
be a proper noun, a numerical expression which
represents type unit or monetary value, or a temporal
value which represents time. The classification of a
proper noun can be divided into three categories,
namely a person, a location, or an organization.
WEBIST 2022 - 18th International Conference on Web Information Systems and Technologies
338
2.2 Sentiment Classification
Recently, sentiment analysis is considered as the
process of finding users opinion about a particular
topic (Vijay et al., 2014). It performed on different
domain data such as Movie (Zhang and Zhu, 2006),
Books and Products (Dave et al., 2014), (Hu and Liu
, 2004), (Tan and Na, 2017) , Restaurants (Jingjing et
al., 2012), and cooking recipes (Liu, et al., 2014)
(Ning et al., 2013) (Benkhelifa, et al., 2019)
(Benkhelifa and Laallam, 2018), etc. The authors in
(Pugsee and Niyomvanich, 2015) have shown that the
reviews are the best rating predictors, in comparison
to ingredients, preparation steps, and metadata. Based
on users' reviews, various strategies for predicting
recipe ratings has been explored by the authors in
(Liu, et al., 2014). In order to improve the food
recipes a suggestion analysis method is proposed by
the authors in (Ning et al., 2013). A sentiment based
rating approach for food recipes using sorts food
recipes present on various websites from sentiments
of review writers is proposed in (Rao and Kakkar,
2017). The work in (Bianchini, et al., 2017) propose
a menu generation system is described, that takes into
account both user's preferences and healthy nutrition
habits. Another related research about food recipe
comments (Benkhelifa and Laallam, 2018) has
develop a real-time system to extract and classify the
YouTube cooking recipes reviews automatically.
This research has used the social media text
characteristics to improve the system performance.
The authors in (Benkhelifa, et al., 2019) has
introduced a sentiment based real-time system which
mines YouTube meta-data (Likes, Dislikes, views
and comments) in order to extract important cooking
recipes features and identify opinions polarity
according to these extracted features. Here we are
interested to show the effect of the cook’s reputation
on his cooking recipes reviews.
3 METHODOLOGY
The methodology followed in this work is presented
in this section. We start by introducing the description
of the process; how our method works.
3.1 Process
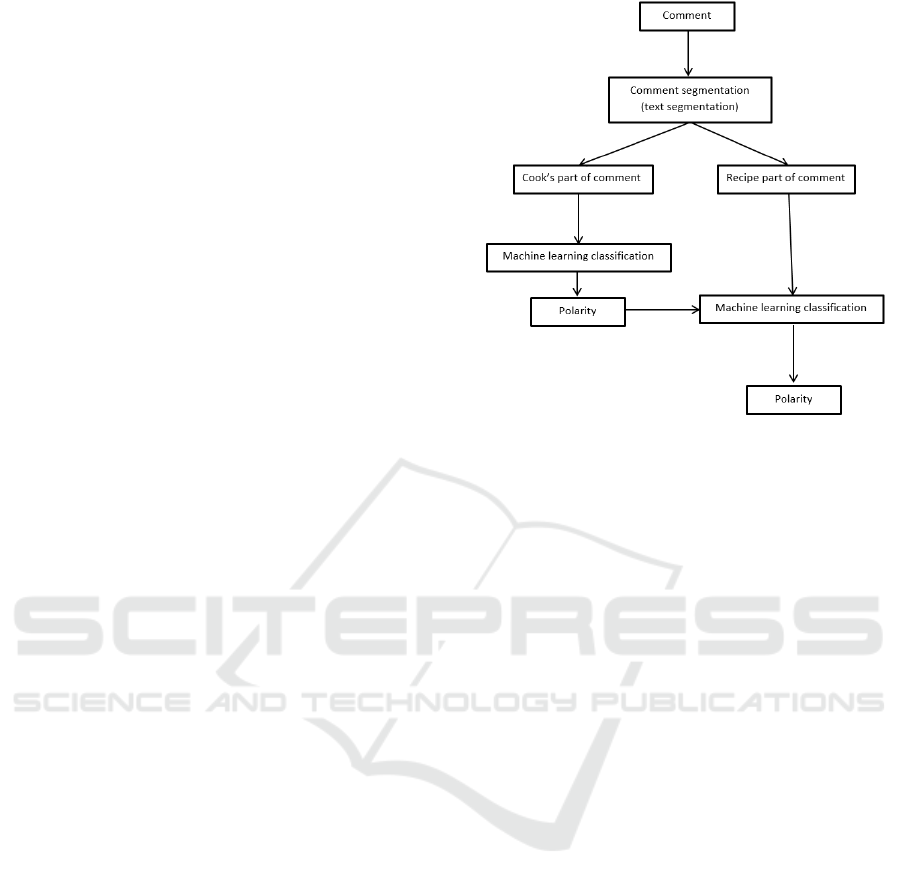
The process of the proposed approach is shown in
Figure 1.
Our method separates the comment on two parts
(cook’s review part and cooking review) using
text segmentation techniques. Then, we apply the
Figure 1: The process of the proposed approach.
sentiment classification on cook’s part comment. The
obtained polarity is combined to recipe review text
for recipe sentiment classification.
Comment: it represents a short social text
extracted from the well-known social network
YouTube, where any person can access and express
his/her opinion freely.
Comment segmentation: the segments of a
comment are divided into two bags, cook’s bag: this
bag represents the text review concerning the cook,
for example: “I love the way you cooked and smile
amazing chef!”. Where the second part represents
recipe bag, which reflect the user’s opinion about the
recipe itself, for example: “I want to eat this, Looking
delicious”.
After that, we look for the polarity of the cook’s
part comments; the value of this polarity is included
to the recipe sentiment classification process.
Here, we build the machine learning recipe
sentiment classification, the classifiers are not based
only on the textual content concerning the recipe they
consider also the value of the polarity of the cook’s
parts of comment, this value is token as input of the
classifier beside of the textual content.
3.2 Text Segmentation Approach
To build a robust system of comments segmentation,
we propose to use a supervised segmentation based on
named entity recognition. This study is interested in
only two types of entities, which are person PER
(representing the cook) and recipe REC. The other
entities (that does not describe a person, or a recipe)
including all other types of named entities NE such a
Cooking Reviews Segmentation and Classification based on Deep Learning and Named Entity Detection
339
location, an organization, etc. are not taken into
account. Concerning Person entity detection, lot of
methods can be used to annotate them. To the best of
our knowledge, there is no previous research
concerning Recipe entities detection. Therefore, we
have created a list that contains a great number of
words concerning Recipe NE such as (recipe, food,
ingredient, vegetables, cake, meat, meal, calorie, etc.).
3.2.1 Text Segmentation Process
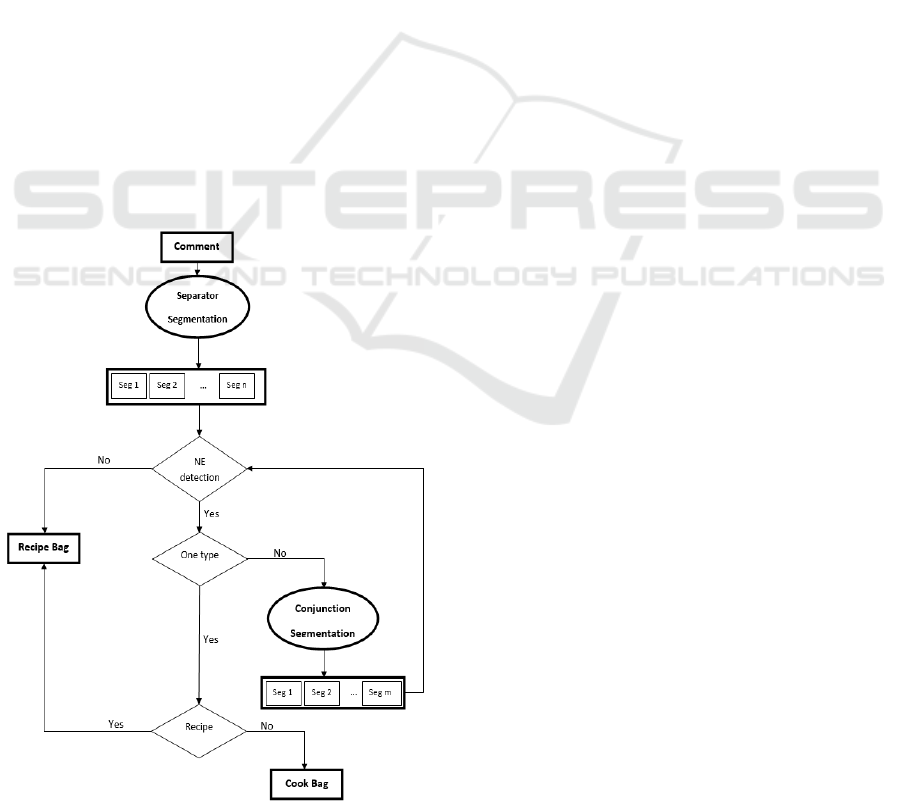
Our approach of segmentation is described by an
Algorithm, which is constituted of the following steps
as illustrated in Figure 2:
• Step 1: we use a separator segmentation: the
comment is split according to the punctuation.
• Step 2: for each segment, we detect the NE. If the
segment does not contain NE, we put it in the
recipe bag. Else, if the segment contains only one
type of NE, we put it in the bag of this entity type.
• Step 3: if the part of the comment contains more
than one kind of named entity, we split this
segment according to the conjunctions (except the
“and” conjunction, which is removed in the
preprocessing step). The result obtained could be
two segments or more. In order to categorize each
obtained segment into the adequate bag, we return
to the step 2.
Figure 2: The process of comment segmentation.
• As an output, we get two sets (bags) of segments
for each NE type (a cook’s bag and a recipe bag).
3.2.2 Text Segmentation Algorithm
Here, we give some notations. Suppose our dataset D
has
n Comments. Each comment c in C is segmented
to a set of part (unit) p in P. Each unit p has a label l
from L={l
per
,l
rec
}. Where l
per
represents the unit
talking about the cook, and l
rec
is the label of the
recipe unit.
Algorithm comment_segmentation{
Inputs: a set of comments C, a set of
parts P, boolean b, a set of Named
Entities NE, a set of labels L;
Output: a cook bag Pper, a recipe bag
Prec;
For each comment c in C Do {
P= separator_segmantation(c);
}
For each part p in P Do{
b=Detect_entity(p);
if b==no then{
put p in Prec;
}
else{
NE=annotate (p);
if (same_label l(NE)==yes)
then{
if l(E)==REC then {
put p in Prec
}
else{
put p in Pper
}
}
else{
Conjunction segmentation;
Goto line 10;
}
}
Output (Prec, Pper);
}.
4 EXPERIMENTS
4.1 Dataset Collection and
Construction
This section presents the dataset used in this work for
both segmentation and classification. The main
objective of this work is to segment and classify
cooking reviews. Moreover, to study the effect of
cook’s reputation on the users' opinion about his
cooking recipes and to show how much it is important
WEBIST 2022 - 18th International Conference on Web Information Systems and Technologies
340

to consider this information in the classification
process. YouTube comments are perfect for these due
to their abundance and a short length. Moreover,
YouTube is a popular video social network with a
great diversity of users, which means that collecting
a sufficiently large dataset with those characteristics
on various topics is feasible. To ensure the
consistency and the reliability of our proposed
approaches, we tested our classification and method
on a collection of 10000 recent texts of YouTube
comments about videos of cooking recipes collected
between (May and August 2016) from many
YouTube videos. Three human annotators as
following annotated these texts manually: for creating
the training model of the sentiment classification
(5000 positive and 5000 negative). Cooking recipe
corpus and its annotations guideline had been
originally defined in (Benkhelifa and Laallam, 2018).
4.2 Data Pre-processing
Preprocessing 1: it represents the prepressing, which
is applied before the segmentation algorithm.
1. Removing {and}, in the most cases the
conjunction “and” is used for listing several
description of the same entity for example
“she’s always happy and positive”.
2. Removing all words that can be annotated as
Person but do not represent the cook and
generally those words concern the comment
author such as {I, My kids, My family, etc.}
Preprocessing 2: it represents the prepressing, which
is applied before the classifications.
3. A term that appears less than three (3) times is
removed;
4. Removing punctuation (.,!?) and symbols
([<>());
5. The stemmer employed is the lovenStemmer,
which is used in the literature.
4.3 Evaluation Metrics
We adopt PK, the standard evaluation metric for text
segmentation for reporting the results of the prosed
text segmentation. PK score is the percentage of
wrong predictions on whether or not the first and last
sentence of a randomly sampled snippet of k
sentences belong to the same segment. Following the
previous works, we set k to the half of the average
ground truth segment size of the dataset.
Evaluation metrics for sentiment classifications
We now evaluate the performance of our method
by evaluating the performance of machine learning
training models, F-Measure (F) is one of the standard
metrics employed for evaluating our machine
learning models, this metric includes two
fundamental factors, i.e., precision (P) and recall (R),
which are obtained from the following relations:
P=TP/(TP+FP) (1)
R=TP/(TP+FN) (2)
F1=2*R*P/(R+P) (3)
5 RESULTS AND DISCUSSION
5.1 Text Segmentation Results
After the segmentation phase, we have gotten 12% of
PK.
We did not compare the obtained PK result with
the other researches, and this is because our main
objective is not the comment segmentation. In this
work, we are interested in the review sentiment
classification. The classification process required the
performing of text segmentation.
5.2 Sentiment Classification Results
Deep learning algorithms Convolutional Neural
Networks (CNN), and Recurrent Neural Networks
(LSTM, and bi-LSTM) are used for both sentiment
classifications. The first layer of each of these models
is a word embedding layer that turns sentences into a
feature map.
We start by showing the results of the cook’s
sentiment classification.
Table 1: Cook’s sentiment classification results.
Measure
Classifier
P R F
bi-LSTM
0.923 0.857 0.888
LSTM
0.888 0.843 0.865
CNN
0.86 0.86 0.86
The best F-measure result is 0.888. It has been
gotten using bi-LSTM classifier.
Now, we show the results obtained by cooking
recipes sentiment classification using three deep
learning algorithms CNN, LSTM, and bi-LSTM with
and without cook’s classification polarity.
TC: Textual Content.
OC: Opinion about cook.
Cooking Reviews Segmentation and Classification based on Deep Learning and Named Entity Detection
341
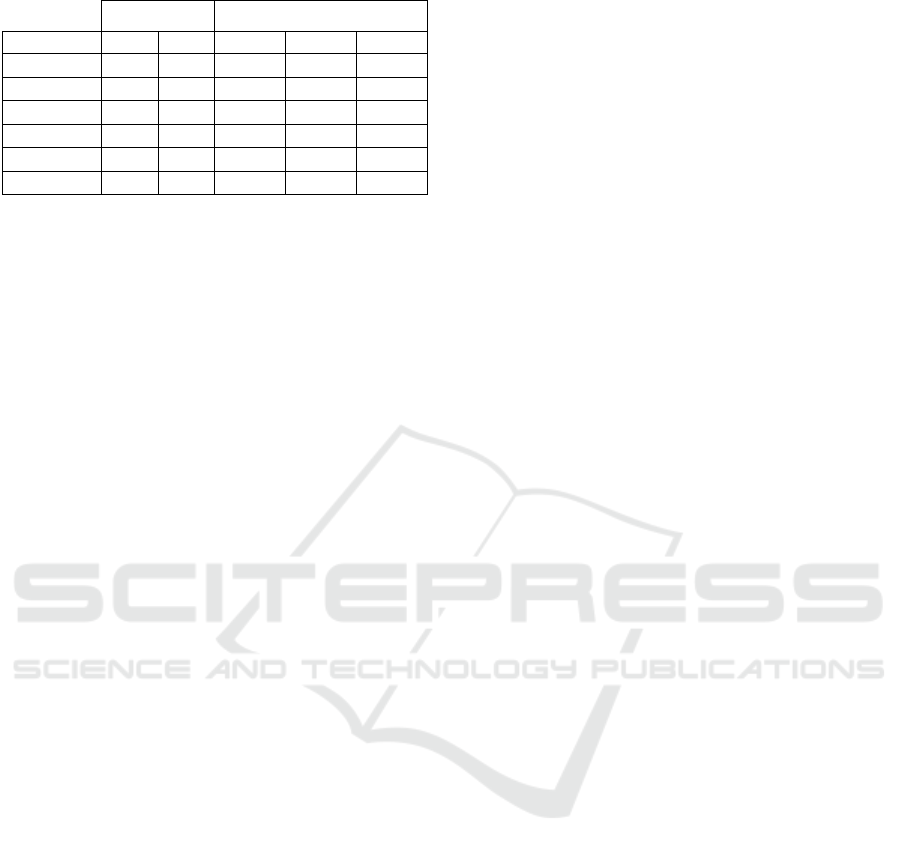
Table 2: Recipe sentiment classification results.
Features Measure
Classifier TC OC P R F
CNN •
0.789 0.788 0.786
CNN • •
0.82 0.82 0.82
Bi-LSTM •
0.789 0.787 0.787
Bi-LSTM • •
0.83 0.826 0.825
LSTM •
0.82 0.811 0.81
LSTM • •
0.84 0.83 0.83
Comparison between the Gotten Results.
The highest results we got are 0.84 in precision, 0.83
in recall and 0.83 in F measure including both recipe
textual content and opinion about the cook using
LSTM classifier. Firstly, we have based only on the
textual content extracted comment concerning from
recipes without considering the opinion about the
cook, we got these classifiers precisions, recalls and
F-measures respectively, 0.789, 0.788, and 0.786
using CNN, 0.789, 0.787, 0.787 using bi-LSTM and
0.82, 0.81, and 0.81 using LSTM.
Including opinion about the cook (polarity value)
in the classification process, we remark an
improvement of 0.031 in precision, 0.032 in recall
and 0.034 in F-measure using CNN classifier, where
using bi-LSTM, we got an improvement of 0.041 in
precision, 0.039 in recall, and 0.04 in F-measure. The
LSTM classifier has gotten an improvement of 0.02,
0.019 and 0.02 in precision, recall and F-measure
respectively.
6 CONCLUSIONS AND FUTURE
WORK
In this paper, we have focused on text segmentation
and classification; we have proposed a new approach
of cooking comments segmentation based on deep
learning and NER. Where the segmentation has
gotten good results. In addition, we have shown the
impact of incorporating the opinions about the cook
on the performance of the classification of the recipes
comments extracted from YouTube. Thus, we
conclude that this integration has a good impact and
it plays a crucial role in improving the performance
of the recipes comments classification.
Future works: As a future extension of this work,
we plan to explore other characteristics for text
segmentation. We will also propose other approaches,
to improve the performance of OSNs text
classification.
ACKNOWLEDGEMENTS
This work was financially supported by "La Direction
Générale de la Recherche Scientifique et du
Développement Technologique (DGRSDT)" of
Algeria.
REFERENCES
Benkhelifa, R., & Laallam, F. Z. (2018, February). Opinion
extraction and classification of real-time youtube
cooking recipes comments. In International
Conference on Advanced Machine Learning
Technologies and Applications (pp. 395-404).
Springer, Cham.
Benkhelifa, R., & Bouhyaoui, N. (2021). Deep approach
based on user’s profile analysis for capturing user’s
interests. In International Conference on Artificial
Intelligence and its Applications (pp. 177-186).
Springer, Cham.
Benkhelifa, R., Bouhyaoui, N., & Laallam, F. Z. (2019). A
Real-Time Aspect-Based Sentiment Analysis System
of YouTube Cooking Recipes. In Machine Learning
Paradigms: Theory and Application (pp. 233-251).
Springer, Cham.
Bianchini, D., De Antonellis, V., De Franceschi, N., &
Melchiori, M. (2017). PREFer: A prescriptionbased
food recommender system. Computer Standards &
Interfaces, 54, 64-75.
Liu C, Guo C, Dakota D, Sridhar Rajagopalan,Wen Li,
Sandra K¨ubler, (2014). “My Curiosity was Satisfied,
but not in a GoodWay: Predicting User Ratings for
Online Recipes”, Proceedings of the Second Workshop
on Natural Language Processing for Social Media
(SocialNLP), pages 12–21, Dublin, Ireland.
Dave K, Lawrence S, Pennock D. (2003). “Mining the
peanut gallery: opinion extraction and semantic
classification of product reviews”. Proceedings of the
12th international conference on World Wide Web,
ACM, New York, NY, USA, WWW‟03.
Hu M, Liu B. (2004). "Mining and summarizing customer
reviews". Proceedings of the 10th ACM SIGKDD
international conference on knowledge discovery and
data mining. ACM, New York, NY, USA, KDD.
Jingjing Liu, Stephanie Seneff, and Victor Zue, 2012.
"Harvesting and Summarizing User-Generated Content
for Advanced Speech-Based HCI", IEEE Journal of
Selected Topics in Signal Processing, Vol. 6, No. 8,
pp.982-992.
Ning Yu, Desislava Zhekova, Can Liu, and Sandra K ubler.
(2013). Do good recipes need butter Predicting user
ratings of online recipes. In Proceedings of the IJCAI
Workshop on Cooking with Computers, Beijing, China.
Pugsee P., and Niyomvanich M., (2015) “Suggestion
Analysis for Food Recipe Improvement,” Proceeding of
the 2015 International Conference on Advanced
WEBIST 2022 - 18th International Conference on Web Information Systems and Technologies
342

Informatics: Concepts, Theory and Application
(ICAICTA).
Rao, S., & Kakkar, M. (2017). A rating approach based on
sentiment analysis. In Cloud Computing, Data Science
& Engineering-Confluence, 2017 7th International
Conference on (pp. 557-562). IEEE.
Tan, S. S., & Na, J. C. (2017). Mining Semantic Patterns
for Sentiment Analysis of Product Reviews. In
International Conference on Theory and Practice of
Digital Libraries (pp. 382-393). Springer, Cham.
Vijay B. Raut et al. (2014). “Survey on Opinion Mining and
Summarization of User Reviews on Web,” (IJCSIT)
International Journal of Computer Science and
Information Technologies, Vol.5 (2), pp.1026- 1030.
Zhang X., and Zhu F., (2006). “The influence of Online
consumer reviews on the demand for experience goods:
The case of video games”, In 27th international
conference on information systems (ICIS), Milwaukee,.
AISPress, 2006.
Pak, I., & Teh, P. L. (2018). Text segmentation techniques:
a critical review. Innovative Computing, Optimization
and Its Applications, 167-181.
Memon, M. Q., Lu, Y., Chen, P., Memon, A., Pathan, M.
S., & Zardari, Z. A. (2021). An ensemble clustering
approach for topic discovery using implicit text
segmentation. Journal of Information Science, 47(4),
431-457.
Maraj, A., Martin, M. V., & Makrehchi, M. (2021). A More
Effective Sentence-Wise Text Segmentation Approach
Using BERT. In International Conference on
Document Analysis and Recognition (pp. 236-250).
Springer, Cham.
Lo, K., Jin, Y., Tan, W., Liu, M., Du, L., & Buntine, W.
(2021). Transformer over Pre-trained Transformer for
Neural Text Segmentation with Enhanced Topic
Coherence. arXiv preprint arXiv:2110.07160.
Koshorek, O., Cohen, A., Mor, N., Rotman, M., & Berant,
J. (2018). Text segmentation as a supervised learning
task. arXiv preprint arXiv:1803.09337.
Zhang, D., Hu, Z., Li, S., Wu, H., Zhu, Q., & Zhou, G.
(2021). More than Text: Multi-modal Chinese Word
Segmentation. In Proceedings of the 59th Annual
Meeting of the Association for Computational
Linguistics and the 11th International Joint Conference
on Natural Language Processing (Volume 2: Short
Papers) (pp. 550-557).
Wicks, R., & Post, M. (2021). A unified approach to
sentence segmentation of punctuated text in many
languages. In Proceedings of the 59th Annual Meeting
of the Association for Computational Linguistics and
the 11th International Joint Conference on Natural
Language Processing (Volume 1: Long Papers) (pp.
3995-4007).
Wu, Y., Zhang, Y., Luo, S. M., & Wang, X. J. (2007).
Comprehensive information based semantic orientation
identification. IEEE NLP-KE 2007 - Proc (pp. 274–
279). Beijing: Int. Conf. Nat. Lang. Process. Knowl.
Eng. IEEE.
Liu, S. M., & Chen, J.-H. (2015). A multi-label
classification based approach for sentiment
classification. Expert Systems with Applications, 42,
1083–1093.
Xia, Z., Suzhen, W., Mingzhu, X., & Yixin, Y. (2009).
Chinese text sentiment classification based on granule
network. In: 2009 IEEE International Conference on
Granular Computing GRC 2009 (pp. 775−778).
Nanchang: IEEE.
Fragkou, P. (2013). Text segmentation for language
identification in Greek forums. In: Proceedings of
Adaptation of Language Resources and Tools for
Closely Related Languages and Language Variants (pp.
23–29). Hissar: Elsevier B.V.
Ehsan, N., & Shakery, A. (2016). Candidate document
retrieval for cross-lingual plagiarism detection using
two-level proximity information. Information
Processing and Management, 52, 1004–1017.
Zhu J, Zhu M, Wang H, Tsou BK (2009) Aspect-based
sentence segmentation for sentiment summarization.
In: Proceeding 1st International CIKM Worshop. Top
Analysis mass Open.— TSA’09 (pp. 65–72). Hong
Kong: ACM New York, NY, USA ©2009.
El-Shayeb, M. A., El-Beltagy, S. R, & Rafea, A. (2007).
Comparative analysis of different text segmentation
algorithms on arabic news stories. In: IEEE
International Conference on Information Reuse and
Integration, Las Vegas (pp. 441–446).
Ramzi Salah, Lailatul Qadri Zakaria (2017) Arabic Rule-
Based Named Entity Recognition Systems Progress and
Challenges.
Ozyurt, B., & Akcayol, M. A. (2021). A new topic
modeling based approach for aspect extraction in aspect
based sentiment analysis: SS-LDA. Expert Systems
with Applications, 168, 114231.
Cooking Reviews Segmentation and Classification based on Deep Learning and Named Entity Detection
343
