
Predicting Reputation Score of Users in Stack-overflow with Alternate
Data
Sahil Yerawar
1
, Sagar Jinde
1
, P. K. Srijith
1
, Maunendra Sankar Desarkar
1
, K. M. Annervaz
2
and Shubhashis Sengupta
2
1
Indian Institute of Technology Hyderabad, India
2
Accenture Technology Labs, India
annervaz.k.m@accenture.com, shubhashis.sengupta@accenture.com
Keywords:
Recommendation System, Cold-start Recommendation, Knowledge Distillation, Transfer Learning.
Abstract:
The community question and answering (CQA) sites such as Stack Overflow are used by many users around
the world to obtain answers to technical questions. Here, the reliability of a user is determined using metrics
such as reputation score. It is important for the CQA sites to assess the reputation score of the new users
joining the site. Accurate estimation of reputation scores of these cold start users can help in tasks like
question routing, expert recommendation and ranking etc. However, lack of activity information makes it
quite difficult to assess the reputation score for new users. We propose an approach which makes use of
alternate data associated with the users to predict the reputation score of the new users. We show that the
alternate data obtained using users’ personal websites could improve the reputation score performance. We
develop deep learning models based on feature distillation, such as the student-teacher models, to improve
the reputation score prediction of new users from the alternate data. We demonstrate the effectiveness of the
proposed approaches on the publicly available stack overflow data and publicly available alternate data.
1 INTRODUCTION
A large majority of internet users refer to commu-
nity question answering (CQA) sites to gather infor-
mation, knowledge and general consensus views for
their own purposes. Examples of such CQA sites in-
clude Reddit, Stack Exchange, Quora etc. The suc-
cess of these community sites are mostly attributed to
efficient moderation of user questions and answers, as
well as the presence of a large number of users who
consistently provide high quality content. The relia-
bility of these consistent users is quantified by using
a points based system (Cavusoglu et al., 2015), where
the user is encouraged to interact with the community
by providing comments, posts, questions and answers
to earn their points which is also a measure of trust
and expertise. In Stack Overflow, the points earned
by the user are often called the reputation score (Over-
flow, 2022b). The reputation score of the users can be
utilized by the system to find expert users to answer
questions, rank the answers by users, and in provid-
ing some privileges. However, when a new user joins
the community QA website, due to lack of any regis-
tered activity, they will be assigned a very low repu-
tation score and consequently their expertise can not
be tapped completely by the system.
In this work, we aim to predict the reputation score
new users could have achieved, so that their expertise
can be fully utilized by the system to get expert an-
swers to the questions, and provide a better user ex-
perience (Slag et al., 2015). We address this by con-
sidering alternate data provided by users such as their
publicly available website information. In addition
to the activity based features like views, upvotes and
downvotes, stack overflow often contains user’s pro-
file information and publicly available website URLs
such as personal websites and GitHub accounts. We
believe that by leveraging the content of the personal
website, we can determine technical expertise, work
and education backgrounds of the user. Consequently,
this can be used to predict an approximate reputation
score, which can be used by the system to provide a
better user experience. This would help in providing a
fair estimate of the users’ expertise in the form of rep-
utation score, which can help in recommending new
users with a certain level of proficiency to different
questions in Stack Overflow. The proposed approach
addresses the cold start problem of assigning reputa-
Yerawar, S., Jinde, S., Srijith, P., Desarkar, M., Annervaz, K. and Sengupta, S.
Predicting Reputation Score of Users in Stack-overflow with Alternate Data.
DOI: 10.5220/0011591900003335
In Proceedings of the 14th International Joint Conference on Knowledge Discovery, Knowledge Engineering and Knowledge Management (IC3K 2022) - Volume 1: KDIR, pages 355-362
ISBN: 978-989-758-614-9; ISSN: 2184-3228
Copyright
c
2022 by SCITEPRESS – Science and Technology Publications, Lda. All rights reserved
355

tion scores for new users, which would help the down-
stream Recommender Systems for CQA websites.
To predict the reputation score of new users, we
develop deep learning models which could predict
the reputation score from the alternate data. Another
major contribution of our work is to develop effec-
tive deep learning models which learns not only from
the alternate data but also from the activity informa-
tion by treating them as privileged information and
performing feature distillation using a teacher-student
learning technique (Hinton et al., 2015; Lopez-Paz
et al., 2016; Xu et al., 2019). We propose an auto-
encoder based teacher and student model which al-
lows transfer of knowledge from a teacher network
trained on activity information and alternate data, to
a student network trained on alternate data alone. We
propose several ways to transfer the knowledge be-
tween teacher and student for effective learning. We
demonstrate first the usefulness of the alternate data
in predicting the reputation score. Following this,
we demonstrate the effectiveness of the proposed ap-
proaches in predicting the reputation score of the new
users.
The contributions of this paper are three-fold:
• We propose to use alternate data such as personal
website information to improve reputation score
prediction in stack overflow and use them in par-
ticular to predict reputation score for new users.
• We develop an auto-encoder based teacher and
student model and feature distillation techniques
to predict the reputation score of users from alter-
nate data.
• We conducted experiments on the publicly avail-
able stack overflow data and publicly available al-
ternate data, demonstrating usefulness of the al-
ternate data and proposed methodologies for rep-
utation score prediction.
2 RELATED WORK
2.1 Cold Start in Recommendation
Collaborative Filtering (CF) in Recommendation Sys-
tems have given good performances in recommending
items to users who have past user-item interaction his-
tory. Traditionally, Collaborative Filtering involves
matrix factorization to obtain low level embeddings
of user and item vectors. However, most CF algo-
rithms fail to work in the case of discovering inter-
actions between both new users and new items (Lam
et al., 2008; Park and Chu, 2009).
To alleviate the drawbacks of CF-based algo-
rithms in the context of cold start problem, many
researchers also utilize content information of these
users to formulate content based methods. These
methods try to learn an appropriate new user/item rep-
resentation based on content information and learn a
mapping to convert these representations into user-
item interaction vector space. However, these meth-
ods fail to model the complex nature of interaction be-
tween embedding space and the user content embed-
ding space, due to which a new user embedding can-
not associate with the embedding space. More recent
methods to address cold start problem involve a hy-
brid approach of using CF and content based methods
(Sujithra Alias Kanmani et al., 2021; ?), using meta-
learning (Zheng et al., 2021; Chen et al., 2021; Wang
et al., 2021a; Du et al., 2022), using pre-training (Hao
et al., 2021) etc. However, most of these approaches
aim to produce a good ranking of recommended items
for the end users, and do not focus on finding the true
value of the cold-start item or the true activity-based
user profile of the cold-start user.
2.2 Stack Overflow
Stack Overflow is one of the largest community
question-answer (CQA) websites, playing a crucial
role in the daily activities of numerous researchers,
developers and scholars all over the world. In Stack
Overflow, the point based system is known as rep-
utation score which can be earned by asking good
questions and providing answers on the Stack Over-
flow website. Subsequently, there have been numer-
ous studies on Stack Overflow reputation score and
how it behaves for different users. However, to the
best of our knowledge, there is no work which aims
to predict the reputation score of new users based on
the alternate data such as the website information.
Movshovitz-Attias et al. (Movshovitz-Attias
et al., 2013) studied participation patterns of expert
and non-expert users present in StackOverflow repu-
tation system. Their study concluded that influential
users have a good contribution during the first month
of activity and that expert users contribute drastically
more as soon as they join the site. They also found
that high reputation users were the primary sources of
high-quality answers. The study in Anderson et al.
(Anderson et al., 2012) looked at the way the com-
munity determines the answers, including how votes
are cast. The authors found that the answerer’s rep-
utation correlates with the speed of answers and that
the arrival time of an answer impacts its chances of
being chosen as the best one. In Slag et al. (Slag
et al., 2015), the authors found that no response to
KDIR 2022 - 14th International Conference on Knowledge Discovery and Information Retrieval
356

a question or unsatisfactory answer is the main issue
a new user faces. Due to this reason, the new users
may get demotivated and stop using the site. Their
analysis showed that half of them have just one con-
tribution on the site, and 60% of users have a reputa-
tion score of one. These points towards the need to
identify expert users early, get satisfactory answers,
provide more privileges, and encourage them to par-
ticipate in the QA site.
In Morrison et al. (Morrison and Murphy-Hill,
2013), the authors found a positive correlation be-
tween reputation score and age. They also examined
users’ familiarity with various skills and technolo-
gies using tags. MacLeod et al. (MacLeod, 2014)
performed an exploratory analysis of stack exchange
data. They found that the reputation score of a user is
positively correlated to the number of tags. Users with
high reputation scores contribute to a diverse number
of topics. Recent approaches to user reputation score
prediction (Woldemariam, 2020; Banati and Seema,
2021) made use of the textual content of the user posts
and its syntactic and semantic information in deter-
mining the reputation score of the users. Unlike all
these previous works, our aim is to develop an ap-
proach to predict the reputation score of cold start
users in the question answering sites.
3 BACKGROUND AND PROBLEM
DEFINITION
3.1 Features from the Dataset
In this work, we want to utilize stack overflow dataset
for identifying the user reputation scores. We try to
develop models that can predict the user’s reputation
scores based on the alternate data. This can help the
QA systems to make use of the expertise of new users
in providing relevant answers to questions posted by
users. We divide the features available in the stack
overflow dataset (Overflow, 2022a) as follows:
• Activity Information: The features reflect the ac-
tivity of the Stack Overflow user in the system. It
includes the number of views, number of upvotes
received, number of downvotes received and the
number of years the user has been active. We cal-
culate the number of years by subtracting the user
creation date from last accessed date present in
the dataset. We call these features the privileged
features which the QA systems use to compute the
reputation score. The new users joining the sys-
tem lack these features, while only old users will
have these features.
• About Me Text: Stack Overflow users can write
about themselves and their interest in a separate
section named ”About Me”. This textual data
could be utilized as our alternate data which pro-
vides an indication about the user’s capabilities.
All the data present in ”About Me” section is pub-
licly available.
• Website Text: In Stack Overflow, users can also
share their personal websites containing more in-
formation about their skill sets and achievements.
This textual data can act as another source of al-
ternate data which could be of great help in repu-
tation score prediction. All the data obtained from
personal websites are publicly available.
• Website Category: There are various kinds of
websites provided by the users. We make a broad
classification of these websites into three cate-
gories: Social media websites, Academic pages
and Personal blogs. We consider this information
also as part of the alternate data.
3.2 Problem Definition
We consider the problem predicting the reputation
score of a user y ∈ R , given their alternate data
based features X ∈ R
H
and privileged activity fea-
tures X
∗
∈ R
H
0
. Assume we are given a training
data set D = {X
i
, X
∗
i
, y
i
}
N
i=1
which consists of users
for whom both the privileged data and alternate data
are available (experienced users), and test data
ˆ
D =
{
ˆ
X
i
, ˆy
i
}
ˆ
N
i=1
which consists of users for whom only al-
ternate data are available, i.e. new users. We aim to
learn a regression model f : X → y to predict the rep-
utation score of users using alternate data, but also
make use of the availability of the privileged data X
∗
during training.
3.3 Learning using Privileged
Information
Standard machine learning and deep learning tech-
niques assume the same set of features to be avail-
able with all the users. However, it is different in
our case where we have a set of users for whom we
have activity (privileged) data while the rest does not
have. The recent works along the direction of learning
from privileged information (LUPI) (Pechyony and
Vapnik, 2010; Vapnik and Vashist, 2009; Vapnik and
Izmailov, 2015) have shown that making use of the
additional privileged features associated with some
subset of examples could improve the generalization
performance of the learning algorithms. Therefore,
Predicting Reputation Score of Users in Stack-overflow with Alternate Data
357
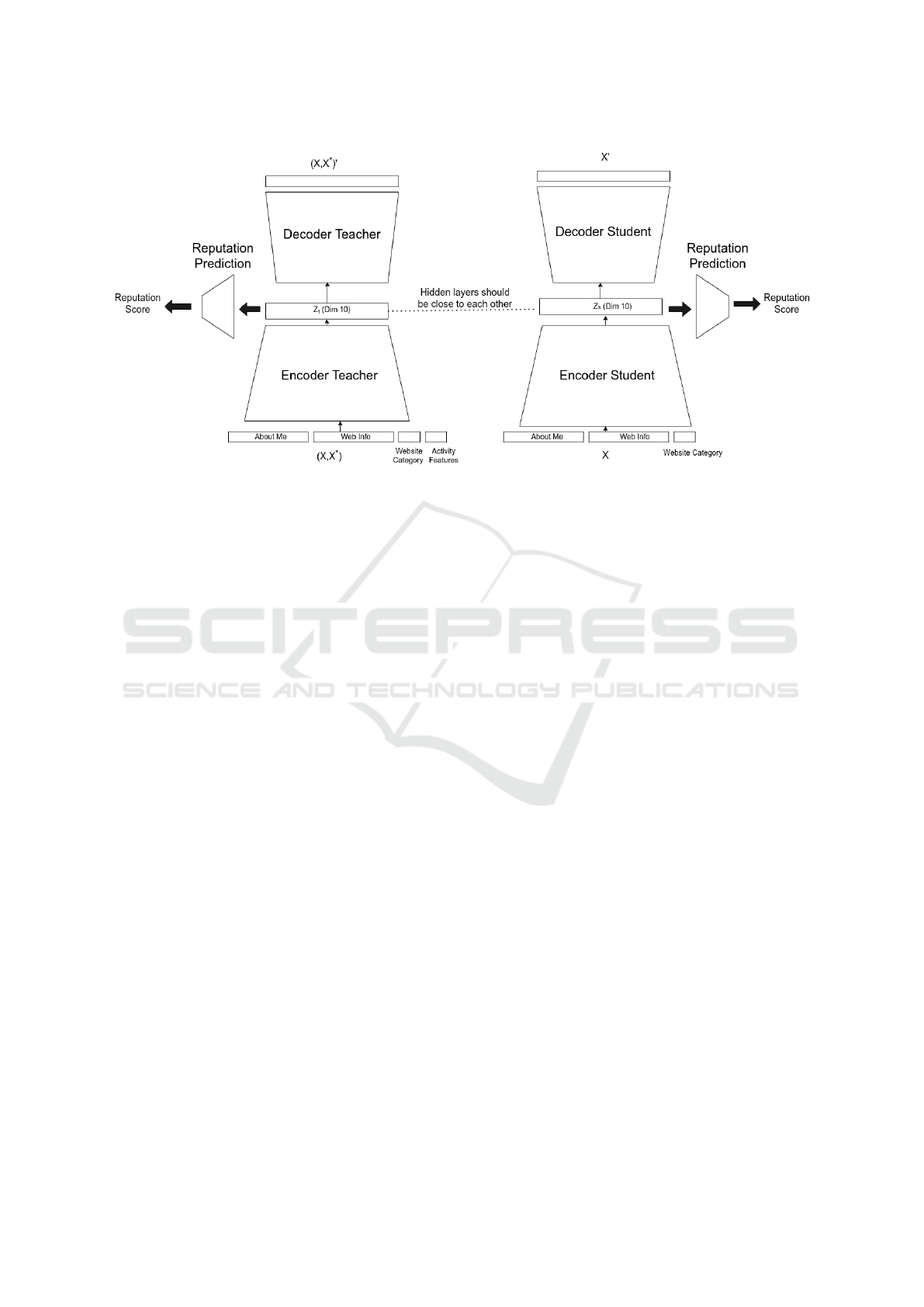
Figure 1: Model Architecture of Teacher and Student model with direct constraints on the latent representations.
we develop our models for reputation score predic-
tion using the framework of learning using privileged
information (Hinton et al., 2015; Lopez-Paz et al.,
2016) and more specifically the feature distillation ap-
proach (Xu et al., 2019; Wang et al., 2021b).
A more general framework of knowledge distilla-
tion has been used for several problems which involve
transfer of knowledge from one model to another.
In particular, knowledge distillation (Hinton et al.,
2015; Mirzadeh et al., 2020; Zhou et al., 2018) con-
sider two models: teacher f
t
() with its weights W
t
and
student f
s
() with model parameters W
s
. The teacher
model is more complex than the student model. The
goal of this technique is to improve the training of the
student model with the help of predictions done by
the teacher model. Knowledge distillation is usually
employed in cases where the teacher model is very
complex in architecture and we want to emulate its
prediction distribution within the more simpler stu-
dent model. For the standard model distillation, the
loss is governed by the following objective function:
min
W
s
N
∑
i=1
L
p
(y
i
, f
s
(X
i
;W
s
)
+ λ ∗ L
d
( f
t
(X
i
;W
t
), f
s
(X
i
;W
s
)
(1)
The loss component L
p
() is the standard loss (e.g root
mean square error for regression) while L
d
helps in
distilling the knowledge learned by the teacher and
aids in better training of W
s
. For instance, through
L
d
, the student model tries to match the prediction
f
t
(X;W
t
) generated by the teacher model. Here λ is a
regularization constant that controls the weight asso-
ciated with each loss term.
We consider a different setup of knowledge dis-
tillation known as feature distillation (Vapnik and
Vashist, 2009; Xu et al., 2019) where the feature set
being visible to the student and teacher is different.
It assumes the teacher has access to both X and X
∗
while the student has access to only X. In feature
distillation, the aim of the student is to learn to pre-
dict only using feature X but with the help of the ad-
ditional knowledge available with the teacher model.
The learning of the student is done through feature
distillation where the following loss is used.
min
W
s
N
∑
i=1
L
p
(y
i
, f
s
(X
i
;W
s
)
+λ ∗ (L
d
( f
t
(X
i
, X
∗
i
;W
t
), f
s
(X
i
;W
s
))
(2)
Here, L
p
() is the standard loss (root mean square er-
ror) and L
d
() is the distillation loss. The teacher is
trained using the standard loss alone but using both
the features X and X ∗. Through feature distillation,
we aim the student to not only predict the output from
X but also learn representations similar to the teacher
through the distillation loss term. The teacher is ex-
pected to have better representation learning capabil-
ity as it learns from both the features and can assist the
student model to learn better representations through
the distillation process.
4 MODELS FOR PRIVILEGED
LEARNING OF REPUTATION
SCORES
We provide a detailed description of the teacher-
student model and the distillation techniques used to
KDIR 2022 - 14th International Conference on Knowledge Discovery and Information Retrieval
358

transfer knowledge from teacher to the student in pre-
dicting the reputation score of users.
We use three models to aid the learning process -
the teacher model f
t
: (X, X
∗
) → y which has access
to both privileged and common features, the baseline
model f
b
: X → y which has access to only common
features and no information provided by the teacher,
and student model f
s
: X → y which can access only
common features and is guided by the teacher. All the
models are based on auto-encoders, which learns a la-
tent representation of the input using an encoder and
then tries to reproduce the input through an decoder.
The auto-encoder allows one to learn a good latent
representation of the features and we intend to trans-
fer knowledge through these latent representations.
The latent representation is used to predict the reputa-
tion score using a neural network. In all these models,
the reputation score prediction from the latent repre-
sentation is done using a two layer neural network.
The teacher will be able to learn to predict reputation
scores from both the alternate data and privileged data
while the student has access to only alternate data,
but we intend to improve student learning using the
teacher.
We transfer the knowledge from teacher to stu-
dent by constraining the latent space of the teacher
and student to be similar. This is achieved by putting
an RMSE loss directly on the latent representations
of the student z
s
and teacher z
t
. We follow two varia-
tions of training this student-teacher model: 1) train-
ing student and teacher simultaneously (co-train), 2)
training the teacher model first and then the student
model with a constraint on the latent representations
(pre-train). Figure 1 represents the overall architec-
ture of the proposed model.
4.1 Loss Function
In the first case (co-train), we use joint loss functions
over both teacher and student models along with the
RMSE loss over the latent space (L
constr
()) which en-
sures similarity.
min
W
t
,W
s
N
∑
i=1
(L
p
(y
i
, f
t
(X
i
, X
∗
i
;W
t
))
+ λ
1
L
rec
((X
i
, X
∗
i
), (X
0
i
, X
∗
i
0
)) + L
p
(y
i
, f
s
(X
i
;W
s
))
+ λ
2
L
rec
(X
i
, X
0
i
) + λ
3
L
constr
(z
ti
, z
si
))
(3)
where (X
0
, X
∗
0
) and X
0
are reconstructed input by
the decoder of teacher and student networks respec-
tively. Here, L
rec
() is the auto-encoder reconstruction
loss (RMSE) between the output of the decoder and
input of the encoder. The hyper-parameters λ
1
, λ
2
, λ
3
control the degree of regularization through the recon-
struction loss and strength of transfer.
In the second case (pre-train), we train the teacher
model first using the following loss
min
W
t
N
∑
i=1
L
p
(y
i
, f
t
(X
i
, X
∗
i
;W
t
))
+ λL
rec
((X
i
, X
∗
i
), (X
0
i
, X
∗
i
0
))
(4)
Then, we train the student model with the following
loss which includes the constraint loss component.
min
W
s
N
∑
i=1
L
p
(y
i
, f
s
(X
i
;W
s
))
+λ
1
L
rec
(X
i
, X
0
i
) + λ
2
L
constr
(z
si
, z
ti
)
(5)
4.2 Experimental Details
We perform the experiments on a subset of the Stack
Overflow dataset. From 13 million users, we select
65957 users who have valid about me, website data
and have their reputation scores to be between 2 and
10000, both inclusive. We exclude users with repu-
tation score value of 1 as every new user is assigned
that score at the time of creation and signifies no user
activity for a lot of users. We use LDA (Blei et al.,
2003) and GLoVE (Pennington et al., 2014) to con-
vert about me and textual data into embedding vec-
tors. As presented in section 3.1, we also use the
website category feature, which is a vector of size 3.
We split our dataset into train split and test split in
about 80:20 ratio and use the results as reported on the
test data. We use the root mean square error (RMSE)
metric to evaluate the reputation score prediction ca-
pability of the model. The teacher model will have
access to both the privileged and alternate data dur-
ing evaluation while the student will have access to
only alternate data. The experiments use a 5 fold
cross validation technique on the train split and the
hyper-parameters are selected using grid search. We
also consider Bayesian optimization (Shahriari et al.,
2016) to get the optimal hyper-parameters for the co-
train model. The batch size for all the experiments
is 64 and the learning rate is 0.001 which is used in
Adam Learning Optimizer (Kingma and Ba, 2014). In
Figure 1, while using LDA we consider input vectors
of size 20 for both about me and web data features
(and 100 for Glove), a 3 dimensional web category
and a 4 dimensional vector of activity features. The
teacher encoder will have 4 fully connected layers of
size 30, 20, 15 and 10. We provide the activity feature
vector in the second layer of the encoder. The teacher
decoder consists of fully connected layers of size 15,
24, 30 and 43. The reputation prediction module con-
sists of two fully connected layers of size 5 and 1.
Predicting Reputation Score of Users in Stack-overflow with Alternate Data
359

Table 1: Prediction errors (RMSE) of the models on the stack overflow data.
Model Training RMSE (LDA) RMSE (GLoVE)
Feed Forward Network only activity features 943.6
Baseline Auto-encoder only alternate data 2181.4 2266.5
Teacher Pre-train and 608.5 756.5
Student Grid search 1960.0 1968.8
Teacher Co-train and 626.6 757.5
Student Grid search 1937.6 2173.5
Teacher Co-train and 589.7 649.1
Student Bayesian optimization 1949.3 2130.2
The student component of the model is very similar to
that of the teacher, except that the second layer of the
encoder and third last layer of decoder is of size 20,
since we are not passing any activity features directly
to the student. For reference, we have developed a
simple autoencoder network which uses only activity
features to predict the reputation score. The layers in
the encoder are fully connected layers of size 4,3,3,2
and that of decoder is 3,3,4,4. The reputation predic-
tion module consists of two fully connected layers of
size 2 and 1.
The hyper-parameters selected are as follows:
• For the Teacher model, the learning rate is 0.01,
batch size is 128, number of epochs is 100 and the
λ used in reconstruction loss is 0.95.
• For the Teacher assisted student model, the learn-
ing rate is 0.001, batch size is 128, number of
epochs is 100 and the λ used in reconstruction loss
is 0.8.
4.3 Results
Table 1 shows the results of the various models used
for reputation prediction. Note that all reported values
correspond to the RMSE errors between reputation
prediction and actual score. When comparing the re-
sults of the feed forward model with the teacher base
model, it is clear that a combination of activity and
alternate features gives better results than considering
only activity features. We can also see that for all the
proposed student models, the RMSE is less than the
baseline auto-encoder without any distillation. This
shows the effectiveness of our distillation approach
and the student auto-encoder. Although feature dis-
tillation reduces RMSE, the gap between teacher and
student models still needs some improvement.
Comparing the two representations of the text,
we observe that the LDA based representation gives
a better performance than the Glove representation.
This is possibly due to two reasons. The dimension-
ality of GLoVE embeddings is higher than the LDA
based embeddings. This may distract the model from
the activity based features which are lesser in num-
ber. The student and the distilled model learn better
for LDA as it has a lesser number of dimensions. Sec-
ondly, LDA tries to identify the topic distribution in
the text holistically by considering the entire text to-
gether. On the other hand, the GLoVE based method
aggregates the information from individual words to
get the final vector. Thus, LDA is more useful in cap-
turing the expertise of the user and consequently pre-
dict the reputation score.
Table 2 shows a case study involving two users
from the dataset. Both the users have a reasonable
amount of alternate data available on their website.
Our student model could effectively learn from the al-
ternate data and has assigned reasonably good scores
to both of them, higher scores to one with higher
ground truth reputation score and vice-versa. We
see many more such examples from our experiments
which support the applicability of the approach.
5 CONCLUSIONS
We have developed an auto-encoder based regression
model and utilized privileged distillation to transfer
the knowledge of teachers, to assist the training of
the student model. We consider two different train-
ing procedures for the proposed model. The proposed
approaches were found to be effective in predicting
reputations score of users in the stack overflow data.
We found the alternate data to provide additional in-
formation which improved the reputation score pre-
diction performance. Further, we found the student
model learnt using feature distillation to also improve
the performance compared to the baseline model. As
a future work, we would like to further reduce the per-
formance gap between student and the teacher in pre-
dicting the reputation score.
KDIR 2022 - 14th International Conference on Knowledge Discovery and Information Retrieval
360
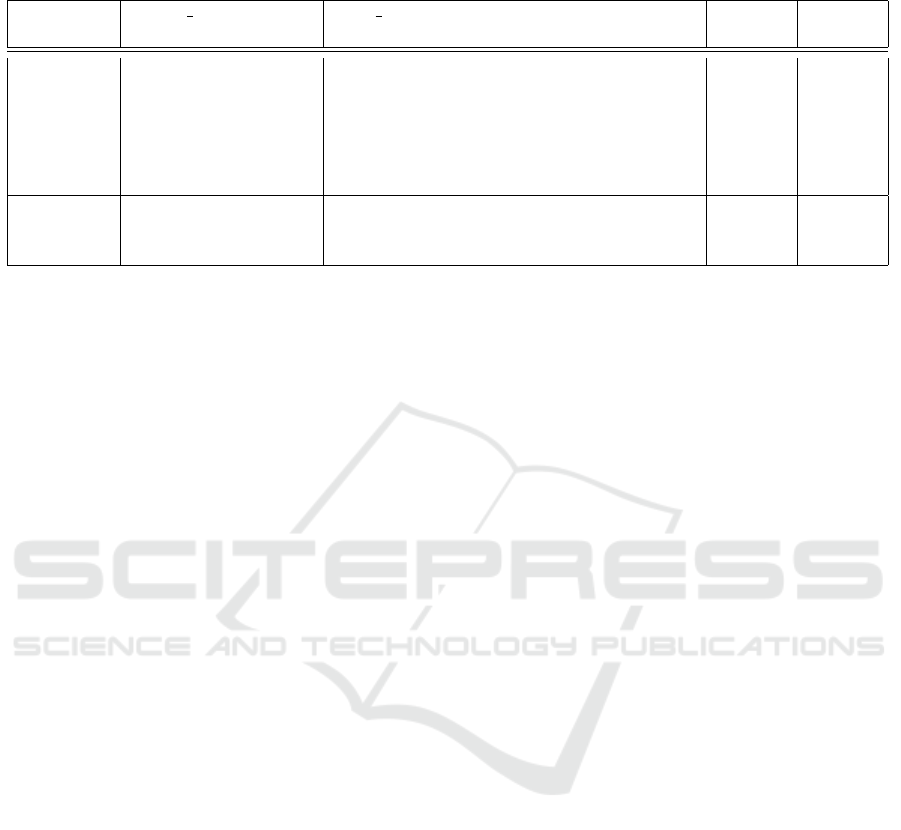
Table 2: Actual and predicted scores for two users from the test split of dataset using student model with LDA input vectors.
The examples are tken from public data dump of the Stack Exchange forum.
User
name
About Me Web Data Prediction Target
****** https://www.*****.co
m
How To Watch For Changes Tuesday March
30 2021 5 minute read I needed to customize
the reviews UI on a product detail page for a
Shopify site whenever there were no reviews.
However, I ran into a series of unexpected
problems ...
1227.6 3114
******* Computer ***** Stu-
dent at Georgia Tech
A 60 GHz phased arrayfor $10 A 60 GHz
phased array for $10 In 2018, I gave an talk
that was basically Phased Arrays 101...
628.7 1223
REFERENCES
Anderson, A., Huttenlocher, D., Kleinberg, J., and
Leskovec, J. (2012). Discovering value from com-
munity activity on focused question answering sites:
A case study of stack overflow. In Proceedings of
the 18th ACM SIGKDD International Conference on
Knowledge Discovery and Data Mining, KDD ’12,
page 850–858, New York, NY, USA. Association for
Computing Machinery.
Banati, H. and Seema (2021). Proficiency assessment of
experts in online social network q/a communities. In
2021 9th International Conference on Reliability, In-
focom Technologies and Optimization (Trends and Fu-
ture Directions) (ICRITO), pages 1–5.
Blei, D. M., Ng, A. Y., and Jordan, M. I. (2003). Latent
dirichlet allocation. volume 3. JMLR.org.
Cavusoglu, H., Li, Z., and Huang, K.-W. (2015). Can gam-
ification motivate voluntary contributions? the case
of stackoverflow q&a community. In Proceedings
of the 18th ACM Conference Companion on Com-
puter Supported Cooperative Work & Social Comput-
ing, CSCW’15 Companion, page 171–174, New York,
NY, USA. Association for Computing Machinery.
Chen, Z., Wang, D., and Yin, S. (2021). Improving cold-
start recommendation via multi-prior meta-learning.
In European Conference on Information Retrieval,
pages 249–256. Springer.
Du, Y., Zhu, X., Chen, L., Fang, Z., and Gao, Y. (2022).
Metakg: Meta-learning on knowledge graph for cold-
start recommendation. IEEE Transactions on Knowl-
edge and Data Engineering.
Hao, B., Zhang, J., Yin, H., Li, C., and Chen, H. (2021).
Pre-training graph neural networks for cold-start users
and items representation. In Proceedings of the 14th
ACM International Conference on Web Search and
Data Mining, pages 265–273.
Hinton, G., Vinyals, O., and Dean, J. (2015). Distilling
the knowledge in a neural network. In NIPS Deep
Learning and Representation Learning Workshop.
Kingma, D. and Ba, J. (2014). Adam: A method for
stochastic optimization. International Conference on
Learning Representations.
Lam, X. N., Vu, T., Le, T. D., and Duong, A. D. (2008). Ad-
dressing cold-start problem in recommendation sys-
tems. In Proceedings of the 2nd international con-
ference on Ubiquitous information management and
communication, pages 208–211.
Lopez-Paz, D., Sch
¨
olkopf, B., Bottou, L., and Vapnik, V.
(2016). Unifying distillation and privileged informa-
tion. In International Conference on Learning Repre-
sentations (ICLR).
MacLeod, L. (2014). Reputation on stack exchange: Tag,
you’re it! In 2014 28th International Conference on
Advanced Information Networking and Applications
Workshops, pages 670–674.
Mirzadeh, S. I., Farajtabar, M., Li, A., Levine, N., Mat-
sukawa, A., and Ghasemzadeh, H. (2020). Improved
knowledge distillation via teacher assistant. Proceed-
ings of the AAAI Conference on Artificial Intelligence,
34(04):5191–5198.
Morrison, P. and Murphy-Hill, E. (2013). Is programming
knowledge related to age? an exploration of stack
overflow. In 2013 10th Working Conference on Min-
ing Software Repositories (MSR), pages 69–72.
Movshovitz-Attias, D., Movshovitz-Attias, Y., Steenkiste,
P., and Faloutsos, C. (2013). Analysis of the reputa-
tion system and user contributions on a question an-
swering website: Stackoverflow. In 2013 IEEE/ACM
International Conference on Advances in Social Net-
works Analysis and Mining (ASONAM 2013), pages
886–893.
Overflow, S. (2022a). Stack Overflow Datadump.
Overflow, S. (2022b). What is reputation? How do I earn
(and lose) it? - Help Center - Stack Overflow.
Park, S.-T. and Chu, W. (2009). Pairwise preference regres-
sion for cold-start recommendation. In Proceedings of
the third ACM conference on Recommender systems,
pages 21–28.
Pechyony, D. and Vapnik, V. N. (2010). On the theory of
learning with privileged information. In NIPS 2010.
Pennington, J., Socher, R., and Manning, C. (2014). GloVe:
Global vectors for word representation. In Proceed-
Predicting Reputation Score of Users in Stack-overflow with Alternate Data
361

ings of the 2014 Conference on Empirical Methods in
Natural Language Processing (EMNLP), pages 1532–
1543, Doha, Qatar. Association for Computational
Linguistics.
Shahriari, B., Swersky, K., Wang, Z., Adams, R. P., and
de Freitas, N. (2016). Taking the human out of the
loop: A review of bayesian optimization. Proceedings
of the IEEE, 104(1):148–175.
Slag, R., de Waard, M., and Bacchelli, A. (2015). One-day
flies on stackoverflow - why the vast majority of stack-
overflow users only posts once. In 2015 IEEE/ACM
12th Working Conference on Mining Software Repos-
itories, pages 458–461.
Sujithra Alias Kanmani, R., Surendiran, B., and Ibrahim,
S. (2021). Recency augmented hybrid collaborative
movie recommendation system. International Journal
of Information Technology, 13(5):1829–1836.
Vapnik, V. and Izmailov, R. (2015). Learning using priv-
ileged information: similarity control and knowledge
transfer. J. Mach. Learn. Res., 16:2023–2049.
Vapnik, V. and Vashist, A. (2009). 2009 special issue: A
new learning paradigm: Learning using privileged in-
formation. Neural Netw., 22(5–6):544–557.
Wang, J., Ding, K., and Caverlee, J. (2021a). Sequential
recommendation for cold-start users with meta tran-
sitional learning. In Proceedings of the 44th Inter-
national ACM SIGIR Conference on Research and
Development in Information Retrieval, pages 1783–
1787.
Wang, S., Zhang, K., Wu, L., Ma, H., Hong, R., and Wang,
M. (2021b). Privileged graph distillation for cold start
recommendation. Proceedings of the 44th Interna-
tional ACM SIGIR Conference on Research and De-
velopment in Information Retrieval.
Woldemariam, Y. (2020). Assessing users’ reputation from
syntactic and semantic information in community
question answering. In Proceedings of the 12th Lan-
guage Resources and Evaluation Conference, pages
5383–5391, Marseille, France. European Language
Resources Association.
Xu, C., Li, Q., Ge, J., Gao, J., Yang, X., Pei, C., Sun, F., Wu,
J., Sun, H., and Ou, W. (2019). Privileged features
distillation at taobao recommendations.
Zheng, Y., Liu, S., Li, Z., and Wu, S. (2021). Cold-start
sequential recommendation via meta learner. In Pro-
ceedings of the AAAI Conference on Artificial Intelli-
gence, volume 35, pages 4706–4713.
Zhou, G., Fan, Y., Cui, R., Bian, W., Zhu, X., and Gai, K.
(2018). Rocket launching: A universal and efficient
framework for training well-performing light net. Pro-
ceedings of the AAAI Conference on Artificial Intelli-
gence, 32(1).
KDIR 2022 - 14th International Conference on Knowledge Discovery and Information Retrieval
362
