
Risk Assessment Model for Diabetic Cardiovascular Disease
Via Personality and Time-Aware LSTM Network
Dehua Chen
1,*
, Liping Zhang
1,*
, Ming Zuo
2
and Qiao Pan
1
1
School of Computer Science and Technology, Donghua University, Shanghai 201620, China
2
School of Medicine, Shanghai Jiao Tong University, Ruijin Hospital, Shanghai 200025, China
Keywords:
Diabetic Cardiovascular Disease, Risk Assessment, Individual Feature Interaction.
Abstract:
Diabetic cardiovascular disease is one of the leading causes of disease death in the diabetic population and its
prevention and treatment has become a major social challenge. It has attracted the attention of many scholars
and experts around the world, and a lot of research work has been done on it. Most of them use cox
proportional risk models to investigate the correlation between risk indicators and the risk of developing
cardiovascular disease based on statistical methods, which lack attention to the heterogeneity of individual
patient characteristics and disease contextual information. To fill this gap, we propose a new deep learning
model, the Personality and Time-Aware LSTM (PT-LSTM), which is based on individual characteristics and
time perception to assess the risk of developing cardiovascular disease in diabetes. The model is able to take
into account the characteristics of chronic metabolic disease in diabetes, using information from long-term
patient visits as input. The model uses the individual feature interaction layer to reweight the hidden
information of disease information learned in the T-LSTM unit, resulting in a more accurate representation
of disease information for the risk assessment task. We realistically evaluate our proposed model on this task
and the experimental results show that our proposed model exhibits better performance. Compared to the
baseline model, PT-LSTM achieves 93.49% AUROC on the dataset for this task, which is on average around
8.75% higher than the comparison model.
1 INTRODUCTION
Diabetes is a chronic metabolic disease that causes a
variety of serious health complications, including
heart disease, kidney failure and cardiovascular
disease (CVD), and has become one of the most
significant disease burdens in our country and
worldwide (Forbes, 2013). Death due to
cardiovascular diseases as a complication of diabetes
is one of the leading causes of death in this population
(Grøntved, 2011). Therefore, the search for an
effective diabetic cardiovascular disease risk
assessment method for early prevention and treatment
of the disease could greatly improve the survival rate
of diabetic patients.
Most of the existing studies have used statistically
relevant experimental analyses such as cox
proportional risk models, logistic regression tests or
simple machine learning to calculate the correlation
between risk indicators and CVD risk or disease risk
scores. For example, Domanski M J et al (Mjd, 2020)
used Kaplan-Meier method estimates to assess the
association between low-density lipoprotein (LDL-C)
and CVD risk. Most of these methods are based on
statistical correlation of risk characteristics with
disease, treating both the important disease context of
diabetes and important individual characteristics such
as patient gender as simple risk characteristics. As a
result, most of them lack attention to the heterogeneity
of individual patient characteristics and ignore the
important information carried by the disease context.
Based on the above issues, we propose a model for
assessing cardiovascular disease risk in diabetes based
on individual interaction and time perception, namely
the Personality and Time-Aware LSTM (PT-LSTM).
PT-LSTM takes into account the chronic metabolic
disease characteristics of diabetes and is inspired by
the TLSTM model proposed by Baytas I M et al
(Baytas, 2017), which is applied on top of the T-
LSTM to design an individual feature interaction layer
that uses individual features to correct the hidden
information of disease information obtained from
learning Time-aware LSTM units to obtain a more
accurate representation of disease information.
Finally, we use a fully connected layer to assess the
Chen, D., Zhang, L., Zuo, M. and Pan, Q.
Risk Assessment Model for Diabetic Cardiovascular Disease Via Personality and Time-Aware LSTM Networ k.
DOI: 10.5220/0012032600003633
In Proceedings of the 4th International Conference on Biotechnology and Biomedicine (ICBB 2022), pages 467-475
ISBN: 978-989-758-637-8
Copyright
c
2023 by SCITEPRESS – Science and Technology Publications, Lda. Under CC license (CC BY-NC-ND 4.0)
467

patient's current risk of developing cardiovascular
disease.
In summary, the main contributions of this paper
are as follows.
(1) Considering the chronic metabolic disease
characteristics of diabetes mellitus, we adopt the
modelling idea of T-LSTM. For the diabetic
cardiovascular disease risk assessment task, we regard
patients' long-term medical visit data as time-series
information as the input to the model.
(2) An individual feature interaction network was
designed to incorporate individual patient features into
the model learning, resulting in a more accurate
representation of disease information features.
To demonstrate the effectiveness and superiority
of our model, we evaluated and compared the model
with traditional machine learning methods (LR, RF
and GBDT) and deep learning methods (RNN, GRU
and LSTM) on this task. The experimental results
show that our proposed model performs better in real-
world tasks, outperforming the compared baseline
models in terms of metrics such as AUROC.
2 RELATED WORK
Cardiovascular disease, as the leading cause of death
worldwide, is an important public health issue (Yang,
2020) and its associated disease risk research has
been a hot issue over the years, attracting the attention
of many scholars and experts at home and abroad. For
example, Bode E D et al (Bode, 2021) studied the risk
factors for cardiovascular disease in US firefighters
by BMI category based on statistical methods using
the Wald test and logistic regression models.
D'Agostino RB Sr et al (D’Agostino Sr, 2008)
constructed a predictive model for cardiovascular
disease in Framingham, USA, based on the general
population. Elley CR et al (Elley, 2010) used a cox
proportional risk regression model to construct a New
Zealand diabetes cohort based on patients with type 2
diabetes, assessing multiple risk factors such as
glycated haemoglobin associated with cardiovascular
disease. Conroy R M et al (Conroy, 2003) used the
Weibull proportional risk model to develop a risk
scoring system for the clinical management of
cardiovascular risk in European clinical practice.
These risk prediction algorithms are typically
developed using multivariate regression models and
often assume that all these factors are linearly related
to cardiovascular disease prognosis, allowing existing
algorithms to typically exhibit modest predictive
performance (Alaa, 2019). This has led some scholars
to propose data-driven techniques based on machine
learning (ML) to improve the performance of risk
prediction. For example, Mohan S et al (Mohan,
2019) combined random forest (RF) and linear
methods (LM) to propose a hybrid random forest
(HRFLM) heart disease prediction model with linear
models for improving the accuracy of predicting
cardiovascular disease. Dinh A et al (Dinh, 2019)
used multiple supervised learning models to classify
high-risk patients to obtain better performance than a
single algorithm.
All of these efforts have contributed to the study
of cardiovascular disease risk in diabetes. But these
models treat all relevant factors as the same, lack
attention to the clinical significance of individual
patient characteristics, and ignore important
information carried by the disease context. Such as
patient age, gender and the disease context of
diabetes. Patients with diabetes are at greater risk of
developing cardiovascular disease and the correlation
cannot be ignored (Einarson, 2018; Strain, 2018).
Therefore, it is important to further explore and
exploit diabetes information for cardiovascular
disease risk prediction tasks.
3 PT-LSTM METHOD
3.1 Overview
As shown in Fig.1, the PT-LSTM model is a three-
stage architecture consisting of three components: (1)
a feature learning module based on Time-aware
LSTM; (2) an interaction module of individual
characteristics based on attention; (3) a prediction
module with Fully Connected Network (FNN) for
disease risk assessment.
The PT-LSTM model uses the visit records and
visit time intervals in patients' EHR information as
inputs to the T-LSTM module to obtain the hidden
state ℎ
and 𝑐
at the first moment. In the attention-
based individual feature interaction module, the
observation window size is set to K, and the sequence
of disease hidden feature information
ℎ
:
(ℎ
:
=[ℎ
,...,ℎ
,ℎ
]) output in
the previous stage is used as input to the module
together with the individual patient features 𝑞. The
module outputs the reweighted weights β (β =
[β
,...,β
,β
]) of ℎ
:
based on the
interaction of the individual patient features 𝑞 with
the temporal hidden information ℎ
:
. Finally, the
disease risk information 𝑢 is obtained based on the
corrected temporal hidden information ℎ
:
and
individual characteristics 𝑞 to predict the risk of
disease occurrence 𝑦.
ICBB 2022 - International Conference on Biotechnology and Biomedicine
468
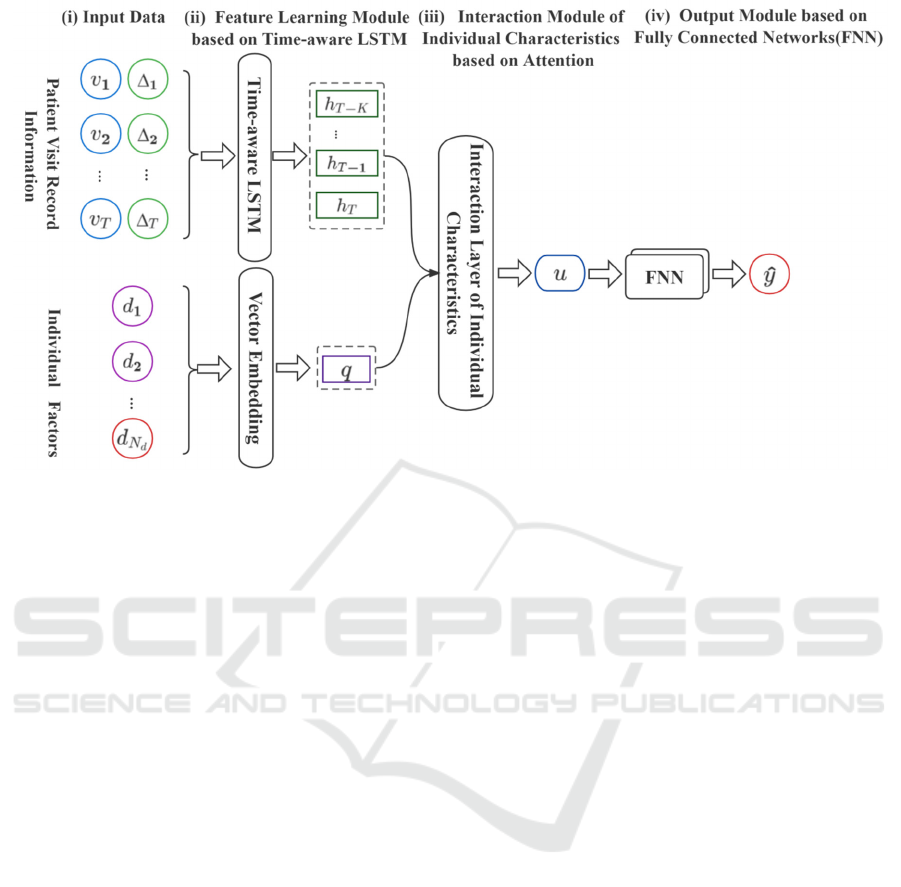
Figure 1: Overall architecture of Personality and Time-aware LSTM model
3.2
Time-Aware LSTM Module
T-LSTM is proposed based on the architecture of
LSTM, which merges runtime information into the
standard LSTM architecture and is able to focus on
the information dependencies between two adjacent
visit records (e.g. 𝑣
and 𝑣
) to capture the
temporal dynamics of sequential data with temporal
irregularities. Therefore, in order to capture long-term
information in patient medical data, in this paper we
use a Time-aware LSTM module to process the
temporal medical features in patient data, as shown in
Fig.2, which is computed as follows.
𝐶
= 𝑡𝑎𝑛ℎ(𝑊
𝐶
𝑏
) 𝐶
=𝐶
∗𝑔(∆
) (New short term memory)
𝐶
=𝐶
𝐶
𝐶
=𝐶
𝐶
(New previous memory)
𝑓
=𝜎(𝑊
𝑣
𝑈
ℎ
𝑏
) 𝑖
=𝜎(𝑊
𝑣
𝑈
ℎ
𝑏
)
𝑜
=𝜎(𝑊
𝑣
𝑈
ℎ
𝑏
) (Gate cell calculation)
𝐶
= 𝑡𝑎𝑛ℎ(𝑊
𝑣
𝑈
ℎ
𝑏
) 𝐶
=𝑓
∗𝐶
𝑖
∗𝐶
(Current memory)
ℎ
=𝑜
∗𝑡𝑎𝑛ℎ( 𝐶
) (Current hidden state)
Here, 𝑣
represents the current input, ℎ
and
ℎ
are the hidden states of the previous and current
steps respectively. 𝐶
and 𝐶
are the unit
memory of the previous and current steps
respectively. 𝐶
represents the short-term
memory, 𝐶
is the short-term memory after
adjustment, 𝐶
represents the long-term memory.
Similarly, as with standard LSTM units, 𝐶
i s t h e
current candidate memory, 𝑓
, 𝑖
an d 𝑜
are the
input, forget and output gates respectively. In
addition, 𝑊 , 𝑈 and 𝑏 are the network parameters
to be trained, ∆
is the access interval between 𝑣
and 𝑣
, and 𝑔() is a heuristic decay function based
on the value ∆
, i.e. the larger the value of ∆
, the
smaller the effect on short-term memory.
Risk Assessment Model for Diabetic Cardiovascular Disease Via Personality and Time-Aware LSTM Network
469
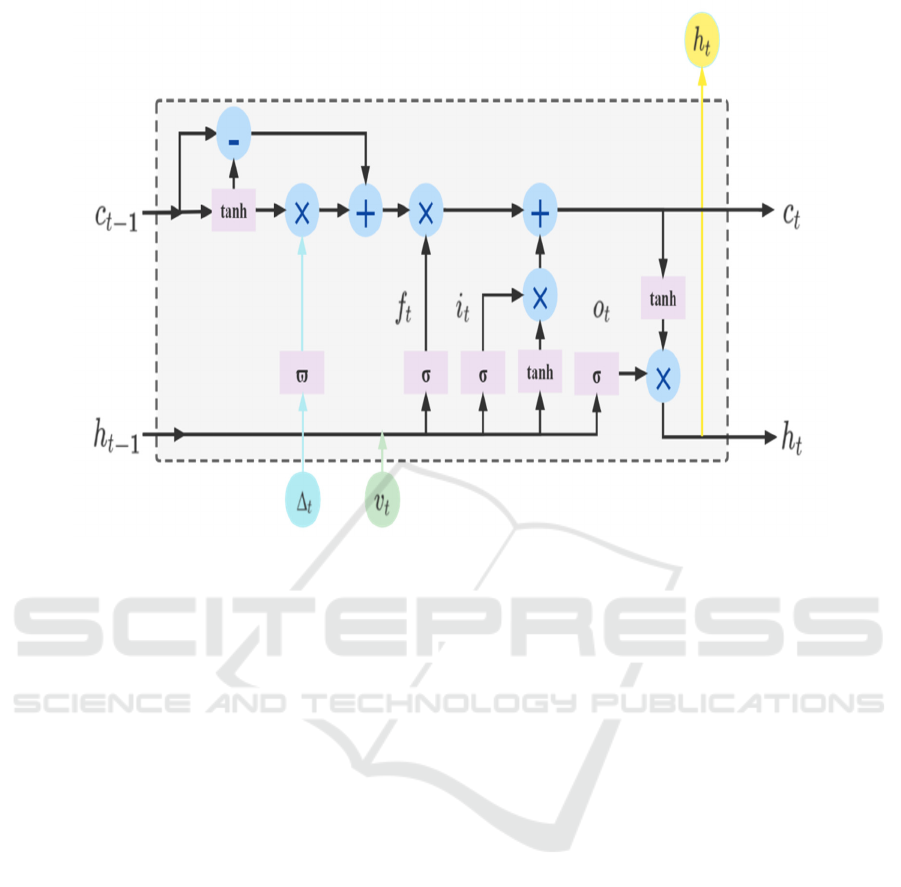
Figure 2: The structure of Time-aware LSTM cell.
3.3
Attention-Based Feature
Interaction Module
In order to obtain more accurate information about
the characteristics that can represent the patient's
current risk of disease occurrence, we developed an
attention-based individual factor interaction layer
applied on the Time-aware LSTM cell, as shown in
Fig.3 (a), whose specific process can be represented
as the following three stages.
(1) Individual Feature Representation Layer
First, we count the discrete number of discrete
individual features as the word table size, and
according to the size of the number of possible values
of discrete features, we set the word vector dimension
size to 𝑁
. Subsequently, the discrete individual
features [𝑑
,...,𝑑
] are input to the embedding
layer, and the embedding vector [𝑒
,...,𝑒
],𝑒
∈
ℝ
of individual features is obtained based on
Word2Vec. Then, the matrix representation 𝑞 (𝑞∈
ℝ
(
∗
)
) of individual features is obtained by
vector stitching through the concat layer, and then
multiplied with the parameter matrix 𝑊
(𝑊
∈
ℝ
(
∗
)
) to obtain the latest representation
𝑞(𝑞 ∈ ℝ
) of individual features by matrix
variation.
(2) Activation Unit
The individual feature 𝑞 and the hidden state
sequence ℎ
:
are used as the input of this layer,
and the outer product 𝑝 of the two features is
calculated, which is then concatenated with these two
features to obtain the new feature representation. The
attention weights β are obtained by multi fully
connected network and linear layer. Here is an
example of the calculation process for a single ℎ
with 𝑞, as shown in Fig.3 (b), and the formula is
expressed as follows.
𝑝=𝑞∗ℎ
𝑅
=𝑅𝑒𝐿𝑢𝑊
(𝑞 ⊕ 𝑝⨁ℎ
)𝑏
𝑅
=𝑅𝑒𝐿𝑢(𝑊
𝑅
𝑏
) (1)
𝛽
=𝑆𝑜𝑓𝑡𝑀𝑎𝑥(𝑊
𝑅
𝑏
)
(3) Feature Interaction Layer
Based on the attention weights in the previous
layer, the modified disease hidden information
ℎ
:
is obtained, which is input to the SUM
Pooling layer for summation according to the 1st
dimension, and then concatenated with the individual
feature information to obtain the final disease
information feature representation 𝑢.
𝑢=𝑞 ⨁ 𝛽
ℎ
(2)
ICBB 2022 - International Conference on Biotechnology and Biomedicine
470

(a) Overall structure (b) The process of the Activation Unit
Figure 3: The construction of the Individual Factors Interactive Attention Layer.
3.4
Disease Risk Assessment Module
The disease risk assessment module takes the output
𝑢 from the previous stage as input and obtains a
binary label indicating the patient's current risk of
developing cardiovascular disease via a Fully
Connected Network. In addition, we choose the cross-
entropy function to calculate the loss, which is
calculated as follows.
𝑦=𝜎(𝑊
𝑢𝑏
)
ℒ(𝑦, 𝑦) = (𝑦log(y) (1 𝑦)𝑙𝑜𝑔(1
𝑦) (3)
Where 𝑊
(𝑊
∈ℝ
) is a network parameter,
𝑦 represents the true value of the patient's risk of
developing cardiovascular disease, and 𝑦 is the
output value of the model's disease risk assessment
function.
4
EXPERIMENT
4.1
Dataset Description
The study was approved by the Ethics Committee of
Ruijin Hospital and written informed consent was
obtained from each participating patient in
accordance with the Declaration of Helsinki. Patient
information is shown in Table 1.
Table 1: Details of Patient Information.
Statistic Value
DataSet
# patients 33048
# visit 61646
#
p
ositive label 12680
# ne
g
ative label 20368
% male 60.21%
Our dataset was selected from biochemical index
data of diabetic patients in Shanghai Ruijin Hospital
from August 1, 2009 to July 30, 2021, with a total of
33,048 patients and 61,646 visit records, including
19,899 men and 13,149 women. Combining domestic
and international literature and clinical
recommendations, we selected high-density
lipoprotein, low-density lipoprotein, cholesterol,
glycated hemoglobin, two-hour glucose and
triglycerides as inputs in terms of medical
characteristics. Also, for individual patient
characteristics, we selected patient gender, age and
history of the remaining four common complications
of diabetes (here, diabetic foot disease, diabetic
nephropathy, diabetic peripheral neuropathy and
diabetic eye disease).
4.2
Experiment Setting
We implemented our proposed baseline and target
models on tensorflow 2.2.0 and scikit-learn 1.0.2, and
trained them using the Adam optimizer. Through
Risk Assessment Model for Diabetic Cardiovascular Disease Via Personality and Time-Aware LSTM Network
471
parameter tuning, we set the learning rate to 0.001,
the dimensionality of the individual feature
embedding vector used in the deep learning baseline
and PT-LSTM models to 64, and the dimensionality
of the hidden vector to 128. In addition, we randomly
divided the dataset into ten sets, and all experimental
results were averaged by ten cross-validations, using
seven training sets, one validation set, and two testing
sets each time. Finally, we compared the performance
of all methods using four metrics: the area under the
receiver operating characteristic (AUROC) curves,
Accuracy, Recall and F1-Score in the test set as
measures.
To validate the effectiveness of our proposed
model, we evaluated our proposed PT-LSTM model
on different baseline models, including three
traditional machine learning methods, LR, RF, and
GBDT, and four deep learning methods, RNN, GRU,
LSTM, and T-LSTM. Among them, in order to
demonstrate the availability of individual feature
interaction, we also implemented three versions of
PT-LSTM and LSTM, namely PT-LSTM_Metabo,
PT-LSTM_Add, PT-LSTM_Concat, LSTM_Metabo,
LSTM_Add, and LSTM_Concat, respectively.
Notably, there are many advanced clinical prediction
models that use attentional mechanisms to extract
long-term dependencies in patients' historical visits
(Kamal, 2020; Lee, 2018), and they are orthogonal to
our contribution. We focus on taking into account the
heterogeneity of individual patient factors into the
model, and our model PT-LSTM can be easily
combined with attentional mechanisms.
4.3
Comparison Methods
To obtain the best performance of the model, all
models used in our experiments were involved in
parameter tuning. In this subsection, the PT-LSTM
model is used as an example to discuss and compare
the different effects of the number of patient medical
visits T and the observation window size K of the
individual-specific interaction layer on the model
performance.
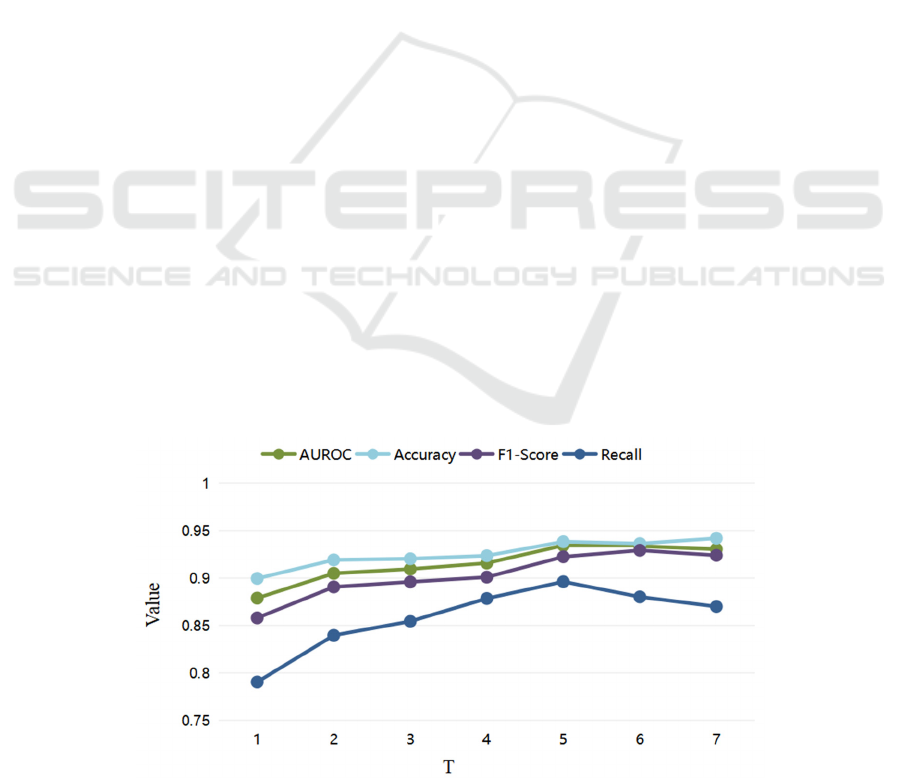
4.3.1 Comparison of Parameter Selection
(1) Parameter Selection of T
Diabetic disease is a chronic metabolic disease, and
to accurately assess the risk of cardiovascular disease
in diabetic patients, it is important to effectively
follow up and learn the long-term health status of
patients. Setting K = 1, an experimental comparison
of our proposed PT-LSTM model regarding the
number of patient medical visits T was conducted.
As shown in Fig.4, the experimental results show
that each assessment index of the model improves as
T increases. Thus, we believe that tracking and
learning information about patients' long-term visits
can effectively improve the accuracy of patients'
cardiovascular disease risk assessment. We consider
that this is brought about by diabetes itself as a
chronic metabolic disease. Therefore, we should
collect as much information on patient visits as the
amount of data allows as a way to improve the
accuracy of the disease risk assessment task. In
addition, we observed that the model metrics reached
their best and started to stabilize when T was greater
than equal to 5. In order to reduce the impact of too
small a data volume on other model comparison
experiments later, we selected T of 5 as the parameter
for our later experiments.
Figure 4: Parameter selection of T.
ICBB 2022 - International Conference on Biotechnology and Biomedicine
472
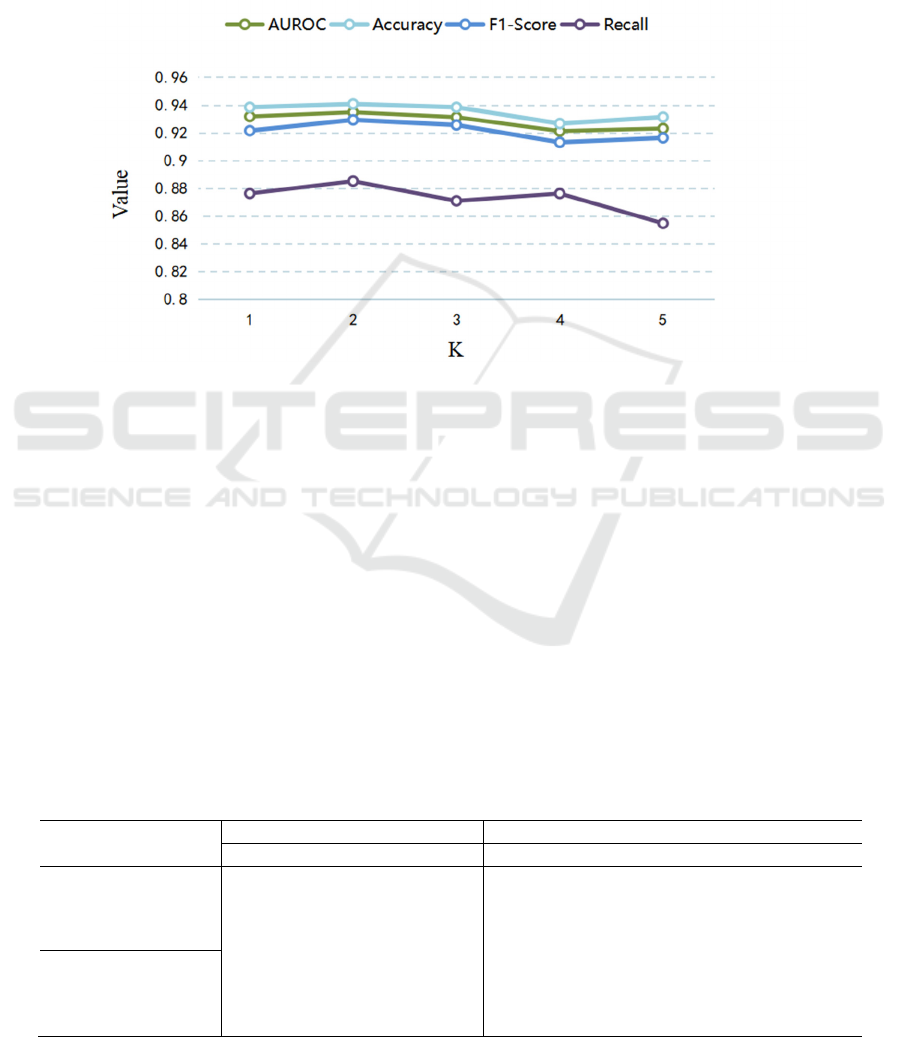
(2) Parameter Selection of K
Here, we set T=5 and discuss the influence and role
of the parameter K in the individual feature
interaction module on the use of the model. The
experimental results are shown in Fig.5. When K=2,
the model achieves the best performance, and when it
is larger than 2, the model performance decreases,
which is due to the long-term dependency of
information that has been modeled and learned in the
PT-LSTM. When T = 5, the observation window K is
set too large, e.g. K is greater than 2, which can lead
to the model focusing excessively on the repetitive
and redundant part of the feature information, thus
reducing the performance of the model. This also
confirms the advantage of our LSTM unit in learning
long-term dependence of information from a certain
perspective.
Figure 5: Parameter selection of K.
4.3.2 Comparison of Individual Feature
Fusion Methods
From the experimental results in Table 2, we can find
that the traditional LSTM model and our proposed
model can also have relatively good results with only
metabolic metrics, and their AUROC metrics can
reach 85.87% and 88.66%, respectively.
Subsequently, we added individual feature learning to
the models using the traditional feature fusion
methods concat and add, and both models showed
significant improvements in various metrics such as
AUROC, accuracy and F1-Score. This reflects the
importance of individual feature learning in disease
risk tasks. When we employ the interactive fusion
method of individual features based on attention
mechanism on LSTM and T-LSTM (i.e., LSTM_At
and PT-LSTM), the accuracy and other evaluation
metrics are significantly better than other models and
fusion methods, which can reach 91.02% and
94.09%, respectively.
The experimental results demonstrate the
effectiveness of our proposed individual feature
interaction network and support the superiority of our
model. In addition, comparing the LSTM and PT-
LSTM models and their respective improved models,
we can also find that effectively focusing on the
medical information carried by the irregularity of visit
time in medical data is of great significance and value
for our assessment of disease risk.
Table 2: Comparison of feature fusion methods.
Model
a
Feature Fusion
b
Evaluation Index
Metabo Indifac Interfus Accuracy F1-Score AUROC Recall
LSTM_Metabo √
0.8747 0.8359 0.8587 0.7258
LSTM
_
Ad
d
√
√
0.9007 0.8793 0.8923 0.8226
LSTM_Concat
√
√
0.8913 0.8678 0.8827 0.8118
LSTM
_
At
√
√
√
0.9102 0.8889 0.9002 0.8172
PT-LSTM_Metabo √
0.8936 0.8725 0.8866 0.8280
PT-LSTM
_
Ad
d
√
√
0.9291 0.9128 0.9199 0.8441
PT-LSTM_Concat
√
√
0.9314 0.9169 0.9238 0.8602
PT-LSTM √ √ √
0.9409 0.9291 0.9345 0.8817
Risk Assessment Model for Diabetic Cardiovascular Disease Via Personality and Time-Aware LSTM Network
473

a
“Metabo” here means that the model only uses
patient visit data as input data. “Concat” and “Add”
represent the fusion mode of medical characteristic
information and individual factors.
b
Here, we defined the patient visit data as “Metabo”,
individual factor as “Indifac”, and individual
characteristic interaction as “Interfus”.
4.3.3 Comparison of Different Producttion
Models
To further validate the superiority of our proposed
model, we evaluated our proposed PT-LSTM model
on different baseline models. The experimental
results are shown in Table 3, where the disease risk
assessment task almost always performs worse than
the deep learning model on machine learning. We
consider that it is because the machine learning model
loses the temporal information of medical visits and
the information of individual patient characteristics.
The T-LSTM outperforms the LSTM model,
demonstrating the importance of irregular visit timing
information in patient medical data in our diabetic
cardiovascular disease risk assessment task. It should
be noted that the individual feature fusion methods
used here for both the LSTM and T-LSTM models
are the ones they performed better in the previous
section, and in this case, our proposed model PT-
LSTM also shows significant advantages.
Table 3: Comparison of different models.
Model Accuracy F1-Score Recall AUROC
Baseline
LR
RF
GBDT
0.7626
0.7857
0.7899
0.7483
0.7839
0.7863
0.721
0.794
0.7897
0.7617
0.7859
0.7899
RNN 0.8960 0.8736 0.8172 0.8875
GRU 0.8960 0.8771 0.8441 0.8904
LSTM
T-LSTM
0.9007
0.9214
0.8793
0.9069
0.8226
0.8602
0.8923
0.9138
Proposed PT-LSTM 0.9409 0.9294 0.8852 0.9349
In summary, we have experimentally analyzed
and compared each important module of the model
and its overall performance. In addition, we compared
the parameter selection of the training model and
selected the optimal hyper-parameters. The
experimental results of the comparison with the
baseline model provide evidence for the effectiveness
and superiority of our proposed model.
5 CONCLUSION
In this study, we propose a new deep learning model
(PT-LSTM), for the task of assessing the risk of
developing cardiovascular complications in the
context of diabetes. Our can model is divided into
three phases. In the first stage, patient visit records
and visit intervals are used as input, and a time-aware
LSTM module is employed to learn disease
information carried by temporal data from patient
medical visits. In the second stage, individual patient
factors are interacted with the disease information
features obtained in the previous stage to obtain a
more comprehensive and accurate representation of
disease risk features. In the third stage, a fully
connected layer is used for our final disease risk
assessment. The experimental results show that our
model, based on the design of individual feature
interaction fusion, can learn patient information better
and make it consistently better than the base model.
Our model also shows better performance in this task
compared to other models.
Our proposed model effectively addresses the
problem of personalised assisted diagnosis in the
diabetic cardiovascular disease risk assessment task.
In clinical practice, we hope that our model can help
physicians identify patients at greater risk of diabetic
cardiovascular disease in order to prevent or delay the
onset of adverse outcomes. In the future, our model
needs to be further validated on a larger scale for its
adaptability and effectiveness in cross-hospital and
cross-disease problems to better advance the
application of Artificial Intelligence models in the
field of diabetic complication risk prediction.
ACKNOWLEDGMENTS
This work was supported by the National Key R&D
Program of China under Grant 2019YFE0190500.
ICBB 2022 - International Conference on Biotechnology and Biomedicine
474

REFERENCES
Alaa, A. M., Bolton, T., Di Angelantonio, E., Rudd, J. H.,
& Van der Schaar, M. (2019). Cardiovascular disease
risk prediction using automated machine learning: a
prospective study of 423,604 UK Biobank participants.
PloS one, 14(5), e0213653.
Baytas, I. M., Xiao, C., Zhang, X., Wang, F., Jain, A. K., &
Zhou, J. (2017, August). Patient subtyping via time-
aware LSTM networks. In Proceedings of the 23rd
ACM SIGKDD international conference on knowledge
discovery and data mining (pp. 65-74).
Bode, E. D., Mathias, K. C., Stewart, D. F., Moffatt, S. M.,
Jack, K., & Smith, D. L. (2021). Cardiovascular disease
risk factors by BMI and age in United States
firefighters. Obesity, 29(7), 1186-1194.
Conroy, R. M., Pyörälä, K., Fitzgerald, A. E., Sans, S.,
Menotti, A., De Backer, G., ... & Graham, I. M. (2003).
Estimation of ten-year risk of fatal cardiovascular
disease in Europe: the SCORE project. European heart
journal, 24(11), 987-1003.
D’Agostino Sr, R. B., Vasan, R. S., Pencina, M. J., Wolf, P.
A., Cobain, M., Massaro, J. M., & Kannel, W. B.
(2008). General cardiovascular risk profile for use in
primary care: the Framingham Heart Study.
Circulation, 117(6), 743-753.
Dinh, A., Miertschin, S., Young, A., & Mohanty, S. D.
(2019). A data-driven approach to predicting diabetes
and cardiovascular disease with machine learning.
BMC medical informatics and decision making, 19(1),
1-15.
Elley, C. R., Robinson, E., Kenealy, T., Bramley, D., &
Drury, P. L. (2010). Derivation and validation of a new
cardiovascular risk score for people with type 2
diabetes: the New Zealand diabetes cohort study.
Diabetes care, 33(6), 1347-1352.
Einarson, T. R., Acs, A., Ludwig, C., & Panton, U. H.
(2018). Prevalence of cardiovascular disease in type 2
diabetes: a systematic literature review of scientific
evidence from across the world in 2007–2017.
Cardiovascular diabetology, 17(1), 1-19.
Forbes, J. M., & Cooper, M. E. (2013). Mechanisms of
diabetic complications. Physiological reviews, 93(1),
137-188.
Grøntved A, Hu F B. Television viewing and risk of type 2
diabetes, cardiovascular disease, and all-cause
mortality: a meta-analysis[J]. Jama, 2011, 305(23):
2448-2455.
Kamal, S. A., Yin, C., Qian, B., & Zhang, P. (2020). An
interpretable risk prediction model for healthcare with
pattern attention. BMC Medical Informatics and
Decision Making, 20(11), 1-10.
Lee, W., Park, S., Joo, W., & Moon, I. C. (2018,
November). Diagnosis prediction via medical context
attention networks using deep generative modeling. In
2018 IEEE International Conference on Data Mining
(ICDM) (pp. 1104-1109). IEEE.
Mjd, A., Xin, T. B., Cow, B., Jpr, C., Akd, D., & Yuan, G.
E., et al. (2020). Time course of ldl cholesterol exposure
and cardiovascular disease event risk. Journal of the
American College of Cardiology, 76(13), 1507-1516.
Mohan, S., Thirumalai, C., & Srivastava, G. (2019).
Effective heart disease prediction using hybrid machine
learning techniques. IEEE access, 7, 81542-81554.
Strain, W. D., & Paldánius, P. M. (2018). Diabetes,
cardiovascular disease and the microcirculation.
Cardiovascular diabetology, 17(1), 1-10.
Yang, L., Wu, H., Jin, X., Zheng, P., Hu, S., Xu, X., ... &
Yan, J. (2020). Study of cardiovascular disease
prediction model based on random forest in eastern
China. Scientific reports, 10(1), 1-8.
Risk Assessment Model for Diabetic Cardiovascular Disease Via Personality and Time-Aware LSTM Network
475
