
Research on Big Data Information Processing Model of Management
Communication Under the Background of Big Data
Hongtao Mao
School of Economics and Management, Wuhan University of Engineering Science, Wuhan, Hubei, China
Keywords: Big Data Technology, Information Processing, Communication Model.
Abstract: Management under the background of big data is faced with the application of big data technology and the
change of thinking mode, and how to better integrate the two is the purpose of the research. Through the
analysis of relevant theoretical models, the qualitative method, inductive method, deductive method and
comparative analysis method are used to analyze the significance of management communication
effectiveness in the context of big data, and focus on providing the effectiveness strategy of management
communication in the context of big data. In the context of big data, the effectiveness of management
communication is not based on a simple upgrade of technology, but more based on the upgrade of
management thinking in the context of big data, with the ability of big data information processing.
1 INTRODUCTION
Big data, also known as big data, refers to the
amount of data involved that is so large that it
cannot be captured, managed, processed, and
organized into more active purposes for business
decisions within a reasonable time through
mainstream software tools. "Big data" requires new
processing models to have stronger decision-making,
insight and process optimization capabilities to
adapt to massive, high-growth and diversified
information assets. Big data requires special
techniques to efficiently handle large amounts of
data that tolerate elapsed time. Technologies for big
data, including massively parallel processing (MPP)
databases, data mining, distributed file systems,
distributed databases, cloud computing platforms,
the Internet, and scalable storage systems. Of course,
big data is a kind of appearance or feature of the
development of the Internet to the current stage,
there is no need to myth it or maintain awe of it, in
the cloud computing represented by the
technological innovation curtain, these originally
difficult to collect and use data began to be easy to
use, through the continuous innovation of all walks
of life, big data will gradually create more value for
human beings. (Huang,2022)
Management communication in the context of
big data is based on the basic knowledge of
management, mathematics and computer technology,
and the systematic use of big data management
technology and methods to communicate in the
context of big data, cloud computing, artificial
intelligence and other emerging technologies under
the background of big data storage, big data analysis
and optimization management, big data governance
and assisted decision-making. This means that
management communication in the context of big
data not only emphasizes the impact of big data
technology on modern management, but also
emphasizes the importance of big data thinking.
(Zhang, 2022)
2 THE PROCESSING PROCESS
OF BIG DATA INFORMATION
The strategic significance of big data technology is
not to master huge data information, but to
professionalize the processing of these meaningful
data. In other words, if big data is compared to an
industry, then the key to the profitability of this
industry is to improve the "processing capacity" of
data and realize the "value-added" of data through
"processing". (Liu,2021)
Technically, the relationship between big data
and cloud computing is as inseparable as the two
sides of a coin. Big data must not be processed by a
Mao, H.
Research on Big Data Information Processing Model of Management Communication Under the Background of Big Data.
DOI: 10.5220/0012074100003624
In Proceedings of the 2nd International Conference on Public Management and Big Data Analysis (PMBDA 2022), pages 299-307
ISBN: 978-989-758-658-3
Copyright
c
2023 by SCITEPRESS – Science and Technology Publications, Lda. Under CC license (CC BY-NC-ND 4.0)
299
single computer, and must adopt a distributed
architecture. It is characterized by distributed data
mining of massive amounts of data. But it must rely
on the distributed processing of cloud computing,
distributed database and cloud storage, and
virtualization technology. The term big data is
increasingly being used to describe and define the
massive amounts of data generated in the era of
information explosion, and this era of massive data
is known as the era of big data. (Xu,2022)
With the advent of the cloud era, big data has
also attracted more and more attention. Big data is
often used to describe the vast amount of
unstructured and semi-structured data created by a
company that takes too much time and money to
download into a relational database for analysis. Big
data processing generally includes four steps:
collection, import/preprocessing, statistics/analysis
and mining.
2.1 Big Data Collection
Big data collection refers to the use of multiple
databases to receive data from the client (Web, App
or sensor form, etc.), and users can use these
databases to perform simple query and processing
work.
For example, e-commerce companies use
traditional relational databases such as MySQL and
Oracle to store every transaction data, and NoSQL
databases such as Redis and MongoDB are also
commonly used for data collection.
In the process of collecting big data, its main
feature and challenge is the high number of
concurrency, because there may be thousands of
users to access and operate at the same time, such as
train ticket sales websites and Taobao, their
concurrent visits reach millions at the peak, so it is
necessary to deploy a large number of databases at
the collection end to support. And how to load
balance and shard between these databases does
require deep thinking and design. (Wang,2022)
Figure 1: Important components of Flume.
For example, Flume, a tool for data collection,
can ensure that data is delivered to the big data
platform safely and in a timely manner, no matter
what the company or how large the data comes from,
no matter what the data comes from, and users can
focus on how to understand the data. Flume supports
customizing various data senders in the logging
system for data collection. Flume provides the
ability to perform simple processing on data and
write to various data recipients.
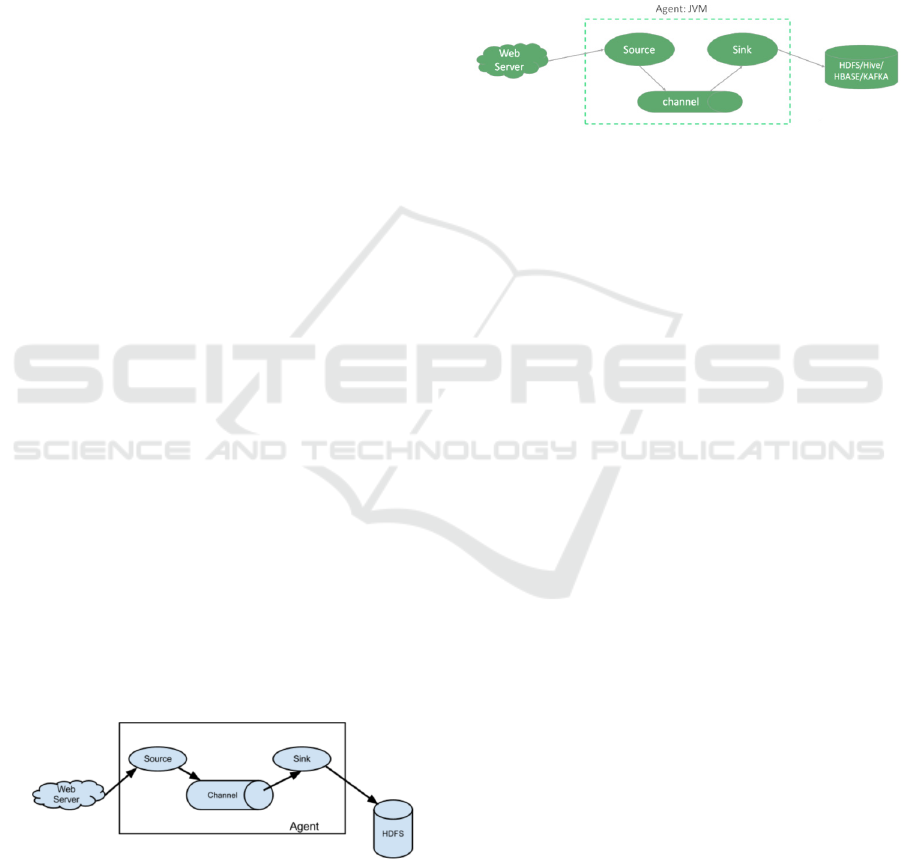
Simply put, Flume is a data acquisition engine
that collects logs in real time (Figure 1). Flume has
three important components, Source, Channel, and
Sink.
Figure 2: Flume architecture.
Components in the Flume architecture (Figure 2):
An agent is essentially a JVM process that controls
the flow of Event data from an external log producer
to a destination (or the next Agent). A completed
agent includes three components: Source, Channel,
and Sink, Source refers to the source and way of
data, Channel is a buffer pool of data, and Sink
defines the way and destination of data output.
Source is responsible for accepting data to the
Flume Agent's component, which can process
various types and formats of log data, including avro,
exec, spooldir, netcat, etc. A channel is a buffer
located between Source and Sink. Channel allows
Source and Sink to run at different rates. The
Channel is thread-safe and can handle write
operations from multiple sources and read
operations from multiple sinks at the same time.
Commonly used channels include: Memory
channels are queues in memory. Use in scenarios
where data loss is allowed. If data loss is not
allowed, you should avoid using the Memory
Channel, as program death, machine downtime, or
reboot can cause data loss. File Channel writes all
data to disk. Therefore, there is no data loss in the
event of program shutdown and machine downtime.
The sink constantly reincarnates events in the
channel and removes them in batches, and writes
these events to the storage or indexing system in
batches, or sends them to another Flume Agent.
Sinks are completely transactional. Before deleting
data from a channel in batches, each sink initiates a
transaction with the channel. Once the bulk event is
successfully written out to the storage system or the
next Flume Agent, the Sink commits the transaction
using the Channel. Once the transaction is
PMBDA 2022 - International Conference on Public Management and Big Data Analysis
300

committed, the Channel removes the event from its
own internal buffer. Sink components include hdfs,
logger, avro, file, null, HBase, message queues, etc.
An Event is the smallest unit of data streaming
defined by Flume.
2.2 Big Data Import/Preprocessing
Big data preprocessing. Although there are many
databases on the collection side itself, if you want to
effectively analyze these massive data, you should
import these data into a centralized large-scale
distributed database or distributed storage cluster,
and at the same time, complete data cleaning and
preprocessing on the basis of import. Some users
will use Storm from Twitter to stream data when
importing to meet the real-time computing needs of
some businesses.
In the real world, the data is generally
incomplete, inconsistent "dirty" data, can not be
directly data mining, or the mining results are
unsatisfactory, in order to improve the quality of
data mining, data preprocessing technology is
produced. Data preprocessing mainly includes steps
such as data cleaning, data integration, data
transformation and data reduction.
Figure 3: Big data preprocessing process.
Usually, when we get the data, it is difficult for
the data to reach our expectations, such as: missing
data, accuracy problems, too many indicators, and
so on. It always has to go through a series of
analysis, and only through data manipulation can we
get the data we want. Therefore, at this time, an
important step - data preprocessing is particularly
important. Big data preprocessing is very important,
and data quality is the life of data. Data
preprocessing is the key to data quality. The above
big data preprocessing flow chart (Figure 3) shows
that data preprocessing is mainly divided into five
steps: data exploration, data cleaning, data
integration, data specification, and data
transformation. (Wang,2022)
2.3 Big Data Statistics/Analysis
Statistics and analysis mainly use distributed
databases, or distributed computing clusters to
perform general analysis and subtotals of massive
data stored in them to meet most common analysis
needs, in this regard, some real-time requirements
will use EMC's GreenPlum, Oracle's Exadata, and
MySQL-based columnar storage Infobright, etc.,
while some batch, or semi-structured data-based
requirements can use Hadoop. The main feature and
challenge of this part of statistics and analysis is that
the amount of data involved in the analysis is large,
which will greatly occupy system resources,
especially I/O.
Figure 4: Student's t-test.
For example, the statistical method used for
evaluation, the hypothesis test, the Student's t-test
(Figure 4), assumes that the distributions of the two
populations have equal but unknown variances. And
assume that each population is normally distributed.
In this case, T (t-statistic) follows a t-distribution
with degrees of freedom (df) (n1 + n2 - 2). The
farther T from zero is to the point that it is
impossible to observe such a T-value, the greater the
difference between groups. If T is too large, the null
hypothesis will be rejected. According to the
formula, the greater the difference in the mean, the
larger the T. When the variance of the population is
larger, the smaller the T. Significance level - α:
The likelihood that the null hypothesis will be
rejected when it is actually TRUE. For a small
probability, such as α=0.05, look for the value of
T* such that P(| T| ≥ T*) = 0.05。 After sampling
and calculating the observations according to the
formula, if | T| ≥ T*, the null hypothesis (μ1 =
μ2) is rejected. A student's t-test that considers the
probability of μ1 > μ2 and μ1 < μ2 is called a
bilateral hypothesis test, and the sum of the tail
probabilities of the two t-distributions should equal
the significance level. For the most part, it is
customary to evenly divide the level of significance
between the two tails. (0.05 / 2 = 0.025) −t and t are
both t-statistically observed values. p-value: is the
sum of P(T <= -t) and P(T >= t). If the null
hypothesis is TRUE, the p-value provides the
observed | T| >= the likelihood of t. In general, the
p-value represents the probability that a sampling
result will lead to the null hypothesis. Therefore,
when p-value < significance level, the null
hypothesis can be rejected. The opposite is true.
Confidence is an interval estimate based on the
population parameters of the sample data.
Research on Big Data Information Processing Model of Management Communication Under the Background of Big Data
301

2.4 Big Data Mining
Different from the previous statistical and analysis
process, data mining generally does not have a
pre-set theme, mainly on the existing data based on
various algorithms of calculation, so as to play the
effect of prediction, so as to achieve some high-level
data analysis needs. Typical algorithms include
Kmeans for clustering, SVM for statistical learning,
and NaiveBayes for classification, and the main
tools used are Hadoop's Mahout. The characteristics
and challenges of this process are mainly that the
algorithms used for mining are complex, and the
amount of data and computation involved in the
calculation are large, and the commonly used data
mining algorithms are mainly single-threaded.
With the development of the times, the data
generated by humans has grown exponentially, and
the open application of data and the value of data
mining are getting higher and higher. Behind a series
of hot words such as big data precision marketing
and big data insight, it is data mining and analysis
technology that plays an important role. Data mining
technology has not only become an important means
for government departments to improve their
governance capabilities, but also the key to
enhancing the core competitiveness of all walks of
life. Data mining is the process of extracting hidden
information and knowledge from large, incomplete,
noisy, fuzzy, and random data that people do not
know in advance, but have potentially useful
information and knowledge (Figure 5). It can be
seen that data mining is the name of the result of a
process, that is, the main goal is to mine hidden
information from the data. It is an interdisciplinary
field of science influenced by multiple disciplines,
including database systems, statistics, machine
learning, visualization, and information science.
Figure 5: Big data mining process.
Therefore, the general process of the entire big
data processing should meet at least these four
aspects of the steps in order to be regarded as a
relatively complete big data processing.
3 THE SIGNIFICANCE OF
MANAGING
COMMUNICATION
EFFECTIVENESS IN THE
CONTEXT OF BIG DATA
John Naisbitt, a famous American futurist, once said:
"The competition of the future will be the
competition of management, and the focus of
competition is on the effective communication
between members of each social organization and
with external organizations." Indeed,
communication is the soul of management, and
effective communication determines the efficiency
of management. Through effective communication,
managers can accurately convey information such as
the organization's vision, mission, expectations and
performance to the members of the organization, so
as to more effectively implement organizational
reform, improve management functions, coordinate
the behavior of organizational members, and adapt
the organization to changes in the external
environment. In the context of big data, modern
managers attach great importance to the role of
effective communication as the key to business
success. This not only shows the important position
and role of effective communication in management
activities, but also shows that it is not easy to
achieve effective communication, and requires the
efforts and efforts of both parties involved.
3.1 It Can Promote Employees to Form
a Consensus on the Goals and
Tasks Determined by the
Enterprise
In the context of big data, enterprise managers
should let employees understand the tasks and goals
of the enterprise in a timely manner, and understand
"What is the business (task) of the enterprise?" And,
"What does the business want to become?"
Enterprise managers should listen to (collect)
employees' reasonable opinions and suggestions on
tasks and objectives, conduct timely research, and
further modify and improve enterprise tasks and
goals. Then feedback the tasks and goals of the
enterprise to employees in a timely manner. Through
such effective communication, the company's tasks
and goals are shared among all employees. This can
not only make the enterprise goals reflect the will of
all employees, but also improve the scientific
decision-making. (Bi 2019)
PMBDA 2022 - International Conference on Public Management and Big Data Analysis
302

3.2 Under the Background of Big Data,
It is Conducive to Collecting Data
and Sharing Information to
Achieve Scientific Management
In the increasingly fierce market competition, in
order to successfully achieve the goal and form a
competitive advantage, enterprises must first fully
understand all aspects of information, in order to
make scientific decisions, in order to survive and
develop in the changing environment. Effective
communication can enable enterprises to understand
various external information and intelligence, such
as national guidelines, policies, the status quo and
development trend of similar enterprises at home
and abroad, the dynamics of the consumer market,
etc., and timely adjust business decisions to adapt to
changes in the external environment; It can enable
enterprises to understand their own resource
situation and ability to use resources; Can
understand the basic situation of employees, know
people well, and improve the enthusiasm of
employees; It can gain insight into the relationship
between various departments and improve the
efficiency of management. Therefore, only by timely
and comprehensively grasping all kinds of internal
and external information, intelligence and data can
we accurately control and direct the operation of the
entire enterprise and achieve scientific and effective
management. (Liu,2022)
3.3 In the Context of Big Data, It Can
Improve the Interpersonal
Relationship of Enterprises
Effective communication within a company, whether
between departments, between departments, or
between individuals, is extremely important. In
reality, some enterprises have tense relations
between departments and between people, fierce
contradictions and internal interpersonal relationship
imbalances, and the reason is nothing more than lack
of communication or improper communication
methods. If the information communication
channels of an enterprise are not smooth, it is
difficult for people to achieve effective
communication, which will make people depressed
and depressed. In this way, it will not only affect the
mental health of employees, but also seriously affect
the normal production of enterprises and reduce the
efficiency of enterprises. Therefore, if an enterprise
wants to develop smoothly, it must ensure the
smooth flow of various communication channels
within the enterprise, left and right, only in this way
can we stimulate the morale of employees, promote
the harmony of interpersonal relationships, and
improve management efficiency. This is true (Figure
6), relationship-oriented leaders are positively
correlated with high group productivity and high
satisfaction, while work-oriented leaders are
positively correlated with low group productivity
and low satisfaction. (Qiu,2021)
Figure 6: Task relationship model.
3.4 Under the Background of Big Data,
It Can Enhance the Cohesion of
Enterprise Employees
Employee cohesion is an important asset for
enterprises. Strong cohesion indicates that the
enterprise is attractive to members, so how to
enhance the cohesion of employees? First, promote
communication and support among employees. It is
common for employees to have conflicts and
opinions in cooperation, and the key is what kind of
attitude to adopt to deal with the different opinions
between each other, and the best way is to
communicate, that is, take the initiative to exchange
their own views with each other. Second, adopt a
democratic management approach. In the process of
enterprise management, it is necessary to listen
carefully to the opinions of employees from all sides,
especially different opinions. Third, companies
should link performance and remuneration to
employees, including rewards for employees who
can work closely with others, which helps improve
employee satisfaction. Fourth, we must attach
importance to mutual trust among employees.
Promoting trust can be considered in terms of: open
communication from top to bottom and bottom up
within the organization, and the concept of honest
Research on Big Data Information Processing Model of Management Communication Under the Background of Big Data
303

communication; Involve employees in management;
Advocate employee self-management, so that
employees have a sense of trust in the enterprise and
colleagues. Fifth, carry out performance
management. The essence of the performance
management process is the communication process,
in the dynamic process assessment, creative
employees and outstanding performance employees
are rewarded; Employees with poor performance
should be adjusted in a timely manner; Penalties are
imposed for passive sabotage or disciplinary
violations. Improve the performance of each
employee through dynamic process performance
management, thereby driving the improvement of
the performance of the entire enterprise and the
achievement of corporate goals. These need to be
achieved through communication, so effective
communication can enhance employee cohesion.
4 MANAGE COMMUNICATION
EFFECTIVENESS
STRATEGIES IN THE
CONTEXT OF BIG DATA
4.1 Improve Managers' Understanding
of Big Data
In the context of big data, managers should raise
awareness of the importance of communication and
must effectively change their parent or authoritative
communication roles. Equal communication is the
foundation of good and effective communication.
Managers should not only treat subordinates equally,
but also treat themselves and subordinates equally,
and truly achieve rationality, respect and trust in
subordinates. Truly realize the one-way, top-down
communication method of the past to equal and
two-way communication, both top-down and
bottom-up communication methods. Effective
communication can only be achieved by equal and
active two-way communication. In addition, to be
fully prepared for communication, managers must
develop clear communication goals and develop a
clear communication plan before communication. At
the same time, the personnel involved in
communication are encouraged to negotiate and
collect and analyze information and materials, and
on this basis, publicity and explanation, to provide
employees with a good communication environment,
so as to fundamentally improve the efficiency of
enterprise communication, and then improve the
operational efficiency of enterprises. (Shen,2022)
4.2 Integrate Big Data Communication
Channels
In the context of big data, the integration of
communication channels is to adjust and combine
existing channels, delete some inefficient or
ineffective channels, and add some new, fast,
efficient and acceptable big data information
channels (Figure 7), while considering the
complementarity of various channels, the purpose is
to better perform communication functions and
achieve communication goals. In the process of
integration, the following principles should be
adhered to: First, the system principle. An
organization is a system, and changes or changes in
any part of the organization will have a cascading
effect on the entire system. The same is true of
communication channels, each type of
communication channel or method of
communication does not exist in isolation, there are
connections and influences between each other.
Therefore, in the process of integrating
communication channels, the connections and
influences of channels should be considered. Second,
the principle of openness. In the process of
management communication, enterprises are
required to disclose the channels of communication
for most management communication activities that
do not require confidentiality, and increase
communication channels as much as possible to
increase their awareness, transparency and openness.
In this way, communication blind spots caused by
information asymmetry can be reduced. Third, the
principle of timeliness. It is required that in the
process of communication, we must pay attention to
the saving of communication time and the
improvement of communication efficiency.
Therefore, it is necessary to choose and adopt the
shortest path to communicate as quickly as possible.
Its purpose is to increase the speed of information
transmission and reduce the possibility of
information distortion caused by layer by layer
transmission. Fourth, the principle of integrity. From
the perspective of the communication process, a
complete communication process includes the
transmission, reception and feedback of information.
The integrity principle emphasizes the integrity of
the communication process. If there are only
channels for information transmission and reception,
and no channels for information feedback, this
communication process is incomplete and its
information communication is insufficient.
Nowadays, in the process of channel integration,
PMBDA 2022 - International Conference on Public Management and Big Data Analysis
304

special attention should be paid to the correction and
supplementation of feedback channels.
Figure 7: Equal communication model.
4.3 Improve Managers'
Communication Skills in the
Context of Big Data
First, improve managers' skills in listening
effectively. In the process of communication,
managers should first concentrate and not be
absent-minded; Second, don't be preconceived,
interrupt the other person, or show impatience. This
will make the other party reluctant to continue the
communication; Finally, be empathetic, appreciate
the other person's emotional changes and unspoken
meanings, and understand the spirit. Second,
improve non-verbal communication skills. When
you are listening to the messenger, the messenger
will judge whether you are listening carefully and
truly understanding by observing your expression.
So, making eye contact with the messenger allows
you to focus, reduces the likelihood of distraction,
and can encourage the messenger. In addition,
effective listeners will express the information they
hear in non-verbal ways, such as approving nods,
puzzled head shaking, appropriate facial expressions
(such as smiling), etc., which indicate to the
messenger that you are listening carefully and
whether you understand, which is conducive to
improving communication. Third, pay attention to
emotional communication. In actual work,
communication skills are usually manifested in
whether managers can accurately describe the
current situation and prospects of enterprise
development, and let employees understand the
current situation and development strategy of the
enterprise through certain channels. The recognition
of employees is the greatest support for managers
and the most direct goal of manager communication.
The humanistic management of modern enterprises
requires managers not only to be good at correctly
using oral expression and language and writing
ability, clear expression, clear organization, concise
language and strong pertinence; Be good at listening
and paying attention, and respect the views of others;
Improve bad communication habits, properly use
expressions, movements and other non-verbal
communication methods, but also require managers
to be good at emotional communication with
employees, integrate emotions into the whole
process of management, so that employees realize
their value to the development of the enterprise, so
as to stimulate lasting work enthusiasm.
4.4 Set Up A Scientific Big Data
Organization
In the context of big data, organizational setup: On
the one hand, it is necessary to consider the excessive
organizational hierarchy caused by the organizational
scale effect, resulting in easy loss and distortion of
information, as well as the alienation effect caused
by the organization being too large, and efforts
should be made to reduce the organizational level
vertically to reduce communication links, keep
information smooth, and reduce interference, delay
and distortion. At the same time, we will broaden the
channels of information communication and promote
the exchange of information through multi-channel
communication. Horizontal exchanges and
cooperation should be strengthened between
horizontal departments, and the links between
departments and between personnel should be
strengthened; On the other hand, special
communication bodies should be set up to facilitate
communication. Although the informal
communication mechanism has a certain degree of
efficiency, it will inevitably be influenced and
constrained by the personal preferences of managers,
and greatly affect the effectiveness of communication.
Therefore, it is necessary to establish special
communication institutions to promote
communication, and to truly achieve effective
communication by institutionalizing communication.
4.5 Improve the Communication and
Feedback Mechanism in the
Context of Big Data
Communication without feedback is not a complete
communication, and complete communication must
have a perfect feedback mechanism. Otherwise, the
effectiveness of communication will be greatly
reduced. The establishment of the feedback
mechanism should first start with the sender of the
information, and the sender should obtain feedback
information by asking questions and encouraging
the recipient to give positive feedback after
B
C
D
E
A
Research on Big Data Information Processing Model of Management Communication Under the Background of Big Data
305

transmitting the information. In addition, the sender
should also carefully observe the reaction or action
of the other party to obtain feedback indirectly.
Because feedback can be intentional or unintentional.
As the recipient of information, it is actually in the
subject position in the communication feedback. In
the context of big data, the information transmitter
should actively accept the feedback from the
recipient, so that organizational communication
becomes a two-way communication in the true
sense.
4.6 Learn to Think Differently Based
On Big Data
In the context of big data, the most important
communication strategy is empathy. People within
an organization often have different backgrounds,
values, and conflicts of all kinds. People will also
process and choose information for the following
reasons, one is that the information is not harmful or
good to me, and the other is to transform it into what
I like to hear. Therefore, the internal information
changes its taste after layer by layer transmission,
which is the obstacle and risk of internal
communication within the organization. The
solution is to think from the other party's point of
view, that is, "empathy", to take the initiative to
think about the other party's thoughts, opinions,
emotions, attitudes, that is, how he thinks about this
problem. We must let empathy permeate the specific
strategy of communication, that is, transposition in
the organization of information; transposition
yourself in your own self-positioning; Consider how
to take care of each other's emotions. (
Zhao,2022)
5 CONCLUSIONS
At present, the downstream application fields of
China's big data industry are very extensive,
involving almost all fields of our daily life.
According to the data, the top three applications of
China's big data industry are finance, medical health
and government affairs, accounting for 30%, 14%
and 13% respectively (Figure 8).With the rapid
development of information technology, we have
entered the era of information explosion
characterized by "big data, Internet of Things, cloud
computing and mobile Internet". In business,
economics and beyond, decision-making is
increasingly based on data and analysis rather than
experience and intuition. As a prerequisite for
operational decision-making, big data has become
the basis for influencing the government and
enterprises to make major decisions such as
investment analysis, credit financing, enterprise
operation and management, and corporate strategic
planning, and playing an increasingly important role
in promoting high-quality economic and social
development. In the future, business intelligent
decision-making, building a smart government,
building a smart city, and developing a smart society
will all be related to big data, and management
(communication) talents who understand big data
and have big data thinking will be the bridge
connecting business and technology, and will be the
intelligent hub of data-driven enterprises.
Figure 8: Big data application statistics in 2020.
In the era of big data, technology continues to
iteratively upgrade, market competition is becoming
increasingly fierce, cooperation and communication
with all parties has become a regular activity of
enterprises, the success of cooperation depends on
the effectiveness of communication, rather than
simply relying on the application of big data
technology, therefore, communication should
become one of the basic skills that managers must
master. Based on the background of big data, the
strategy of communication subject positioning
should take into account elements such as integrity
ethics and active listening, although the
technological development of big data has a great
impact, but sincerity and credibility are the most
effective constructive communication weapons,
integrity is the character of leaders, integrity is the
source of leadership. In the context of big data,
active listening means recognizing the importance of
two-way communication, listening from the position
of affirming the other party, overcoming a priori
consciousness and mental model, and giving the
other party a timely and appropriate response. In this
way, our communication and management will reap
joy.
30%
27%
14%
13%
8%
8%
Finance Other Healthcare
PMBDA 2022 - International Conference on Public Management and Big Data Analysis
306

ACKNOWLEDGEMENT
This article is a paper on the effectiveness of
management communication in the context of big
data. I would like to thank all the companies we
visited for the valuable experience they shared. At
the same time, thanks to the valuable research
results of the reference author of this article.
REFERENCES
Bi Yuhai. How to improve the effectiveness of internal
management communication[J]. Business News,
2019(16): 43-44.
Huang Baoling. Research on public management
innovation path in the era of big data[J]. Industry and
Technology Forum,2022,21(17):281-282.
Liu Shuai. Discussion on management communication
problems and countermeasures of Chinese
enterprises[J]. Time-honored Brand Marketing,
2022(22): 133-135.
Liu Siyang. Application of big data in management
information system[J]. Data, 2021(11):59-61.
Qiu Shanshan. Modern Marketing (Business Edition),
2021(11): 178-180.
Shen Fenglei. Research on enterprise management
communication problems and countermeasures[J].
Shopping Mall Modernization, 2022(09):91-93.
Wang Hua. Data storage and management based on big
data framework[J]. Information Recording Materials,
2022,23(08):189-191.
Xu Guohu, Xue Gaigai. Research on the Impact of Big
Data Management on Enterprise Agility--The
Moderating Effect of Enterprise Strategy and
Environmental Uncertainty[J]. Journal of Hubei
University of Science and Technology, 2022,
42(06):1-8.
Zhang Qiongqiong. Thinking on the business
administration mode of enterprises in the era of big
data [J]. Modern Industrial Economics and
Informatization,2022,12(06):200-201.
Zhao Linlin. Public management under the new normal:
dilemma and way out[J]. China Collective Economy,
2022(32):49-51.
Research on Big Data Information Processing Model of Management Communication Under the Background of Big Data
307
